内存化在对账系统中的应用实践
内存化在对账系统中的应用实践
上篇讲了内存化系统的设计思路,这篇是一次真实落地的案例,聊聊对账怎么做内存化,以及它在吞吐量、成本和工程复杂度上带来了什么。
一、重新认识对账问题
很多系统里,对账就是:两张表、一条 JOIN、一个定时任务。
流水量小的时候没问题。但量上来之后,JOIN 越来越慢,跨周期的逻辑越来越绕,锁、事务、补偿代码层出不穷。
根子在哪?对账不是 CRUD,是一个持续推进的状态机。
它有几个特点:流水量大,但生命周期有限;同一条流水只能处理一次;顺序和确定性很关键。这几点加在一起,恰好是内存化最合适的场景。
二、传统方案为什么越做越重
1. MySQL:适合存档,不适合推进
MySQL 做结果存档没问题,但对账需要的是过程计算:
- 性能被 IO 和索引卡住
- 复杂事务引发锁竞争
- 中间状态被迫拆成多张表
- 对账进度从表结构里根本看不出来
流水到千万级,对账系统就变成了一堆 SQL 在和时间赛跑。
2. Flink:能用,但资源花在了别处
先说结论:Flink 做对账不是不行,是有点重。
Flink 的优势在于来源多、乱序严重、迟到数据多的场景。用 keyBy + state + watermark 处理乱序,确实优雅。
但对账的真正瓶颈往往不是"能不能算出来",而是吞吐够不够、成本能不能接受、复杂度能不能长期维护。
落地下来,Flink 的问题集中在三块:
- State 落在 RocksDB 上,未匹配流水多的时候磁盘 IO 很高
- Checkpoint 在状态大、变化频繁的对账场景下容易成为瓶颈
- State 膨胀、反压这些运维问题比较常见
所以 Flink 做对账是能用,但单位资源能跑多少流水,比内存化差不少。
三、内存化对账的核心思想
先说一个常见误解:内存化不是"为了快,把数据库换成内存"。它改变的是状态管理方式。
内存就是状态机。 对账状态只在内存里,内存里有什么,系统当前就是什么状态。没有"内存一份、数据库又一份"的数据冗余。
单写入者,顺序执行。 同一个对账任务只有一个线程在写,所有变更按顺序发生。不需要锁,不需要事务,也不需要对"并发写同一条流水"做任何处理。
可重建,而不是不能丢。 内存数据可以丢,但丢了之后要能重新建出来。这是后面"对账文件当 WAL 用"能成立的前提。
四、对账文件就是 WAL
对账场景有个常被忽略的事实:对账文件本身就是天然的 WAL。
文件记录的是已经发生的事,顺序固定、可重放,不需要再设计额外的日志系统。
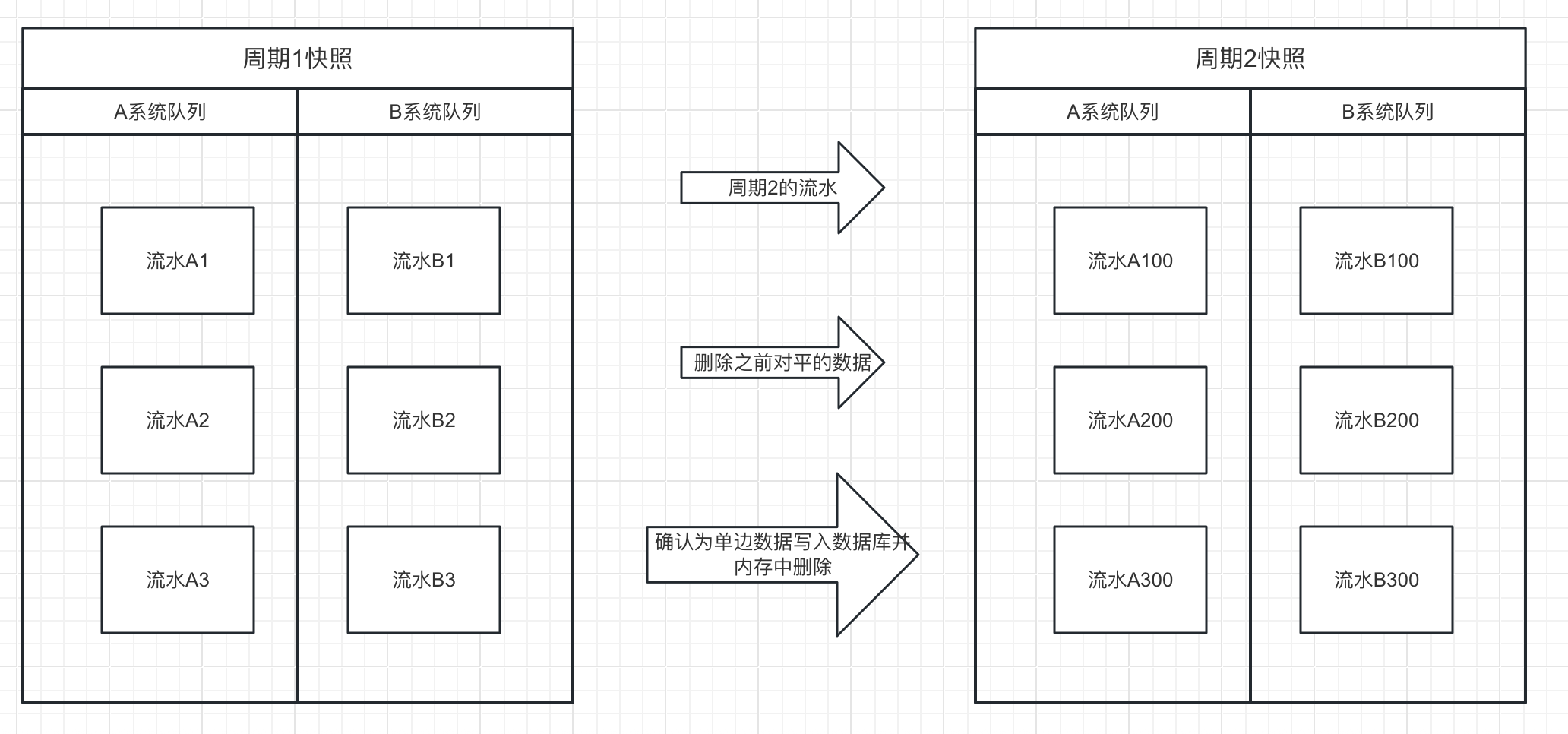
快照不是全量流水的备份,而是一个或多个对账周期结束后,内存里还没对平的那部分流水。
恢复流程:加载最近快照,然后从对账文件里继续往后推进。就这两步。
五、整体流程
对账流程分几个阶段:
数据获取。 来源可以是对账文件、数据库导出、FTP 或 HTTP 上传,具体形式不重要。核心是拿到某个对账周期(1 分钟、1 小时、1 天)内的数据截断。
预处理(可选)。 多文件合并、按业务时间排序、处理上游乱序。上游已经有序的话,这步直接跳过。
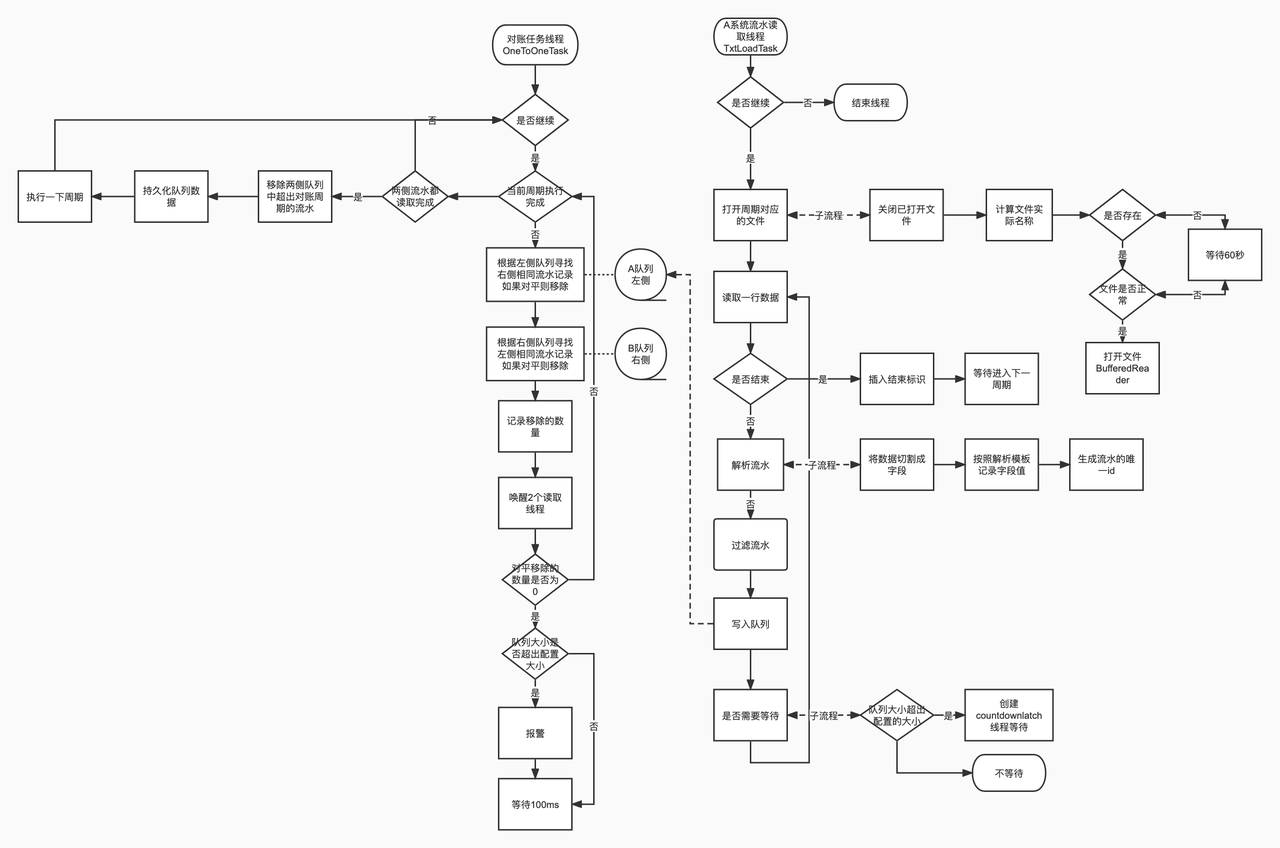
读取。 顺序读每个业务方的对账文件,生成流水唯一 ID,写入各自的内存队列。把外部数据稳定地变成内存事件。
对账。 从一个队列里取数据,去另一个队列里找匹配。对平了就从两个队列里都删掉,没对平就放回队列尾部等后续流水。
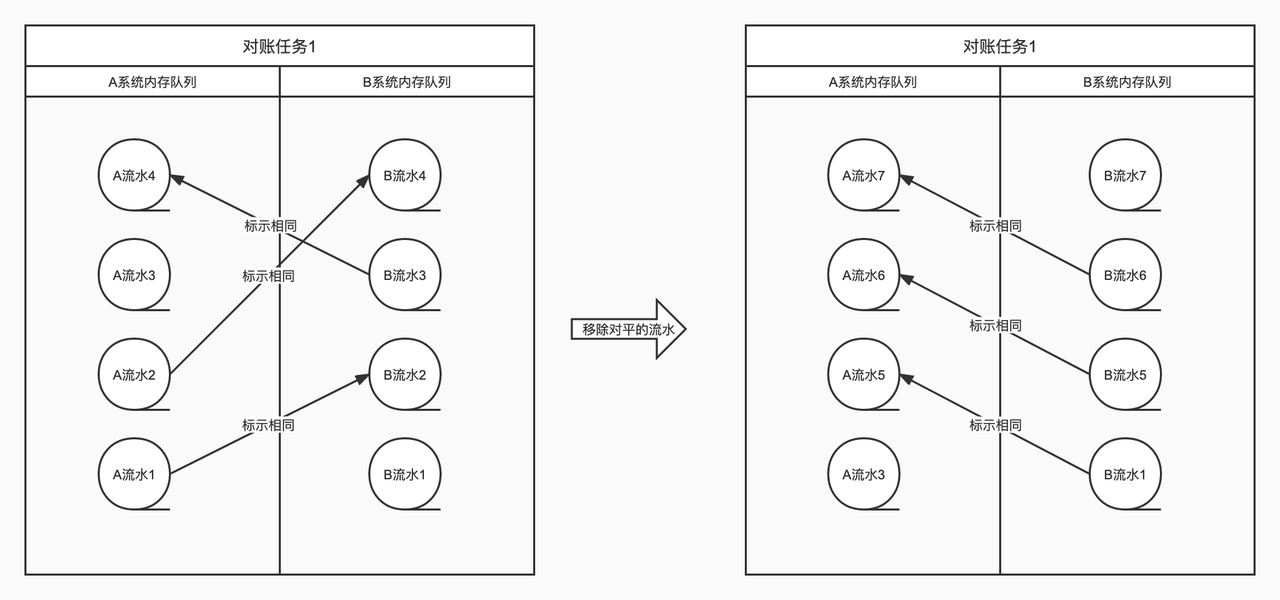
持久化。 每个周期结束后,把内存里还没对平的数据存成快照;单边账写入数据库;配置和周期相关数据用单独的表维护。
运行流程:
六、内存队列模型
队列怎么推进
读取线程往队列尾部写流水,对账线程从头部取流水去匹配。能对平的直接删,不能对平的放回尾部。循环往复,队列里的数据慢慢被消化掉。
内存里剩下的就是当前系统状态,也是快照的内容。重启后,从最新快照恢复内存,再从快照点之后的对账文件重新开始对账。
跨周期不是异常
不同系统生成的对账文件,同一条业务流水的时间戳可能不同,有时候会落到不同的对账周期里。
所以一个周期内没匹配上,不代表是异常。当前周期的未对平流水会留下来,下个周期继续尝试。连续多个周期都没对平,才判定为异常。这样可以避免因为周期边界问题产生大量误报。
有序是前提
队列模型能跑起来,两边的流水得大致有序。
严重乱序的话,大量数据长期无法匹配,队列消不掉,内存就会一直涨,最终把对账任务撑死。实际工程里要么在预处理阶段排序,要么对上游提顺序约束。
周期必须同步
对账任务和所有来源任务必须在同一个周期里。对账还在处理 9 月 15 日,某个来源任务已经在读 9 月 16 日的数据,状态就乱了。
七、吞吐量对比
对账系统通常不太在意单条延迟,更关心同样机器资源下一分钟能对多少流水。
| 方案 | 单机吞吐量量级 | 主要限制因素 |
|---|---|---|
| MySQL | 万级 / 分钟 | IO、索引、锁 |
| Flink | 十万级 / 分钟 | State、Checkpoint |
| 内存化 | 百万级 / 分钟 | 内存容量与带宽 |
Flink 的绝对吞吐量不差,但资源花在了通用性和分布式能力上。内存化方案只解决对账这一件事,相同资源下算力更集中,吞吐通常高一个数量级,延迟分布也更稳定。
八、代价与边界
说说缺点。
状态全在内存里,风险也集中。设计阶段要克制,分区方式直接决定系统上限。
但对账场景顺序明确、状态可回收,这两点恰好是内存化最能发挥的地方。
九、最后
内存化对账没什么神秘的,是一个务实的工程选择。
数据乱序、周期错位、系统崩溃,这些都会发生。内存化的方式是通过顺序执行和可重放的输入,把复杂性限制在它该在的地方处理,而不是扩散到整个系统。
如果你的对账系统吞吐量撑不住、成本压不下来、逻辑越来越乱,内存化不一定是激进方案,可能只是换了个更直接的路。
推荐一下我的微信小程序 - “两步动态验证”
- 有任何建议或需求可以直接联系我
- 免费云端加密备份 :换机不丢失,安全又便捷
- API快速集成 :提供开放API,实现自动化验证码获取
- 多端共享:基于微信小程度,可同时在手机,PC端共同使用,一键复制
- 扫描二维码试用,或微信小程序搜索“两步动态验证”

原文地址: https://www.cveoy.top/t/topic/qGxx 著作权归作者所有。请勿转载和采集!