Neo4j 笔记(四):一篇文章如何入库的
摘要
一直很好奇,一篇文章是如何进入到图数据库的,毕竟一篇文章啥格式都有,而写入到图数据库还必须遵从规则和语法,所以这注定不是一个普通RAG或者SQL的过程。此篇讲带大家一起看一下这里都需要经历哪些过程。
Graph RAG 把文章变成 Neo4j 数据,一共 4 步:
- 从文章里抽实体(人、公司、地点、产品、时间…)
- 抽实体之间的关系(A 工作于 B、C 位于 D、E 认识 F…)
- 生成节点 + 关系(Node + Relationship)
- 批量写入 Neo4j(CREATE / MERGE)
最终在 Neo4j 里形成一张知识图谱,RAG 检索时就可以沿着关系查上下文。
我们用一段超短新闻做演示:
张三在2023年加入了字节跳动,担任算法工程师。
李四是张三的同事,他们都在北京工作。
以上的超短新闻,要想配合入图数据库,首先是需要抽象出以下信息。
实体(Nodes)
- 张三 (Person)
- 李四 (Person)
- 字节跳动 (Company)
- 北京 (Location)
关系(Relationships)
- 张三 ——WORKS_AT——> 字节跳动
- 张三 ——COLLEAGUE_OF——> 李四
- 张三 ——WORKS_IN——> 北京
- 李四 ——WORKS_IN——> 北京
属性
- 张三:age=None, job=算法工程师, join_year=2023
实体,关系,属性信息都确认了之后,就可以通过以下语句入库了。
// 创建节点
MERGE (p1:Person {name:"张三"}) SET p1.job="算法工程师", p1.join_year=2023
MERGE (p2:Person {name:"李四"})
MERGE (c:Company {name:"字节跳动"})
MERGE (l:Location {name:"北京"})
// 创建关系
MERGE (p1)-[:WORKS_AT]->(c)
MERGE (p1)-[:COLLEAGUE_OF]->(p2)
MERGE (p1)-[:WORKS_IN]->(l)
MERGE (p2)-[:WORKS_IN]->(l)
为什么用 MERGE 不用 CREATE?
- CREATE:重复执行会重复创建节点
- MERGE:不存在则创建,存在则更新 → Graph RAG 标准写法
那么如何把文章里的信息是如何抽象出的实体和关系呢,直接说过程:文章不是人工转的,是 LLM 自动转的!
下面是真实工程化流程:
首先,给大模型的提示词
你是知识图谱抽取专家。请从文本中抽取:
1. 实体(类型:Person, Company, Location, Organization)
2. 关系(只能用:WORKS_AT, COLLEAGUE_OF, WORKS_IN, FOUNDER_OF)
输出格式严格JSON:
{
"nodes": [{"label":"Person", "name":"张三", "attributes":{"job":"算法工程师"}}],
"relations": [{"from":"张三", "to":"字节跳动", "type":"WORKS_AT"}]
}
文本:
张三在2023年加入了字节跳动,担任算法工程师。李四是张三的同事,他们都在北京工作。
以上提示词可以放在任何工具里测试,包括龙虾,豆包等。
实体和关系总结出来了,可以看到结果如下:
{
"nodes": [
{"label":"Person","name":"张三","attributes":{"job":"算法工程师","join_year":2023}},
{"label":"Person","name":"李四","attributes":{}},
{"label":"Company","name":"字节跳动","attributes":{}},
{"label":"Location","name":"北京","attributes":{}}
],
"relations": [
{"from":"张三","to":"字节跳动","type":"WORKS_AT"},
{"from":"张三","to":"李四","type":"COLLEAGUE_OF"},
{"from":"张三","to":"北京","type":"WORKS_IN"},
{"from":"李四","to":"北京","type":"WORKS_IN"}
]
}
注:如果模型是在线API,那么基本上都能按照要求做出指定的输出,如果是本地部署的模型,参数量比较低的话,输出可能会走样。
最后,通过python代码自动把 JSON 转成 Cypher 写入 Neo4j
from neo4j import GraphDatabase
# 连接 Neo4j
uri = "bolt://localhost:7687"
user = "neo4j"
password = "your-password"
driver = GraphDatabase.driver(uri, auth=(user, password))
# 从LLM拿到的知识图谱数据
data = { ...上面的JSON... }
# 写入节点
for node in data["nodes"]:
if node["attributes"]:
attrs = ", ".join([f"{k}: '{v}'" for k, v in node["attributes"].items()])
cypher = f"MERGE (n:{node['label']} {{name:'{node['name']}', {attrs}}})"
else:
cypher = f"MERGE (n:{node['label']} {{name:'{node['name']}'}})"
driver.session().run(cypher)
# 写入关系
for rel in data["relations"]:
cypher = f"""
MATCH (a {{name:'{rel['from']}'}}), (b {{name:'{rel['to']}'}})
MERGE (a)-[:{rel['type']}]->(b)
"""
driver.session().run(cypher)
✅ 运行完,一篇文章就变成知识图谱了!
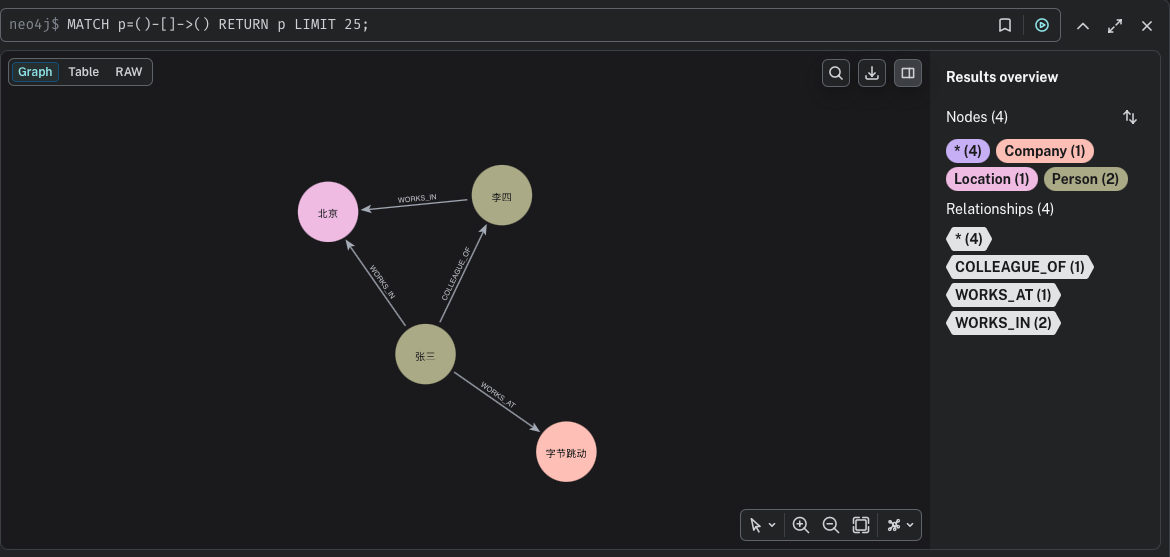
最终效果(Neo4j 里看到的图)
你会看到:
- 张三、李四、字节跳动、北京
- 它们之间用箭头连起来
- Graph RAG 检索时就能沿着关系推理
最后再说一种更简单粗暴的方法,跳过大模型生成JSON和python的JSON遍历,直接让大模型生成语句。
你是知识图谱抽取专家。请从文本中抽取实体和关系信息,直接帮我生成neo4j的cypher语句。
文本:
张三在2023年加入了字节跳动,担任算法工程师。李四是张三的同事,他们都在北京工作。
然后在python里直接run生成的查询就可以了。
总结
大模型技术的成熟让图数据库落地应用变得更容易。此篇简单的汇总了一篇文章是如何进入到图数据库的。下一篇会总结一个比较完整的实现。
原文地址: https://www.cveoy.top/t/topic/qGxE 著作权归作者所有。请勿转载和采集!