Java程序员必看的RAG入门教程
前言
这两年,随着大模型的爆发,很多小伙伴都有这样的困惑:OpenAI GPT-4、Claude 3.5这些模型确实很强大,但一旦问到企业内部的具体问题,比如“我们公司去年Q3的营收是多少”,它就傻眼了。
要么回答“我不知道”,要么就开始一本正经地胡说八道——这就是所谓的“AI幻觉”。
大语言模型的知识源于其训练数据,模型在训练时尽力把海量信息压缩进有限参数中,但无法像数据库那样精确记录每一个事实,尤其是那些训练语料中极少提及的细节。
更致命的是,训练数据是有明确截止时间的,无法获取之后的新信息。
因此,大语言模型天然存在知识静态、容易产生幻觉、缺乏专业深度三大缺陷。
RAG(检索增强生成)就是专门解决这个问题的技术。
RAG通过检索外部知识库来增强模型能力,当用户查询最新信息时,RAG先检索外部数据库中的实时内容,再让LLM基于检索结果生成答案,从而将LLM从静态记忆者转变为动态整合者。
今天,我就从零开始,用Java开发者的视角,带大家系统了解RAG到底是什么、怎么工作、如何落地。
更多项目实战在Java突击队网:susan.net.cn
一、什么是RAG?
1.1 核心公式
RAG(Retrieval-Augmented Generation,检索增强生成)的核心思想其实很简单:在让LLM回答问题之前,先从你的私有知识库中找到相关的信息,然后把问题和信息一起交给LLM来回答。
RAG = 检索(Retrieval) + 增强(Augmented) + 生成(Generation)
从学术角度看,RAG通过将生成过程与可验证的最新证据紧密耦合,直接解决了大模型的幻觉问题。
RAG不仅能让LLM回答训练数据中不存在的新问题,还能为生成的答案提供来源引用,大幅提升了可信度和可审计性。
用大白话来说:LLM本身就是一本百科全书,但它不知道你的公司内部资料。RAG就是在每次提问时,先去翻你的资料库,把相关内容找出来,然后连同问题一起交给LLM,让它基于这些资料来回答。
1.2 为什么需要RAG?
有些小伙伴可能会问:为什么不能把企业知识库全部喂给LLM训练呢?
这里有三个现实问题:
-
知识更新不及时:LLM的训练数据有明确的截止时间。重新训练模型以更新知识成本高昂(数百万至数亿美元),且可能引发灾难性遗忘问题。
-
无法访问私有数据:你的公司内部文档、客户邮件、合同信息,这些数据不会出现在LLM的训练数据中。RAG通过构建定制化知识基座解决这一问题:将企业内部文档导入向量数据库,使通用LLM瞬间升级为领域专家。
-
成本极高:重新训练或微调一个LLM需要数万甚至数百万美元,不是普通企业负担得起的。RAG无需重新训练,成本仅为微调的1/10到1/100。
RAG完美解决了这三个问题:它不改变LLM本身,只是让LLM“带着资料回答问题”。
企业级RAG正在快速普及。
据2026年4月百度开发者社区的分析,RAG通过整合外部知识库,弥补了大语言模型在实时性、准确性和专业性上的不足,广泛应用于企业场景。
RAG还通过引入事实边界约束,要求LLM的答案严格基于检索到的权威文档并附带来源链接,这在金融、医疗等合规敏感行业中至关重要。
二、RAG的核心架构
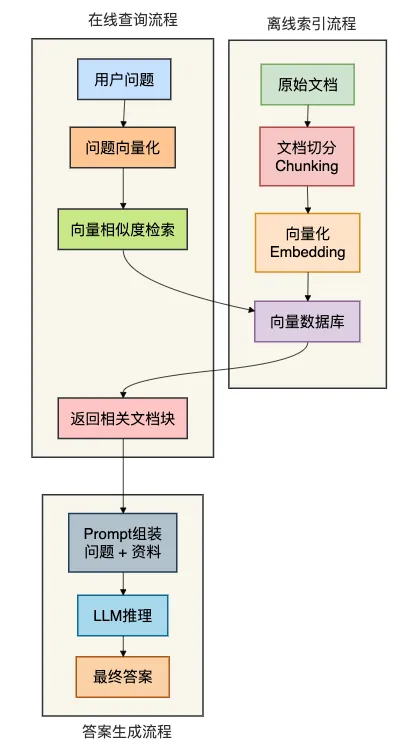
RAG的架构可以清晰地分为两大流程:离线索引和在线检索生成。
2.1 四大核心步骤
一篇2026年发表的全面综述论文将现代RAG架构解构为索引(Indexing)、检索(Retrieval)、融合(Fusion)和生成(Generation) 四个阶段,并梳理了从基础向量RAG到Graph RAG、Agentic RAG、多模态RAG等多种新兴范式。
离线索引阶段(只做一次,或者在文档更新时重新做):
-
文档切分(Chunking):把一篇长文档切成若干个小块(Chunk)。为什么要切?因为LLM的上下文窗口有限,一次也塞不下太多内容。
-
向量化(Embedding):使用嵌入模型将文本块转换为向量(数字数组),实现语义相似性计算。
-
存储:将向量和对应的原始文本一起存入向量数据库,供后续检索使用。
在线检索生成阶段(每次用户提问时执行):
- 检索增强生成:将用户问题转化为向量,在向量数据库中执行相似度检索,获取最相关的文档片段,然后与问题一起提交给LLM生成答案。
更多项目实战在Java突击队网:susan.net.cn
三、RAG的关键技术组件
3.1 向量数据库:RAG的“记忆库”
向量数据库是RAG的核心基础设施。它专门用于存储和检索高维向量数据,支持海量数据下的毫秒级相似度检索。
2026年,业内已经形成了清晰的向量数据库选型框架,通常依据检索质量、过滤能力、混合搜索支持、索引选项、运维就绪度、生态集成、安全性和成本模型等维度进行评估。
| 向量数据库 | 核心特点 | 部署方式 | 适用场景 |
|---|---|---|---|
| TiDB Vector Search | SQL+向量一体化,混合搜索强 | 托管+自托管 | RAG+SQL混合负载 |
| Milvus | 功能最丰富,开源首选 | 托管+自托管 | 大规模专用向量场景 |
| pgvector | PostgreSQL扩展,SQL原生 | 自托管 | 已有PG的中小项目 |
| Weaviate | 生态友好,混合搜索成熟 | 托管+自托管 | 多模态+过滤重应用 |
| Qdrant | Rust编写,高性能 | 托管+自托管 | 对性能和延迟敏感 |
| Chroma | 轻量级,开箱即用 | 自托管/本地 | 原型验证和小型项目 |
| OpenSearch | BM25+向量双强 | 托管+自托管 | 关键词+语义混合检索 |
数据参考:对于典型的RAG工作负载(1536维嵌入,topK=10),经过良好调优的系统可实现90-95%的召回率,p95延迟低于100ms。
没有单一的“最佳”向量数据库,选择完全取决于你的具体工作负载、过滤需求和是否需要向量与事务SQL数据共存。
3.2 Embedding模型:把文字变成“坐标”
Embedding模型负责将文本转换成向量。选型时需要注意:
- 多语言支持:如果你的知识库包含中英文,需要选择支持多语言的模型
- 多模态支持:2026年的RAG已经从纯文本扩展到多模态,支持文本、图像、图表等多种数据类型
- 跨语言能力:中文查询需要能够找到英文文档,反之亦然
据Milvus 2026年3月发布的10款主流嵌入模型基准测试,Gemini Embedding 2是最佳的全能选手,开源模型Qwen3-VL-2B在跨模态任务上甚至超越了闭源API。
如果你需要压缩向量维度以节省存储空间,Voyage Multimodal 3.5或Jina Embeddings v4是更好的选择。
该基准测试发现,MTEB排行榜存在严重局限——它只测试单一语言的文本检索,不包括跨模态检索、跨语言搜索和长文档精确度。
生产型RAG需要的是CCKM(跨模态、跨语言、关键信息、MRL压缩)四维能力,而传统基准恰恰遗漏了这些。
3.3 重排序(Rerank):提升精准度
向量检索返回的Top-K结果中,排在前面的不一定是最相关的。引入重排序模型可以对候选结果进行二次打分,显著提升检索精度。
3.4 混合检索:BM25 + 向量
结合关键词匹配(BM25)和向量相似度,可以提升召回率。混合检索可以将搜索准确率提升高达45%。
结合多种检索器(BM25捕捉词法匹配、密集检索捕捉语义相似性)能提供互补的信号,显著增强RAG系统的有效性。
四、RAG的评估体系
RAG系统的评估是一个多维度的挑战。
Ragas(Retrieval Augmented Generation Assessment) 是目前最流行的开源评估框架,它引入了一套无需依赖人工标注的自动化评估指标,能够分别衡量检索和生成两个组件的质量。
4.1 三大核心评估指标
Ragas框架通过量化指标评估RAG系统的三大核心能力:
| 评估维度 | 衡量内容 | 计算公式/方法 |
|---|---|---|
| 忠实度(Faithfulness) | 生成的答案是否基于检索到的文档,有无幻觉 | LLM逐句判断与检索内容的逻辑一致性 |
| 答案相关性(Answer Relevancy) | 生成的答案是否直接回应用户问题 | 计算答案中问题相关句子的占比 |
| 上下文相关性(Context Relevancy) | 检索到的文档是否与问题相关 | 筛选文档中与问题相关的句子比例 |
4.2 总体得分计算
在Ragas框架中,各个指标会被组合起来计算出一个RAGAS总体得分,从而全面量化RAG系统的性能。
计算过程包括:选择相关指标并计算它们,将它们标准化为0-1范围,然后计算这些指标的加权平均值。
权重的分配取决于每个用例的优先级。
高级评估扩展:Ragas已被扩展到基于知识图谱的评估范式,支持多跳推理和语义社区聚类,以得出更全面的评分指标。
4.3 指标驱动开发(MDD)
Ragas框架引入了指标驱动开发(Metric-Driven Development) 的理念,用于持续改进RAG应用。
这意味着评估不是一次性的活动,而应该是贯穿整个开发周期的持续流程:建立基线 → 识别短板 → 针对性优化 → 重新评估 → 迭代循环。
五、RAG优化技术
在RAG的实际落地过程中,检索质量是影响最终效果最关键的因素。
以下是最有效的优化技术,每项技术都配有完整的代码示例。
5.1 查询重写(Query Rewriting)
问题场景:用户问“苹果股价咋样了?”,知识库里却是《Apple Inc. (AAPL) 2024年Q2财报与股价分析》。用户的口语表达与知识库的书面术语之间存在鸿沟,导致检索不准确。
优化思路:在检索前,让大模型充当“翻译官”,将用户口语化、模糊的查询改写为更专业、更完整的查询语句。
Spring AI Alibaba实现示例:
import org.springframework.ai.rag.preretrieval.query.transformation.RewriteQueryTransformer;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class QueryRewriteConfig {
@Bean
public QueryTransformer queryTransformer(ChatClient.Builder builder) {
String promptTemplate = """
你是一个专业的查询改写助手。请将用户的原始问题改写为更清晰、更完整的独立查询。
改写原则:
1. 将口语表达转为书面表达
2. 补全缺失的上下文信息(如代词指代)
3. 使用知识库中常用的专业术语
4. 保持查询的原始意图不变
原始问题:{original_query}
改写后的查询:
""";
return RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.promptTemplate(promptTemplate)
.targetSearchSystem("vector_store")
.build();
}
}
使用示例:
- 原始查询:“苹果股价咋样了?” → 改写后:“查询Apple Inc.公司的最新股票价格”
- 原始查询:“它怎么样?”(多轮对话中)→ 改写后:“查询上一轮提到的产品的详细功能”
效果:在电商客服场景中,实施查询重写后,多轮对话准确率提升超过30%,召回率从72%提升至89%。
5.2 混合检索(Hybrid Search)
问题场景:用户查询“ModelArts平台”,向量检索可能召回“机器学习”、“AI开发”等语义相近但不够精准的内容,而忽略了包含“ModelArts”关键词的文档。单一检索方式各有短板。
优化思路:同时使用BM25关键词检索(精确匹配)和向量语义检索(语义相似),将两种结果融合后返回,取长补短。
Spring AI Alibaba实现示例:
import org.springframework.ai.rag.retrieval.search.HybridDocumentRetriever;
import org.springframework.ai.rag.retrieval.join.JoinDocumentJoiner;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.rag.retrieval.search.KeywordDocumentRetriever;
@Configuration
public class HybridSearchConfig {
@Bean
public DocumentRetriever hybridRetriever(VectorStore vectorStore) {
// 向量检索器
VectorStoreDocumentRetriever vectorRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.7)
.topK(10)
.build();
// 关键词检索器(需要先对文档建立BM25索引)
KeywordDocumentRetriever keywordRetriever = KeywordDocumentRetriever.builder()
.indexName("knowledge_base")
.topK(10)
.build();
// 混合检索:使用 Reciprocal Rank Fusion 融合结果
return HybridDocumentRetriever.builder()
.retrievers(List.of(vectorRetriever, keywordRetriever))
.joiner(JoinDocumentJoiner.reciprocalRankFusion())
.build();
}
}
效果:混合检索可以将搜索准确率提升高达45%。在华为云社区实测中,结合查询重写+混合检索后,RAG系统的整体准确率从68%提升到91%。
5.3 结果重排序(Reranking)
问题场景:向量检索返回的10个结果中,第1个和第5个哪个更相关?相似度分数不一定准确。直接取Top-K可能漏掉真正相关的文档,或者把不相关的排在了前面。
优化思路:引入专门的重排序模型(如Cohere Rerank、BGE Reranker),对初步检索到的候选结果进行二次打分,按新分数重新排序。
Spring AI Alibaba实现示例:
import org.springframework.ai.rag.postretrieval.reranking.DiversityReranker;
import org.springframework.ai.rag.postretrieval.reranking.CompressionReranker;
import org.springframework.ai.rag.retrieval.search.DocumentRetriever;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
@Configuration
public class RerankingConfig {
@Bean
public DocumentRetriever rerankedRetriever(VectorStore vectorStore,
ChatClient chatClient) {
// 基础向量检索器,召回20个候选
VectorStoreDocumentRetriever baseRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.topK(20) // 多召回一些候选
.build();
// 重排序器1:多样性重排(避免返回的内容过于相似)
DiversityReranker diversityReranker = DiversityReranker.builder()
.minDegree(0.5) // 最小多样性阈值
.build();
// 重排序器2:压缩重排(用LLM提取最相关片段,可减少上下文长度)
CompressionReranker compressionReranker = CompressionReranker.builder()
.chatClient(chatClient)
.maxOutputTokens(500)
.build();
// 组合使用:先多样性重排,再压缩重排
return baseRetriever.andThen(diversityReranker).andThen(compressionReranker);
}
}
效果:在金融研报问答场景中,添加重排序后,答案的准确率从82%提升到94%,同时上下文长度压缩了60%,节省了Token成本。
5.4 多向量检索
问题场景:用户查询“华为云ModelArts平台与阿里云PAI平台的区别”,这是一个多跳推理问题,需要同时检索两个产品的信息并进行对比。单一的向量检索无法同时表达两个独立的语义实体。
优化思路:将查询分解为多个子查询,分别检索后再融合结果。或者使用多路检索器,分别从不同维度(文本语义、关键词、元数据)并行检索,然后合并。
Spring AI Alibaba实现示例:
import org.springframework.ai.rag.preretrieval.query.expansion.MultiQueryExpander;
@Configuration
public class MultiVectorConfig {
@Bean
public QueryExpander multiQueryExpander(ChatClient.Builder builder) {
String expansionPrompt = """
请将以下用户问题扩展为2-4个不同的子查询,每个子查询从不同角度表述,以覆盖更全面的信息。
子查询之间用换行分隔。
用户问题:{original_query}
扩展的子查询:
""";
return MultiQueryExpander.builder()
.chatClientBuilder(builder)
.promptTemplate(expansionPrompt)
.numberOfQueries(3) // 生成3个子查询
.build();
}
}
结合使用示例:
@Service
public class AdvancedRagService {
@Autowired
private QueryExpander queryExpander; // 查询扩展
@Autowired
private DocumentRetriever hybridRetriever; // 混合检索器
@Autowired
private Reranker reranker; // 重排序器
public String ask(String question) {
// 1. 查询重写
String rewritten = rewriteQuery(question);
// 2. 多向量扩展(生成多个子查询)
List subQueries = queryExpander.expand(rewritten);
// 3. 对每个子查询进行混合检索
List allDocs = new ArrayList<>();
for (String sq : subQueries) {
allDocs.addAll(hybridRetriever.retrieve(sq));
}
// 4. 去重 + 重排序
List uniqueDocs = deduplicate(allDocs);
List reranked = reranker.rerank(uniqueDocs, question);
// 5. 组装Prompt并生成答案
return generateAnswer(question, reranked);
}
}
效果:在多跳问答和产品对比类场景中,多向量检索可将召回率提升20-30%,尤其擅长处理“A与B的区别”、“为什么A比B好”这类复杂问题。
六、RAG实战
对于Java开发者,目前最成熟的选择是Spring AI Alibaba框架,它提供了模块化的RAG架构。
6.1 Spring AI Alibaba的RAG优势
Spring AI Alibaba作为阿里巴巴开源的AI开发框架,具有三大核心优势:
- 与阿里云生态深度集成:支持无缝调用通义千问等大模型,降低技术门槛
- 模块化设计:提供预处理、检索、生成、后处理等标准化组件,加速开发
- 企业级支持:内置高并发处理、模型热更新、监控告警等功能,适合生产环境
其核心思路是实现“检索-过滤-生成”的三段式流程:首先从知识库中检索相关文档片段,再通过语义过滤排除无关内容,最后由生成模型合成自然语言回答。
6.2 核心组件详解
Spring AI Alibaba的模块化RAG架构包含以下核心组件:
| 组件 | 功能 | 可选实现 |
|---|---|---|
| DocumentReader | 加载各类文档格式 | PDFMiner、Apache Tika、JSON、Markdown |
| DocumentTransformer | 文档预处理和清洗 | 去除特殊字符、元数据提取 |
| DocumentSplitter | 智能分块策略 | 递归分块、语义边界分块、重叠分块 |
| EmbeddingModel | 文本向量化 | DashScope、OpenAI、Ollama |
| VectorStore | 向量存储与检索 | Milvus、pgvector、Redis、Chroma |
| ChatClient | LLM调用与Prompt管理 | 通义千问、OpenAI、Azure |
6.3 完整代码实现
第一步:添加依赖
com.alibaba.cloud.ai
spring-ai-alibaba-starter
1.0.0
com.alibaba.cloud.ai
spring-ai-alibaba-starter-dashscope
1.0.0
第二步:配置向量数据库和Embedding模型
@Configuration
public class RagConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder
.defaultSystem("你是一个专业的智能问答助手,请基于提供的参考资料回答问题。")
.build();
}
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
// 示例:使用内存存储(适合原型验证)
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(embeddingModel).build();
return simpleVectorStore;
// 生产环境可替换为 MilvusVectorStore、PgVectorStore 等
}
@Bean
public EmbeddingModel embeddingModel() {
return new DashScopeEmbeddingModel(
DashScopeEmbeddingOptions.builder()
.withModel("text-embedding-v3")
.build()
);
}
}
第三步:构建知识库索引
@Service
public class KnowledgeBaseService {
@Autowired
private VectorStore vectorStore;
@Autowired
private EmbeddingModel embeddingModel;
public void indexDocument(String content) {
// 1. 文档切分
List chunks = DocumentSplitter.recursive(500, 100).split(content);
// 2. 向量化并存储
vectorStore.add(chunks);
System.out.println("已索引 " + chunks.size() + " 个文档块");
}
}
第四步:实现RAG问答接口
@RestController
@RequestMapping("/api/rag")
public class RagController {
@Autowired
private ChatClient chatClient;
@Autowired
private VectorStore vectorStore;
@PostMapping("/ask")
public String ask(@RequestParam String question) {
// 使用 QuestionAnswerAdvisor 自动完成检索增强
return chatClient.prompt()
.user(question)
.advisors(new QuestionAnswerAdvisor(vectorStore))
.call()
.content();
}
}
只需这几步,一个完整的RAG智能问答系统就搭建完成了!QuestionAnswerAdvisor会自动完成问题向量化、相似度检索和Prompt组装的全部工作。
七、RAG的优缺点
7.1 优点
-
准确率高:通过检索外部知识,大幅降低模型幻觉,提升事实准确性。RAG通过引入事实边界约束,要求LLM的答案严格基于检索到的权威文档,这在金融、医疗等合规敏感行业中至关重要。
-
知识实时更新:只需更新向量数据库即可,无需重新训练模型。通过外接动态知识库(如公司文档系统或新闻API),当用户查询最新信息时,RAG先检索外部数据库中的实时内容,再让LLM基于检索结果生成答案。
-
可解释性强:可以展示检索到的来源文档,让用户知道答案来源,具备可审计性。
-
成本可控:比微调大模型便宜得多,无需数百万美元的训练成本。
-
保护数据隐私:私有数据只存储在本地向量库中,不会上传到模型服务端。
-
领域适配灵活:将企业内部文档导入向量数据库,使通用LLM瞬间升级为领域专家。
7.2 缺点
-
检索质量决定一切:如果检索不到相关内容,LLM也无能为力。
-
上下文窗口限制:无法一次性塞入海量资料,需要合理切分。
-
增加系统复杂度:需要维护向量数据库、Embedding模型、LLM等多个组件。
-
延迟略高:相比直接调用LLM,RAG多了检索步骤,会增加几十到几百毫秒的延迟。
-
评估困难:RAG系统需要从检索准确性和生成质量多个维度进行综合评估。
-
知识冲突处理:检索到的信息可能与LLM的参数化记忆发生冲突,需要设计有效的融合策略。
八、RAG的使用场景
8.1 最适合RAG的场景
- 企业内部知识库问答:把公司的文档、规范、培训材料建成RAG,员工可以随时提问
- 智能客服系统:将产品文档、FAQ接入RAG,让AI客服能够准确回答产品问题
- 法律/合同审查:让AI基于合同文本回答问题,帮助律师快速定位条款
- 金融研报分析:分析师可以直接提问“这份研报中对XX公司的评级是什么”,AI基于报告内容回答
- 合规敏感行业:RAG通过强制LLM基于权威文档回答并附来源,在金融、医疗等合规敏感行业中至关重要
8.2 不适合RAG的场景
- 简单的闲聊:不需要外部知识的对话,直接用LLM就够了
- 需要深度推理的任务:RAG擅长“查资料”,不擅长“推导结论”
- 对延迟极度敏感的场景:检索会增加额外耗时
总结
RAG(检索增强生成)是目前企业落地AI应用最务实的技术方案。
它的核心价值可以概括为:让LLM带着资料回答问题,把AI幻觉降到最低。
| 核心要点 | 说明 |
|---|---|
| 核心公式 | RAG = 检索(Retrieval) + 增强(Augmented) + 生成(Generation) |
| 四大流程 | 索引 → 检索 → 融合 → 生成 |
| 关键技术 | 向量数据库 + Embedding模型 + 重排序 + LLM |
| 评估指标 | 忠实度 + 答案相关性 + 上下文相关性 |
| 优化方向 | 查询重写 + 混合检索 + 重排序 + 多向量检索 |
| 最佳实践 | 从简单起步,建立持续评估体系,逐步迭代优化 |
在Java生态中,Spring AI Alibaba提供了开箱即用的模块化RAG支持。通过遵循最佳实践,可以构建一个高效、可靠的RAG系统,为用户提供准确和专业的回答。
如果你正面临“AI答非所问”的困扰,不妨从RAG开始——这是目前成本最低、见效最快的解决方案。
未来已来,用好RAG,让AI真正成为你的得力助手。
原文地址: https://www.cveoy.top/t/topic/qGqo 著作权归作者所有。请勿转载和采集!