复杂度的均摊分析法
动态数组扩容问题是均摊复杂度分析最经典的应用:
- 动态数组的尾插
push_back,有时会触发扩容; - 一旦扩容,就要申请更大的内存、搬运旧元素、再插入新元素。某一次操作的代价完全可能是 \(O(n)\)
- 但是,动态数组尾插的复杂度是均摊 \(O(1)\)
类似的现象其实非常多:单看某一次操作,它们都可能很贵;但把它们放到足够长的操作序列里,平均到每一步,复杂度却仍然很低。均摊分析研究的正是这种现象。
平均情况分析 vs 均摊分析
均摊分析和平均情况分析(average-case analysis)不是同一个概念。
平均情况分析通常要假设输入服从某种概率分布,然后计算期望成本。比如快速排序的平均复杂度分析,核心就在于对输入或主元分布做假设。例如,快速排序平均是 \(O(n\log n)\) 的,但最坏可能是平方复杂度。
均摊分析则不同。它不依赖概率和输入,一个 vector 无论怎样尾插,均摊复杂度也是 \(O(1)\) 。
我们可以定义:对于一个数据结构的一段操作序列
如果总实际成本是
能否证明存在某个函数 \(f(m)\),使得
如果可以,那么就说这类操作的均摊复杂度是 \(f(m)\)。可以理解为,均摊分析给出的是“整段序列的总账不贵”的承诺。于是,均摊 \(O(1)\) 并不意味着每次操作都只花常数时间,它真正的含义是:在任意长的合法操作序列里,总成本相比操作次数的复杂度没有那么高。
经典例子:动态数组
动态数组是本文最好的主线。假设一个动态数组有两个状态量:
size:当前元素个数capacity:当前容量
执行 push_back(x) 时:
- 若
size < capacity,直接写入,成本记为 \(1\); - 若
size = capacity,则申请一个两倍大的新数组,把旧元素全部搬过去,再插入新元素。若旧容量为 \(k\),那么这次成本记为 \(k+1\)。
单次最坏显然是线性的;但长期看却是均摊常数。下面分别用三种方法来理解它。
聚合法:直接算前 \(n\) 次操作的总成本
聚合法直接计算多步的总成本。由于每次扩容是两倍,数组容量会按 \(1,2,4,8,\dots\) 这样翻倍增长。做完前 \(n\) 次插入时,普通写入本身一共发生了 \(n\) 次,成本是 \(n\)。除此之外,还会发生若干次扩容搬运,搬运量依次是 \(
1+2+4+\cdots+2^{k-1},
\),其中 \(2^{k-1}
所以总成本满足
也就是说,前 \(n\) 次 push_back 的总成本是 \(O(n)\),因此平均到每次操作,复杂度就是 \(O(1)\)。
这个证明非常重要,因为它第一次把“偶尔很贵”和“长期很便宜”这两个看似矛盾的结论接起来了。扩容确实贵,但扩容发生得足够稀疏,所以总账仍然可控。
记账法:平时多收一点,留着给扩容买单
记账法比聚合法更有“预算”的味道。我们不直接算总账,而是假装给每次操作都规定一个均摊收费标准。
还是看动态数组尾插。设每次 push_back 都收费常数代价 \(3\)。
- 如果这次没有扩容,真实成本只有 \(1\),那就剩下 \(2\) 存起来;
- 如果这次触发扩容,就从之前存下来的余额里支付搬运成本。
为什么这个方案可行?考虑一次从容量 \(m\) 扩到 \(2m\) 的扩容。在这次扩容发生前,数组已经经历了从半满到装满的一系列普通插入。也就是说,每次扩容时,前面都有发生了足够多(大约 \(m/2\) )的便宜插入,每次都能攒出足够余额,总共可以积累出足以覆盖这次搬运的资金。
势能法
从记账的思想更进一步,我们就可以引出势能法。它的思想是:给数据结构状态 \(D_i\) 定义一个势能函数 \(\Phi(D_i)\),然后把第 \(i\) 次操作的均摊成本定义为
这里:
- \(c_i\) 是第 \(i\) 次操作的真实成本;
- \(\hat c_i\) 是我们定义出来的均摊成本;
- \(\Phi(D_i)-\Phi(D_{i-1})\) 表示状态势能的变化。
这样一次操作的均摊成本就是他的"实际成本 + 势能变化"
如果我们能选取出合适的势能函数表示当前状态(要保证势能始终非负,并且初始势能为 \(0\)),那么对前 \(m\) 次操作有
所以,只要每一步的均摊成本都有常数上界,那么真实总代价也就有同阶上界。
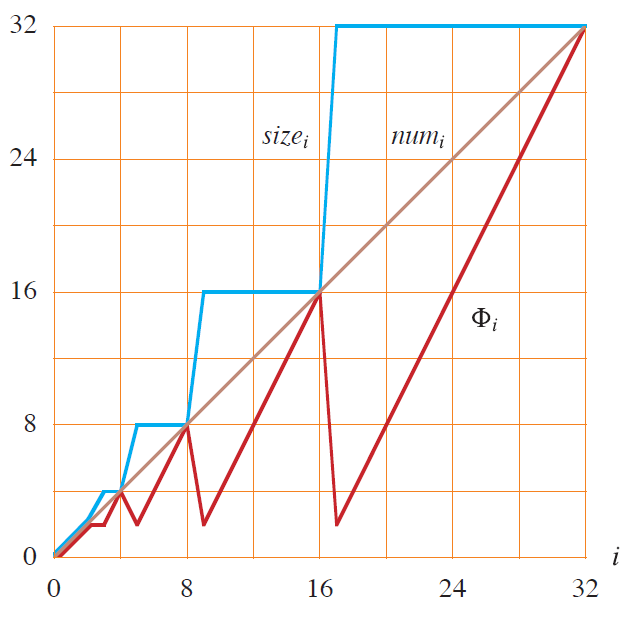
对动态数组,一个经典势能函数是
这个定义的直觉是:数组越接近装满,也就越接近下一次扩容,势能越大。
对于不扩容的普通插入。真实成本 1,势能变化 2(因为 size 增加 1,而 capacity 不变),均摊代价 3
对于触发扩容的插入。插入前 size = m,capacity = m,势能是 \(\Phi_{\text{old}}=m\);插入后 size = m+1,capacity = 2m,势能变成
这次真实成本是搬运 \(m\) 个旧元素再插入新元素(共 \(m + 1\)),势能变化是 \( \Delta \Phi = 2-m。 \)。所以均摊成本为 \(3\)
不扩容时是 \(3\),扩容时还是 \(3\)。因此动态数组尾插的均摊复杂度就是 \(O(1)\)。
其他常见例子
栈的 MULTIPOP
考虑一个支持三种操作的栈:
PUSH(x):压栈,成本为 \(1\);POP():弹栈,成本为 \(1\);MULTIPOP(k):连续弹出最多 \(k\) 个元素,成本等于实际弹出的元素数。
单看一次 MULTIPOP(k),它当然可能要弹很多元素,代价不是常数。但如果看一整段操作序列,总弹出次数其实不可能超过总压栈次数。因为每个元素最多只会被压入一次、弹出一次。
因此,如果总共有 \(m\) 次操作,那么所有弹栈动作加起来不会超过线性级别,于是总成本是 \(O(m)\),均摊每次仍是 \(O(1)\)。
这个例子特别适合作为均摊分析的第一个训练:只要能发现“每个元素最多被贵处理一次”,总成本往往就很好控制。
二进制计数器的自增
再看一个更经典的例子。一个二进制计数器不断执行 INCREMENT,一次操作的成本定义为被翻转的位数。
例如:
0111 \to 1000的成本是 \(4\);1010 \to 1011的成本是 \(1\)。
单次最坏显然不是常数,但连续执行 \(n\) 次自增时,第 \(0\) 位每次都翻,第 \(1\) 位每两次翻一次,第 \(2\) 位每四次翻一次,一般地,第 \(i\) 位每 \(2^i\) 次翻一次。
所以总翻转次数满足
因此,\(n\) 次自增的总成本是 \(O(n)\),均摊下来每次仍是 \(O(1)\)。这个例子也很有代表性:某次昂贵进位之所以会发生,是建立在之前很多较低位状态积累的基础上;他发生的足够少,所以总成本并不会爆炸。
另一个视角是,规定每次 INCREMENT 收费 \(2\)。当某一位从 0 变成 1 时,真实成本是 \(1\),剩下的 \(1\) 单位信用就附着在这个新的 1 上。以后当它从 1 变回 0 时,就用这份信用支付那次翻转。
于是每个 1 的“出生”和“死亡”在它变成 1 的那一刻就已经付清了。虽然某次自增可能会消灭一长串连续的 1,但这些 1 各自都携带了自己的预算,所以集中翻转时并不会额外欠债。
单调队列
单调队列(monotonic queue)是滑动窗口问题里的常用工具。以滑动窗口最大值为例:给定数组 \(a_1,a_2,\dots,a_n\) 和窗口大小 \(k\),要求每个长度为 \(k\) 的窗口最大值。
标准做法是维护一个双端队列,队列里存下标,并保持这些下标对应的值单调递减。处理位置 \(i\) 时,通常做三件事:
- 把队首已经滑出窗口的下标弹出;
- 当队尾对应的值小于等于 \(a_i\) 时,不断从队尾弹出;
- 把当前下标 \(i\) 压入队尾。
看起来最可疑的是第二步。一次插入新元素时,完全可能触发很多次队尾弹出。比如遇到一个很大的新元素,它会把队尾一串更小的元素全部清掉。单次看,这一步显然不是常数。
但从聚合法的角度看,整个算法仍然是线性的。因为:
- 每个元素在被扫描到时,只会压入队尾一次;
- 它之后要么因为滑出窗口从队首弹出,么因为遇到更大的元素从队尾弹出;不管是哪一种,被弹出以后它都不会再回来。
因此,在整个过程中,所有入队次数总共是 \(n\),所有出队次数总共也是 \(O(n)\)。虽然某一步的 while 循环可能连续弹很多次,但把所有这些弹出加起来,最多不过线性数量。
看到循环里面还有循环,很多人会本能地把它看成平方复杂度;但只要循环内部“消耗掉的对象”一旦离开就不再回来,均摊分析往往能把复杂度压回线性。
两个栈实现队列
队列可以用两个栈来实现。考虑用两个栈 S_in 和 S_out 实现队列:
enqueue(x):把元素压入S_in;dequeue():如果S_out非空,直接弹出;如果S_out为空,就把S_in中所有元素逐个倒入S_out,再弹出队首。
某次 dequeue() 看上去可能很贵,因为它会在那一刻做整批搬运。但如果从元素的一生看,这个结构其实非常简单。
一个元素从入队到出队,最多只会经历四个基本动作:
- 压入
S_in - 从
S_in弹出 - 压入
S_out - 从
S_out弹出
于是我们可以规定:每个元素在 enqueue 时统一收取常数费用 \(4\),分别用于支付它未来的一生。这样一来,后面即使某一次 dequeue() 触发了整批倒栈,那也不过是在集中兑现许多元素早已缴纳好的费用而已。因此,入队和出队的均摊复杂度都是 \(O(1)\)。
从势能的角度看,可以定义势能为
这个定义的直觉是:S_in 里的每个元素将来都至少还要经历两次动作——从 S_in 弹出,再压入 S_out。所以它们的存在本身就意味着未来还藏着一些尚未支付的成本。对一次 enqueue(x) 来说,真实成本是 \(1\),势能增加 \(2\),于是均摊成本为 \(3\)
对一次不触发倒栈的 dequeue(),真实成本是 \(1\),势能不变,因此均摊成本是 \(1\)。
对一次触发倒栈的 dequeue(),设此时 S_in 中有 \(k\) 个元素。真实成本是把这 \(k\) 个元素逐个倒到 S_out 的 \(2k\),再弹出队首的 \(1\),总共 \(
2k+1。
\)。而与此同时,S_in 变空,势能减少 \(
\Delta \Phi = -2k。
\)。均摊成本为 \(
1
\)
哈希表扩容
哈希表(hash table)里的扩容和动态数组非常相似。平时插入一个键值对,通常只需常数时间;但一旦装载因子过高,就可能触发 rehash,把整张表里的元素重新分布到更大的桶数组里。
单次 rehash 的最坏代价显然是线性的,但它不会频繁发生。只要扩容策略是按常数倍增长,那么在一长串插入操作里,总搬运量仍然是线性的,推导过程和变长数组完全相同。因此插入的均摊复杂度仍为 \(O(1)\)。
动态数组扩展
前面一直只讨论 push_back,但实际动态数组通常还会支持 pop_back。这时问题会变得更微妙一些:如果我们在数组刚满时就扩容、刚删掉一个元素就立刻缩容,那么在边界附近反复执行 push_back 和 pop_back,就可能出现“来回抖动(thrashing)”:次扩完马上缩,一次缩完马上又扩,这一串合法操作每次都是 \(O(n)\) 的,复杂度就炸了。
解决办法是把扩容阈值和缩容阈值分开:例如满了才扩到 2 倍,而只有当 size 下降到 capacity / 4 时才缩到 capacity / 2。这样就留出了一个缓冲区,避免在同一条边界附近频繁震荡;进一步做势能分析或记账分析,仍然可以证明 push_back / pop_back 的均摊成本是 \(O(1)\)。
另外,虽然我们都用"2 倍扩容"举例子,但可以证明,只要容量按常数倍增长,即从 \(m\) 扩到 \(\alpha m\),其中 \(\alpha > 1\) 是常数,那么总搬运成本仍然是一个等比级数:
因此均摊插入成本依然是 \(O(1)\);相反,如果每次只固定增加一个常数,比如每次只多开 100 个位置,那么扩容会发生得越来越频繁,总搬运成本会累积成平方级,总体就不再是均摊常数。工程上通常选 2 倍扩容,主要是因为它在“减少扩容次数”和“控制空闲空间浪费”之间给出了一个很均衡的折中:倍数太小,会导致扩容过于频繁;倍数太大,虽然扩容次数更少,但会浪费更多未使用容量。
更高难度数据结构的均摊分析例子
很多真正强力的数据结构,复杂度结论本身就建立在均摊分析上。这里只列举,不再细证。
并查集
带路径压缩(path compression)和按秩合并(union by rank)的并查集,是均摊分析最经典的高级案例之一。
单次 find(x) 可能要沿着父指针一直爬到根,看起来并不便宜;但路径压缩会在返回过程中把整条路径上的节点直接挂到根附近。于是,那些这次被访问到的节点,以后再查找时就会更快。
最终可以证明:对 \(n\) 个元素执行 \(m\) 次操作,总成本是
其中 \(\alpha(n)\) 是反阿克曼函数(inverse Ackermann function),增长极慢,在实际规模下几乎可以视为常数。
这个结论本质上就是均摊分析:某次 find 可能很贵,但那次昂贵访问顺便把未来很多次查找都优化掉了。
伸展树
Splay Tree 的每次访问都会通过一系列旋转把目标节点伸展到根。单次访问的最坏复杂度并不漂亮,但整个访问序列的总代价却很优雅。
经典分析会定义某种与子树规模相关的势能,例如
其中 \(s(x)\) 是以节点 \(x\) 为根的子树大小。通过一套势能分析,可以得到访问的均摊复杂度为 \(O(\log n)\)。这个例子说明,势能法的用途远不止“为扩容攒点钱”那么简单。它还可以用来衡量一棵树当前有多“失衡”,而单次昂贵的重构恰恰是在降低这种失衡。
斐波那契堆
Fibonacci Heap 是另一个典型案例。它的一些操作,比如 insert、meld、decrease-key,都能达到非常低的均摊复杂度,而代价被集中到少数整理操作上。只要一个数据结构允许“延迟维护(lazy maintenance)”,均摊分析几乎就会自然出现。
原文地址: https://www.cveoy.top/t/topic/qGvQ 著作权归作者所有。请勿转载和采集!