MTTR 降不下来,真的是工具问题吗?
故障现场通常不是缺信息。
监控平台在闪红,日志平台能搜到错误,链路图上有一段变慢,群里有人贴截图,也有人问“谁在看”。问题是,十几分钟过去,大家仍然在确认同一件事:这到底是不是故障?影响哪些业务?谁来牵头?要不要升级?有没有人能联系到那个服务的负责人?
很多团队复盘时会说:MTTR 还是太高,工具要再升级。
这句话只说对了一半。工具当然重要。没有可观测数据、没有告警路由、没有通知触达、没有作战室记录,故障响应只能靠人肉。但 MTTR 从来不是一个监控平台单独产出的指标,它是组织协作的结果。发现晚、分派慢、影响面不清、跨团队等待、复盘不落地,都会把恢复时间一点点拉长。
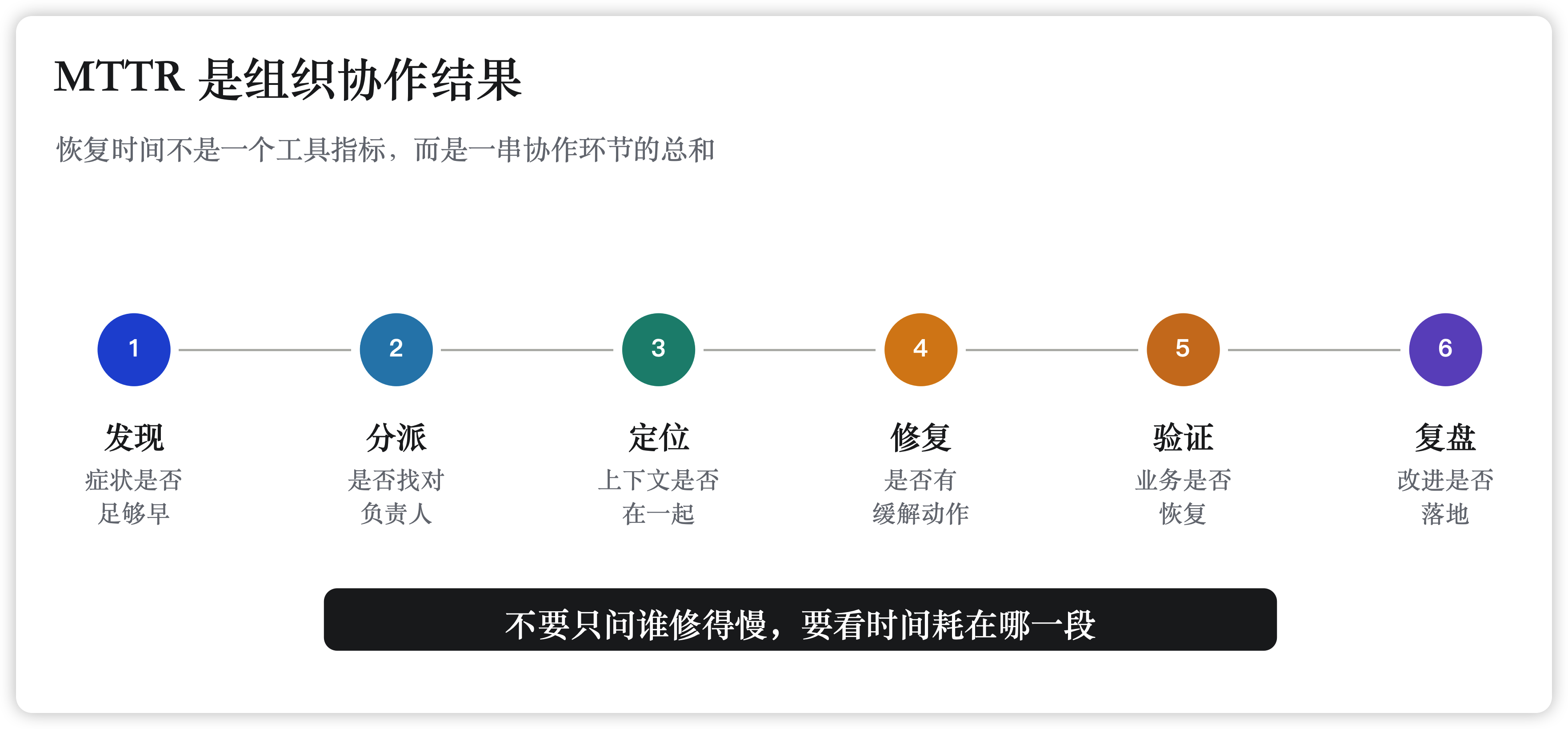
先把 MTTR 拆开
MTTR 看起来是“从故障发生到恢复”的一段时间,但真正可管理的是里面的几段:
- 发现:系统什么时候知道异常,而不是客户、门店或业务方先知道。
- 分派:告警是否打到正确的人,有没有人明确认领。
- 定位:值班人能不能快速看到指标、日志、链路、事件、变更和业务影响。
- 修复:需要哪些团队、供应商或负责人参与,是否有临时缓解手段。
- 验证:技术指标恢复后,业务指标是否也恢复。
- 复盘:这次浪费的时间,下次能不能少浪费。
如果只盯着最后的恢复时间,团队很容易得出粗糙结论:工程师不够熟、系统太复杂、工具不好用。更有效的做法是把最近一次故障按时间线拆开,看每一段到底卡在哪里。
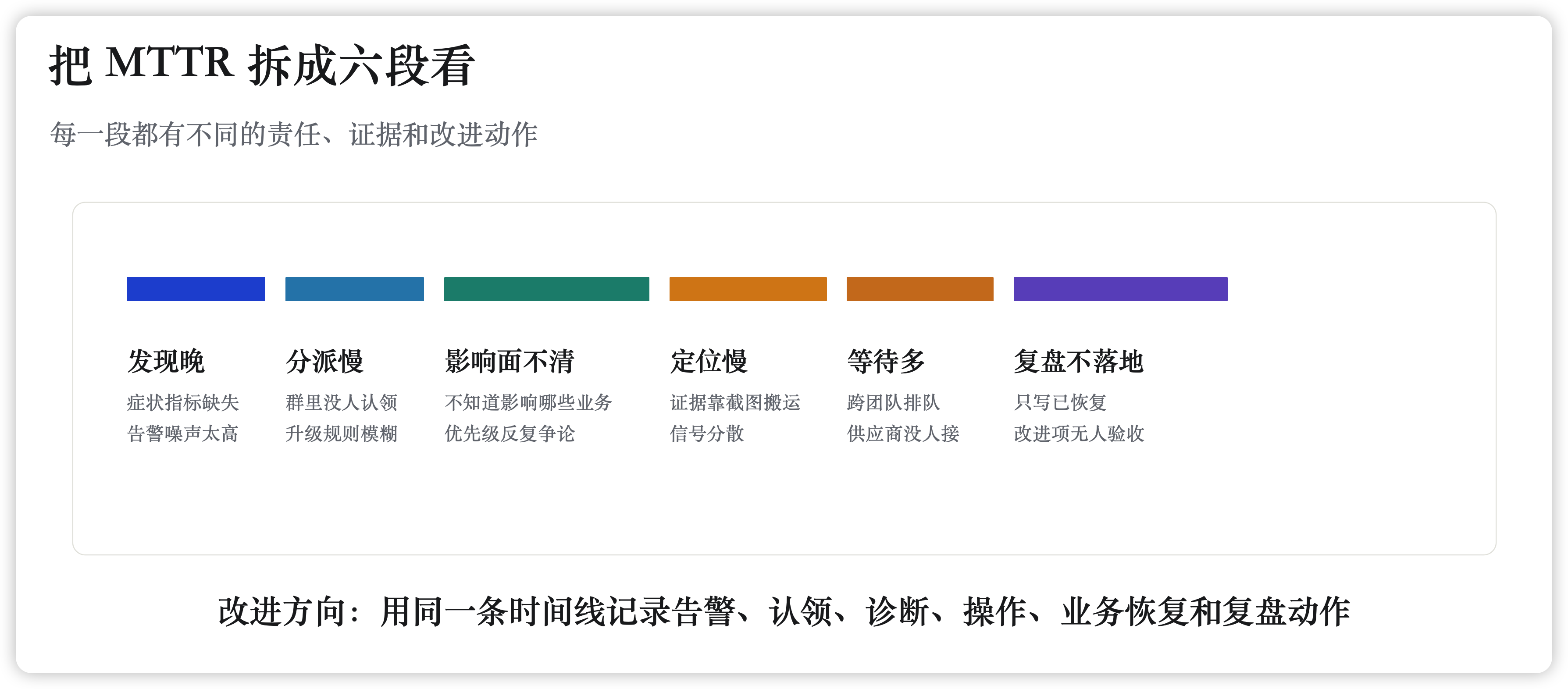
第一类耗时:发现晚
最尴尬的故障,不是系统坏了,而是业务已经受影响,技术团队还不知道。
Google SRE 在监控章节里强调,告警应该服务于人的行动:当系统无法自动修复时,人才需要被叫醒,去判断、缓解和找根因。它还特别提醒,频繁、低质量的告警会让人开始忽略真正重要的告警。
这对企业 IT 很现实。很多团队已经有 Zabbix、Prometheus、Grafana、云监控、日志平台,也有一堆 CPU、内存、端口、错误日志告警。但业务最先感知的往往不是这些底层指标,而是支付失败、订单变慢、登录异常、库存不同步、报表延迟、某个区域访问质量下降。
发现晚,不一定是没有监控。更常见的是监控没有对准业务症状,或者告警噪声太大,真正需要处理的信号被淹没了。
Flashcat 的价值在这里不是“再加一块大屏”,而是把存量监控、指标、日志、链路、事件和业务健康视图放到同一个排障上下文里。Flashduty 接住告警之后,再做聚合、降噪、分级和路由,让告警从“有人看见”变成“正确的人必须处理”。
第二类耗时:分派慢
很多故障不是没人收到,而是所有人都收到了。
群里一条告警被机器人推出来,十几个人在线,几个人分别贴了不同系统的截图。看上去很热闹,但没人认领。五分钟后有人问“这个谁负责”,又过几分钟才发现值班人今天换班了,服务负责人在另一个群,供应商联系人还要翻通讯录。
这段时间不会出现在 CPU 图上,但会结结实实地进 MTTR。
分派慢的本质,是责任路径不清。谁值班、谁主责、多久无人响应要升级、影响扩大时通知谁、跨团队谁做现场指挥,这些不能靠临场猜。
On-call 平台的意义也不只是“电话短信通知”。Flashduty 文档里把告警接入、路由分派、降噪、通知触达、认领处理放在同一条工作流里,这正是 MTTR 管理需要的数据:谁收到了,谁认领了,什么时候升级,什么时候关闭。
第三类耗时:影响面不清
故障处理现场最消耗管理层耐心的问题是:到底影响多大?
如果只说“某服务异常”,业务负责人无法判断要不要公告,研发负责人无法判断要不要停发布,运维负责人无法判断要不要扩大响应,CIO 也无法判断这是不是一件需要进入重大事件管理的事。
影响面不清,会让团队在优先级上反复拉扯。一个接口错误率升高,如果集中在核心交易链路、高峰时段或关键区域,就不是普通技术告警。反过来,一个底层组件告警,如果没有造成业务症状,也不应该让全员深夜起床。
所以复盘模板里一定要记录影响范围:哪些系统、哪些区域、哪些客户或门店、哪些业务动作、是否有绕行方案、恢复后由什么业务指标验证。MTTR 的“R”不是服务进程起来了,而是业务恢复到可接受状态。
第四类耗时:跨团队等待
现代故障很少只属于一个团队。
一次慢查询可能牵出数据库、应用、缓存、网关和最近一次发布;一次支付失败可能牵出门店网络、第三方通道、收银系统和总部服务;一次容量问题可能牵出业务活动、资源配额、发布节奏和成本策略。
如果证据分散在多个工具里,协作就会变成“你去查一下”“我截图给你”“等某某上线”。等待不是因为大家不努力,而是因为上下文没有被整理出来,现场没有一个共同事实源。
这也是 AI SRE 更适合承担的第一件事:不是替代 SRE 拍板,而是在故障刚进入作战室时,先带着告警上下文收集指标、日志、变更、知识库和 runbook,给出第一轮证据整理。Flashduty 的 AI SRE 能从故障或作战室拉起会话,也能在 IM 里参与排障。把重复查询、复制粘贴和信息汇总交给 Agent,人再判断取舍,跨团队协作会少很多空转。
第五类耗时:复盘不落地
最浪费的 MTTR,是每次都浪费在同一个地方。
Atlassian 的故障复盘资料强调,好的复盘报告要有一致的问题框架、足够具体的数据、时间线、检测方式、根因、缓解动作和经验教训。AWS Well-Architected 的操作卓越原则也把组织、可观测、自动化、演练、流程迭代和从事件中学习放在一起。
这两者说的是同一件事:故障处理不是结束在“已恢复”,而是结束在下一次更容易处理。
如果复盘只写“加强监控、优化告警、提升响应效率”,它基本不会改变下一次故障。好的改进项应该能验收:新增了哪个业务指标,调整了哪条告警路由,哪个服务补了 runbook,哪个升级联系人被写进值班策略,哪个高频故障被合并治理,哪个操作被自动化。
复盘不落地,MTTR 就会变成一个被反复汇报、反复焦虑、但很少真正下降的数字。
真正要升级的不是一个工具,而是一条链路
企业当然需要好工具。但如果工具只停留在“监控发消息”,MTTR 很难系统性下降。
更完整的链路应该是:
发现阶段,Flashcat 把多源监控和业务健康放在一起,让团队更早看到真正影响用户的症状。
响应阶段,Flashduty 接住多源告警,完成降噪、路由、排班、升级、触达和认领,让故障从消息进入责任流程。
定位阶段,指标、日志、链路、事件、变更、作战室记录和 AI SRE 初筛在同一上下文里工作,减少跨工具搬运。
复盘阶段,时间线、认领记录、升级记录、处理动作和改进项被留下来,管理者能看见 MTTA、MTTR 和重复故障到底怎么变化。
这不是为了把所有事情塞进一个平台,而是为了让故障现场少一点猜测、少一点等待、少一点重复劳动。
最后可以做一个很简单的动作:找出最近一次 P1 或 P2 故障,把时间线拆成发现、分派、定位、修复、验证、复盘六段。不要急着讨论买什么工具,先看时间到底耗在哪里。看清楚之后,下一步该补监控、改路由、建 runbook、明确升级规则,还是把复盘改进项盯到完成,就会清楚很多。
原文地址: http://www.cveoy.top/t/topic/qGWS 著作权归作者所有。请勿转载和采集!