TokenPilot:让 LLM Agent 长会话成本降 60%+ 的上下文管理
今天解读的这篇论文叫 TokenPilot: Cache-Efficient Context Management for LLM Agents,作者来自浙江大学、电子科技大学、西安电子科技大学和 HomologyAI。
这篇论文讨论的是 Agent 长任务里的上下文管理:当历史内容不断累积时,系统如何在减少冗余 token 的同时,尽量维持 prompt cache 的稳定命中。
目前,很多上下文管理方法都会先从历史内容入手,通过删除、总结或压缩来减少输入 token。但在 Agent 场景里,这类操作也可能改变 prompt prefix 的结构,让原本可以复用的缓存失效。
TokenPilot 的核心思路是,把上下文管理和缓存命中率放在一起考虑:一边减少冗余内容,一边尽量维持稳定的上下文布局。
Agent 长任务中的上下文成本与缓存冲突
Agent 和普通聊天助手的一个重要差异在于,它会持续执行任务,并在执行过程中不断积累操作记录。一个代码 Agent 会先读项目目录结构,再打开多个源码文件,然后跑测试、查看报错、修改代码,最后再次执行命令。Coding Agent 的每一步操作都会产生新的上下文内容,这些内容会进入后续任务请求的 prompt 中,参与模型推理。这就导致了任务跑得越久,输入 token 就越多,推理成本也会随之增加。
之前很多上下文管理方法关注文本层面的压缩,比如截断长日志、把网页内容压缩成摘要,或是把旧任务轨迹移出上下文。上面这些方法,是可以在一定程度减少输入 token,但 TokenPilot 指出,在 Agent 场景里,这类操作也可能改变 prompt prefix 的结构,让原本可以复用的缓存失效。
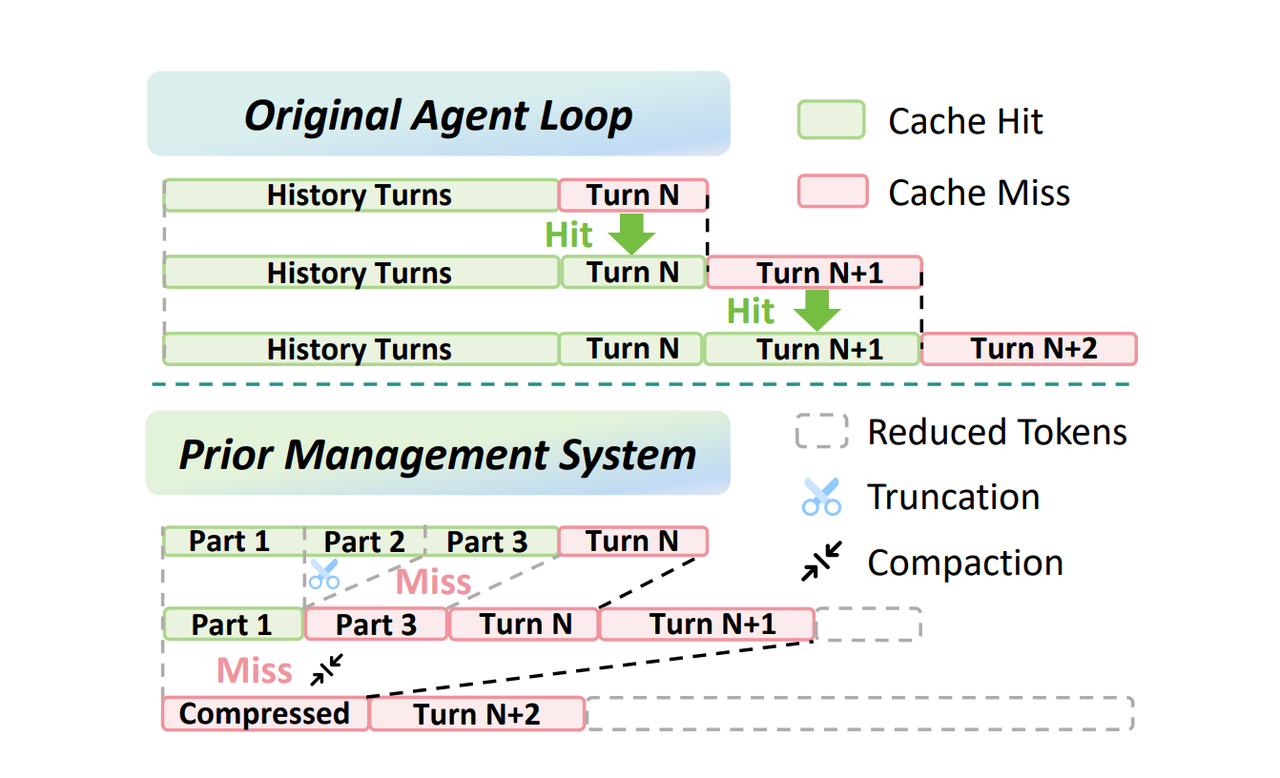
图 1:缓存对齐行为对比。
这张图要说明的是,prompt cache 的收益很依赖上下文前缀的稳定性。现在大多数的模型服务会对 prompt prefix 做缓存,如果后续请求的前缀和之前保持一致,就可以复用已经计算过的 KV cache,从而降低 prefill 成本。
但在 Agent 场景里,上下文管理经常会对历史内容做删除、移动或压缩。虽然这些操作可以减少 token 数量,却也可能改变原本连续的输入布局。一旦 prefix 结构发生变化,原本可以命中的缓存就会失效,后续请求反而需要重新计算更多内容。
所以,TokenPilot 关注的核心矛盾是:上下文需要压缩,避免 token 持续膨胀;上下文结构也需要尽量稳定,避免 prompt cache 被频繁打碎。
这也是这篇论文比较有工程价值的地方:它把上下文管理从文本压缩,推进到了运行时布局管理。上下文内容怎么组织、怎么保留、什么时候清理,都会直接影响 prompt cache 的命中率。
TokenPilot 的整体设计
TokenPilot 的整体设计围绕两个模块展开。第一个模块是 Ingestion-Aware Compaction,负责在外部内容进入上下文之前先做一层处理,把工具返回、网页内容、日志输出这类信息变得更紧凑,也更稳定。第二个模块是 Lifecycle-Aware Eviction,负责在任务执行过程中判断历史片段的状态,决定哪些内容仍然需要保留,哪些内容可以清理。
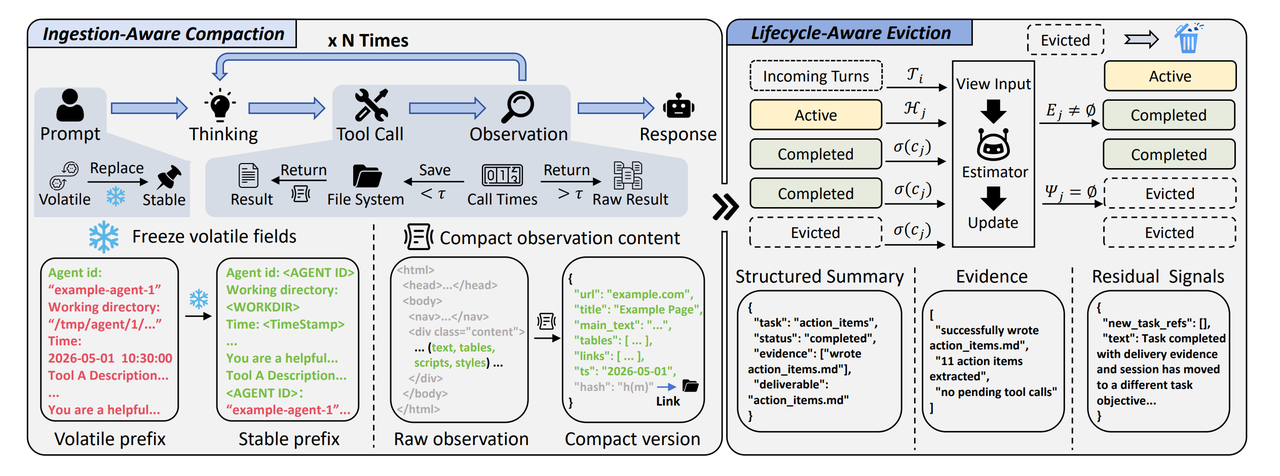
图 2:TokenPilot 架构图
从图 2 可以看出,TokenPilot 在两个位置介入 Agent 的上下文管理:一个是内容进入上下文之前,尽量减少冗余和动态变化;另一个是内容进入上下文之后,根据任务的生命周期来管理历史信息。前者解决的是“输入内容如何更紧凑、更稳定”,后者解决的是“历史片段什么时候还有用、什么时候可以退出上下文”。
Ingestion-Aware Compaction
你可以把 Ingestion-Aware Compaction 理解为“入口处压缩”:在外部内容真正进入上下文之前,TokenPilot 会先做一层结构化处理。Agent 调用工具后,往往会收到网页 HTML、文件内容、命令行输出、日志、表格和链接等反馈,其中很多内容都带有噪声。比如,网页 HTML 里常见的导航栏、脚本、样式、重复标签,对任务本身不一定有帮助,却一定会占用上下文窗口,并增加后续推理成本。
TokenPilot 会先保留页面标题、正文、表格、链接和必要元数据等高价值信息,再把冗余结构压掉。同时,它还会处理 agent id、工作目录、时间戳、临时路径这类动态字段。这些字段本身可能很短,但只要每次执行时发生变化,就可能会打破 prompt prefix 的连续性。TokenPilot 会把这些动态字段替换成稳定占位符,让 prompt prefix 的内容和顺序尽量保持稳定,从而提高缓存复用率,减少重复 prefill 的开销。
这一步的关键在于,压缩发生在内容进入上下文之前。相比等上下文形成后再反复删除和移动历史内容,入口处处理可以让上下文从一开始就更紧凑、更稳定,也更有利于后续 prompt cache 的复用。
Artifact Registry 与内容恢复机制
TokenPilot 还有一个比较实用的设计,就是不简单丢弃所有原始内容。
对于被压缩的工具调用结果,它会把完整内容存进外部 artifact registry,并用 hash 做索引。而真正进入上下文的是压缩后的结构化版本。这样,Agent 平时只需要读取更轻量、更高价值的内容,以此来减少上下文成本;如果压缩版本缺少关键细节,也能通过恢复工具来找回原始内容。
这个设计相当于给压缩过程加了一层安全阀。Agent 处理的外部内容很难提前就判断其价值,某些日志、网页字段或文件片段一开始看起来无关,后面却可能成为关键线索。把原始内容留在外部存储,既可以让上下文保持轻量,又能保留必要时回溯完整信息的能力。
Lifecycle-Aware Eviction
TokenPilot 的第二个模块是 Lifecycle-Aware Eviction。
Lifecycle-Aware Eviction 处理的是历史内容的清理时机。很多上下文管理方法会在子任务完成后很快移除相关历史,但在连续任务里,那些已经完成的任务往往会留下残余价值。
举个例子,Agent 先读取 transcript.md 生成会议摘要,接着用户又让它提取 Q&A、整理建议、查找数据来源。第一个生成摘要任务虽然结束了,但 transcript.md 的结构、人物信息和章节位置,仍然能帮助后续任务更快地定位内容。如果这部分历史被过早清理,Agent 可能就需要重新读取同一份文件,重复前面的探索过程。
因此,TokenPilot 给上下文片段设计了三个生命周期状态:active 表示这个片段仍然服务于当前任务,需要继续保留在上下文中;completed 表示对应子任务已经完成,但内容仍可能对后续任务有残余价值;evictable 表示片段的任务价值已经消失,可以从上下文中清理。
其中,completed 是最关键的缓冲状态。它让系统在“任务完成”和“立即清理”之间多了一层判断:只要片段还可能被后续任务引用,就先保留在上下文里,避免 Agent 在后续步骤中反复读取同一批内容。
保守的批量清理策略
Lifecycle-Aware Eviction 的清理节奏相对保守。TokenPilot 会用一个在线 estimator 判断上下文片段的状态,但不会在每一步都触发大规模清理。论文提到,它采用 batch-turn schedule,就是在相对稳定的批次中集中判断和清理上下文。
这样做是为了维持缓存稳定性。如果每一轮都频繁调整上下文,输入布局就会持续变化,即使 token 数量减少,也可能带来新的缓存未命中。TokenPilot 选择用更保守的清理节奏来减少这种扰动,目的是在长时间运行中能获得更稳定的整体成本。
实验设置与主要结果
论文在 PinchBench 和 Claw-Eval 两个 Agent benchmark 上对 TokenPilot 进行了评估,并设置了两种测试模式。第一种是 isolated mode,每个任务结束后上下文会被重置,更接近单任务评估;第二种是 continuous mode,多个任务在同一个连续会话里执行,历史会跨任务保留,这会更接近真实的 Agent 使用方式。
论文把 TokenPilot 与多种上下文管理方法进行了比较,包括 Vanilla、LLMLingua-2、SelectiveContext、LCM、Pichay、Summary、MemoBrain、AgentSwing、Keep-Last-N 和 MemOS。
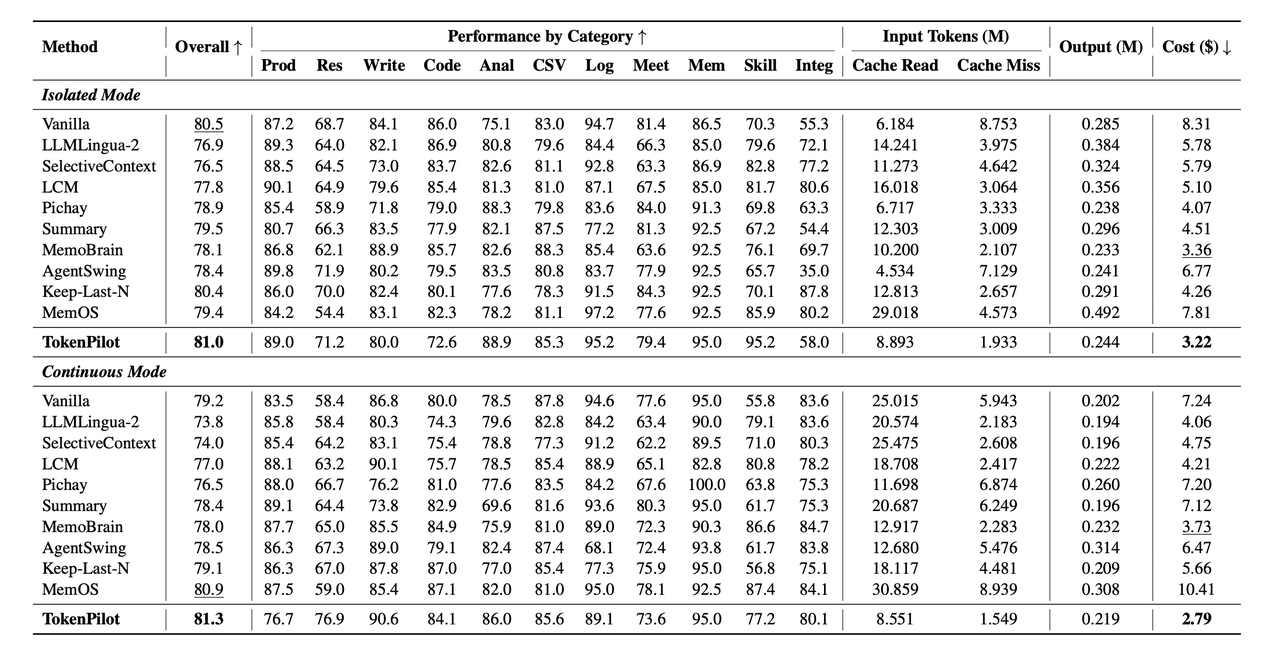
表 1:PinchBench 结果
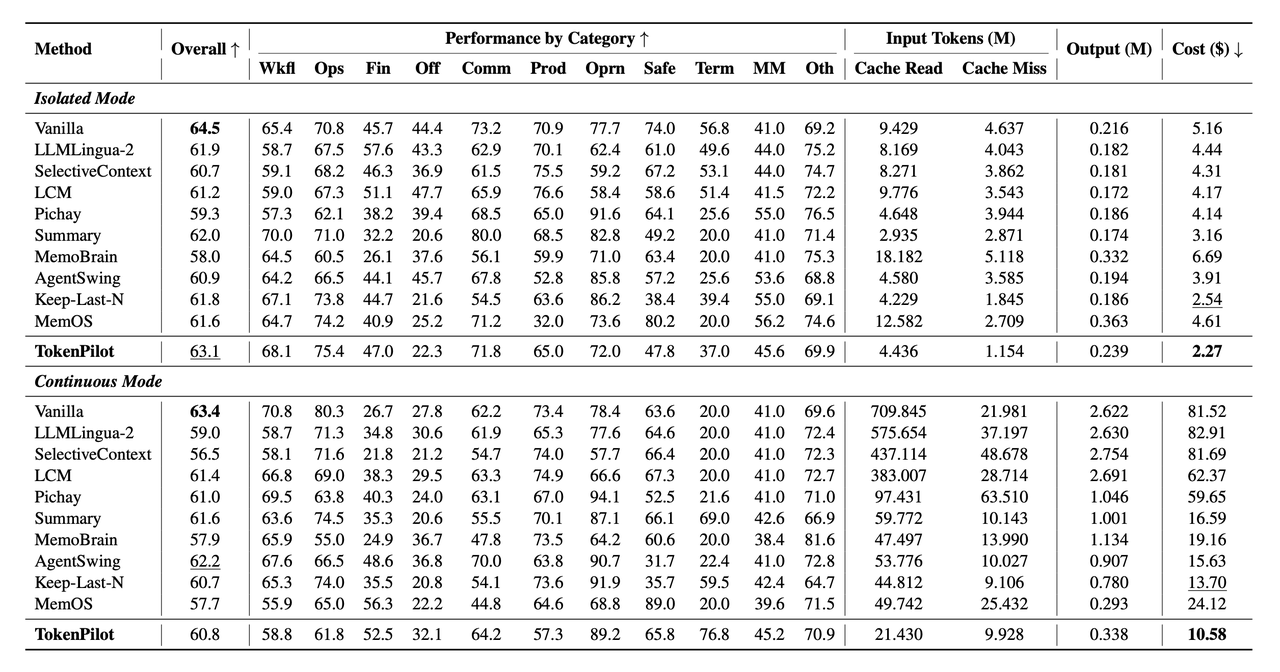
表 2:Claw-Eval 结果
从表 1 和表 2 可以看到,TokenPilot 的成本优势在两个 benchmark 上都比较明显,尤其是在 continuous mode 里。在 PinchBench continuous mode 中,Vanilla 的成本是 7.24 美元,TokenPilot 降到 2.79 美元,同时总体分数从 79.2 提升到 81.3。在 Claw-Eval continuous mode 中,Vanilla 的成本达到 81.52 美元,TokenPilot 降到 10.58 美。虽然 TokenPilot 的总体分数是 60.8,低于 Vanilla 的 63.4,但仍高于多数组上下文管理基线。在 isolated mode 下,我们也能看到类似趋势:PinchBench 中 TokenPilot 将成本从 2.80 美元降到 1.09 美元;Claw-Eval 中,则从 5.16 美元降到 2.27 美元。
我们可以从部署角度来理解这组结果。TokenPilot 的重点不是把单项任务分数推到最高,而是在长任务和连续任务里,把推理成本控制到更可持续的水平,同时保持有竞争力的任务表现。尤其是 continuous mode,它更接近真实 Agent 使用方式,也更能体现它对长会话成本的控制能力。
消融实验与上下文变化
论文还通过消融实验拆解了两个模块各自带来的影响。
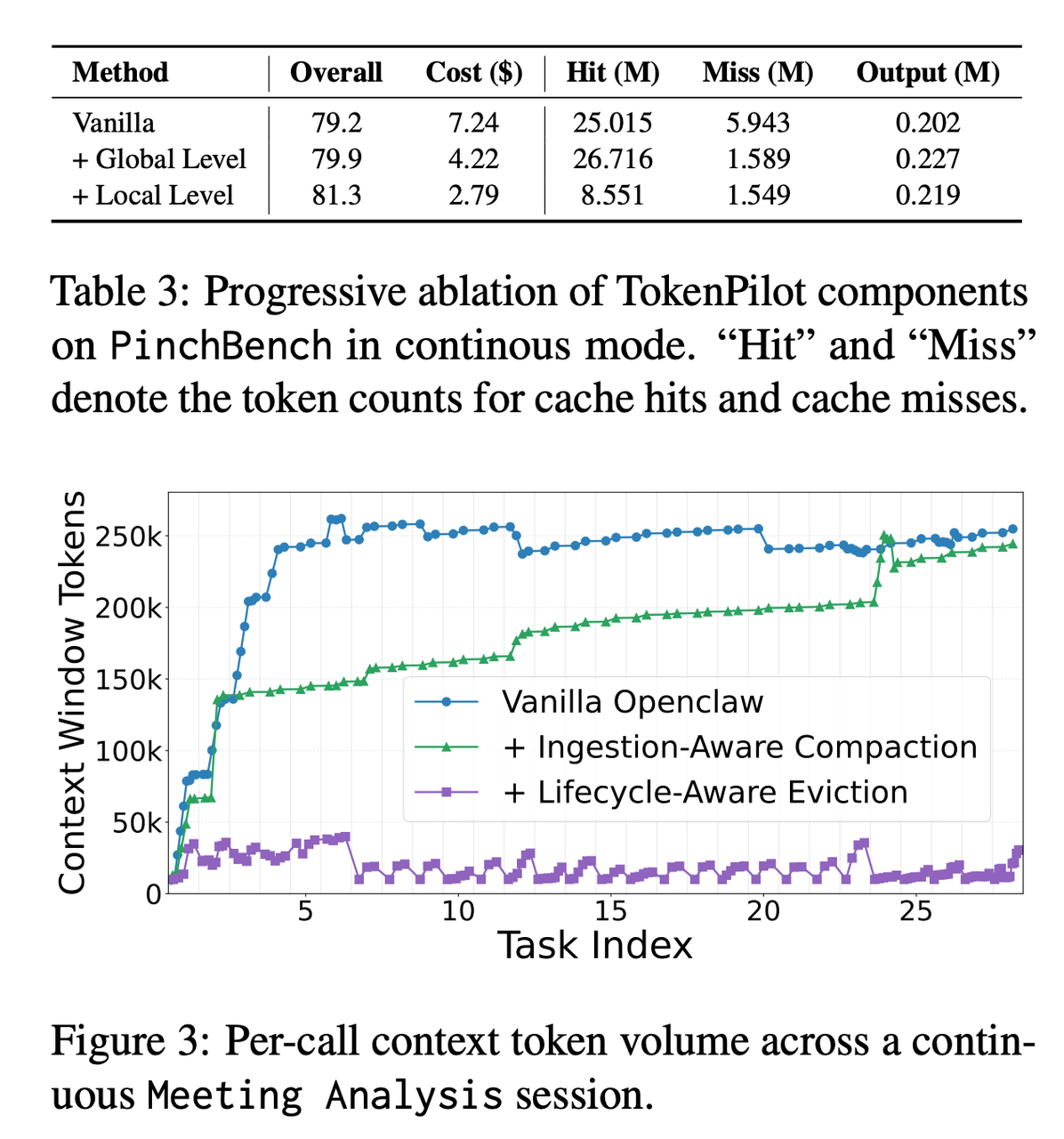
表 3:TokenPilot 的消融实验表
在 PinchBench continuous mode 下,Vanilla 的总体分数是 79.2,成本是 7.24 美元;加入 Global Level 后,成本降到 4.22 美元;继续加入 Local Level,也就是完整 TokenPilot 后,总体分数达到 81.3,成本进一步降到 2.79 美元。
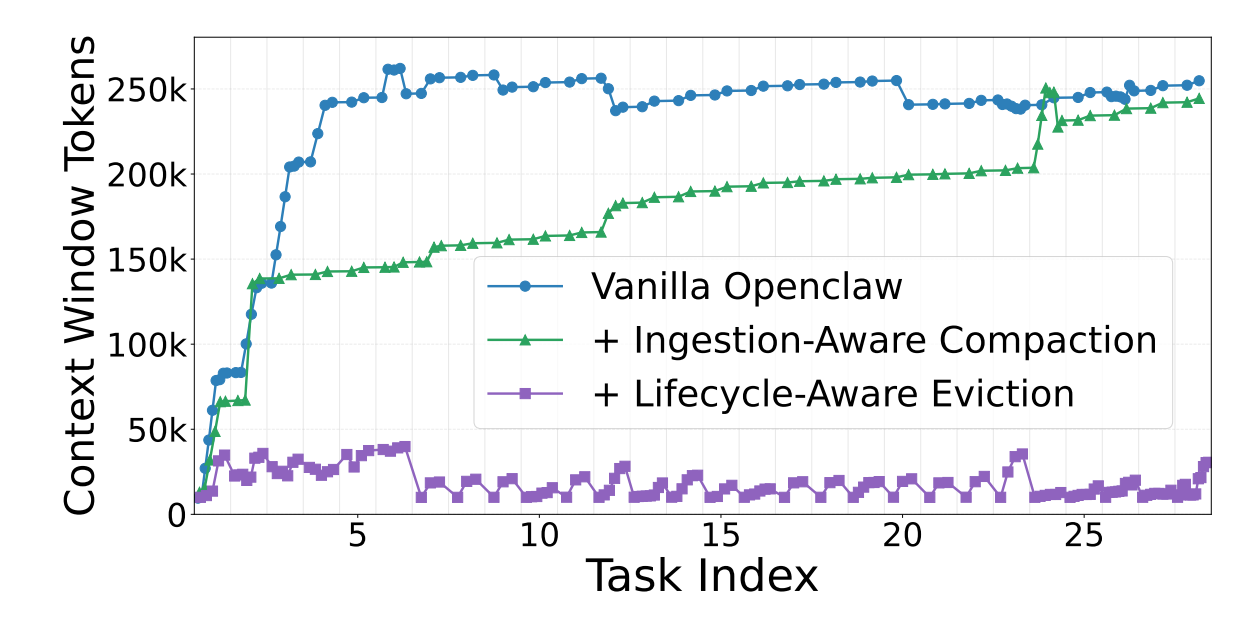
图 3:连续任务中的上下文 token 变化
图 3 显示了一个会议分析连续会话中的上下文窗口变化。Vanilla 的上下文 token 数(蓝线)会快速爬升,并长期维持在较高水平;加入 Ingestion-Aware Compaction 后(绿线),上下文增长变慢;再加入 Lifecycle-Aware Eviction 后(紫线),上下文窗口进一步下降,整体波动也更低。
这说明两个模块分工不同:入口处压缩主要减少外部观察内容里的冗余,生命周期清理则主要控制长期会话中的历史积累。
论文还通过图 4 和图 5 补充验证了两个细节。
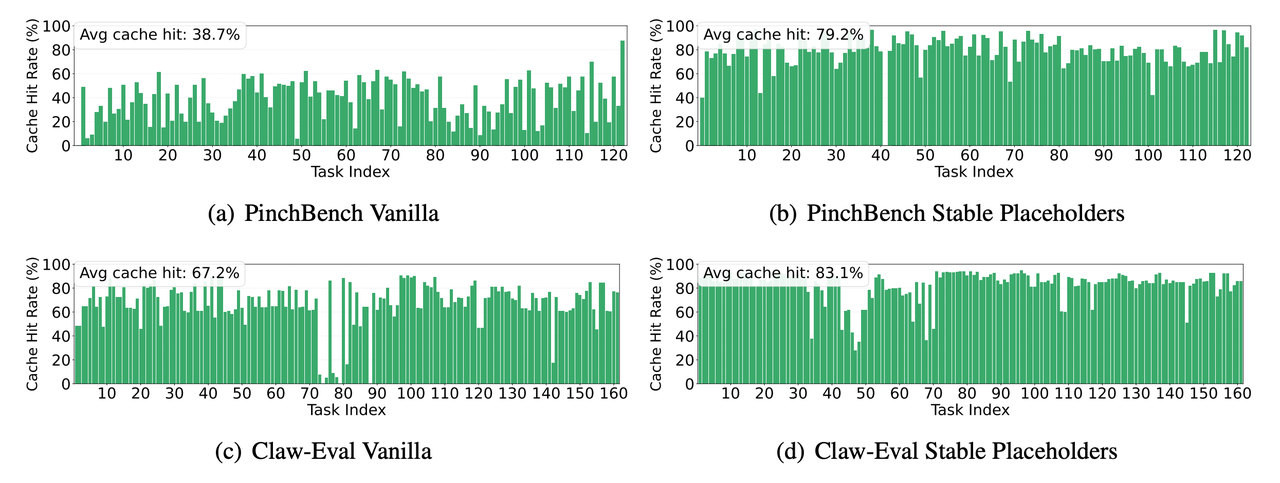
图 4:PinchBench 和 Claw-Eval 上的单任务缓存命中率
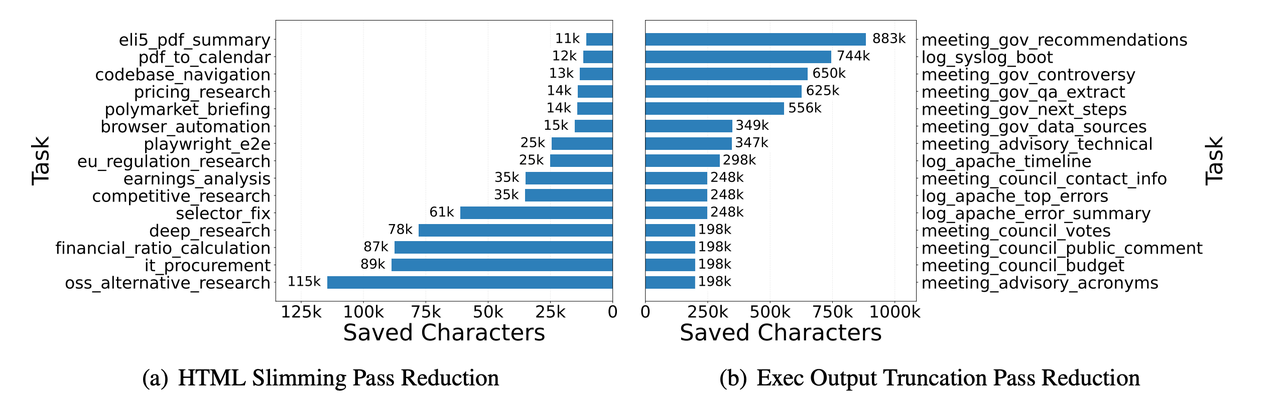
图 5:不同任务中压缩步骤带来的字符节省
图 4 对比了不同设置下的单任务缓存命中率。使用稳定占位符后,PinchBench 和 Claw-Eval 上的平均缓存命中率都有明显提升。图 5 展示了不同任务中,压缩处理步骤带来的字符节省。其中,HTML 精简和执行输出截断在部分任务中效果很明显,说明外部工具调用结果里确实存在大量可以压缩的结构噪声。
这部分实验支撑了 TokenPilot 的两个基本判断:动态字段稳定化有利于提升缓存命中,工具调用结果中也存在大量可压缩空间。两者结合起来,就构成了 Ingestion-Aware Compaction 的工程基础。
连续任务案例
论文里还有一个更直观的案例,就是用 transcript.md 展示残余价值评估(residual utility estimation)的作用。这个例子包含四个连续任务:生成摘要、提取 Q&A、整理建议、查找数据来源。它们都围绕同一份 transcript.md 展开。
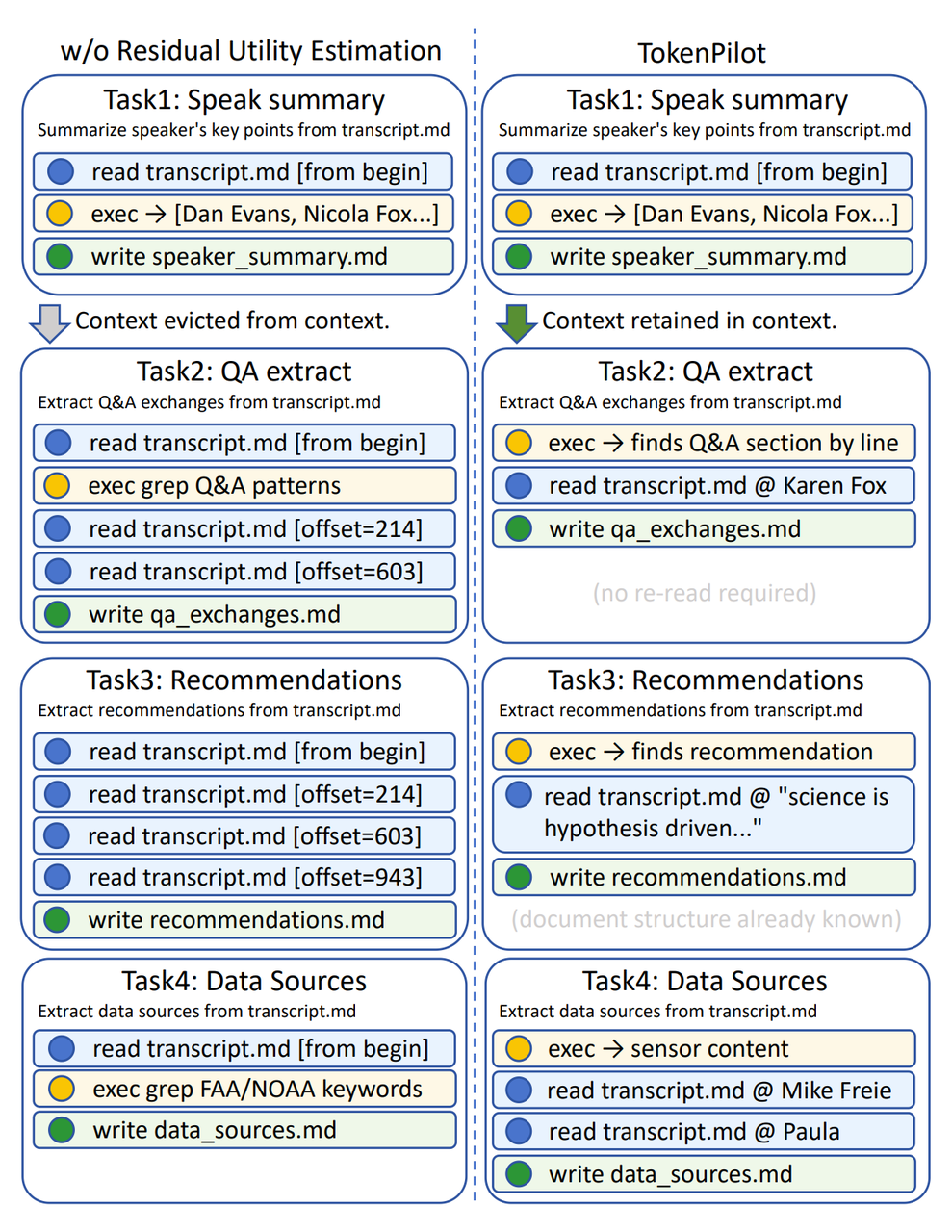
图 7:transcript.md 四任务连续流程
在没有残余价值评估的变体(虚线左侧)里,系统会在任务完成后更快清理相关上下文。后续任务到来时,Agent 得重新读取 transcript.md,并多次按 offset 局部读取文件,重新寻找相关内容。而有残余价值评估的 TokenPilot 会把已经完成但仍有残余价值的内容继续保留在上下文中,以便让后续任务可以直接利用人物段落、建议内容或数据来源线索,从而减少重复读取和重新探索。
这个例子说明,completed 状态不只是一个中间标签,它真正解决的是连续任务里的历史复用问题。很多任务在形式上已经完成,但它们留下来的结构信息、路径信息和文件定位信息,对后续操作仍然有价值。TokenPilot 通过延迟清理这类内容,避免 Agent 在连续任务中反复回到同一份材料重新定位。
局限性和前提
TokenPilot 的收益依赖一些前提。
首先,它需要后端支持 prefix caching。如果模型服务本身没有相关缓存机制,前缀稳定化(prefix stabilization)带来的收益会明显下降。其次,Lifecycle-Aware Eviction 依赖 estimator 判断片段状态,如果任务信号不清晰、上下文之间的依赖关系较弱,系统可能误判某些片段的残余价值。
另外,batch size 和频率阈值也要根据部署环境调参。不同模型服务的缓存策略、价格结构、任务长度和工具调用模式都可能影响最优参数。在论文,continuous mode 会把同类别任务组织在一起。但在真实使用中,用户的任务可能更混杂。如果任务频繁切换主题、工具 schema 和上下文结构,缓存复用率也可能下降。
论文价值与小结
TokenPilot 的价值在于,它把 Agent 上下文管理从文本压缩推进到了缓存友好型上下文管理。之前谈上下文优化,重点一般是哪些内容保留、哪些内容删除、哪些历史总结;TokenPilot 增加了一个更工程化的视角:内容在上下文里的组织方式,也会影响推理成本。
当模型服务支持 prompt cache 时,稳定的 prefix 本身就是一种可以复用的计算资源。上下文管理系统如果频繁改变历史结构,就可能降低缓存命中率。这样一来,即使 token 数下降,整体成本也未必达到理想状态。Agent 的成本优化不能只看上下文长度,还要看上下文是否稳定、是否可复用、是否适合缓存命中。
TokenPilot 的思路可以概括为两点:在外部内容进入上下文之前,先去掉结构噪声,并稳定动态字段,让 prompt prefix 更适合缓存复用;在历史内容清理时,考虑任务生命周期和残余价值,减少过早清理带来的重复读取和缓存扰动。
它给 Agent 上下文管理提供的启发很直接:长任务里的成本优化,不能只看 token 数量,还要看上下文是否稳定、是否能够持续复用缓存。
原文地址: http://www.cveoy.top/t/topic/qGWT 著作权归作者所有。请勿转载和采集!