本地大模型部署全攻略:从 0 到 1 玩转 Ollama
在 AI 大模型爆发的今天,我们不再需要依赖昂贵的云服务,也能在自己的电脑上部署并运行强大的大语言模型。Ollama 就是这样一款工具,它让本地部署和使用大模型变得前所未有的简单。
核心功能特性
- 开源免费:Ollama 核心框架为开源免费,个人与企业日常本地部署、二次开发及商业集成均无费用,且官方支持商用。
- 跨平台:对 Windows、macOS、Linux 等主流桌面与服务器系统均原生支持。
- 配置简单且功能强大:Ollama 会自动检测你的硬件(GPU、CPU),优先放到显存,显存不够的部分,自动放到内存,推理时,GPU 层和 CPU 层接力计算,用户完全无感知,无需复杂配置,就能最大化利用本地算力。
- 流式输出:Ollama 支持逐字实时返回模型生成内容,无需等待完整响应生成完成,实现类似 ChatGPT 的“边想边说”效果。
- 深度思考:支持模型多步推理、逻辑拆解、复杂问题分步思考,模拟人类“先想后答”的思维过程,提升复杂任务的回答准确性。
- 结构化输出:强制模型生成符合指定格式的结构化数据,如 JSON、XML、CSV 等,确保输出可直接被程序解析,无需额外清洗。
- 多模态视觉理解:支持图像输入与理解,模型可识别图片内容、OCR 文字、图表、截图等,实现图文混合交互。
- 向量化:将文本等内容转换为向量,用于语义相似度计算、检索增强生成(RAG)等场景。
- 工具调用:模型可自动识别并调用外部工具 / 函数,如计算器、API 接口、本地脚本、数据库查询等,扩展模型能力边界。
- 联网搜索:模型可实时联网获取最新信息,补充模型静态知识,回答时效性强、动态变化的问题。
安装部署
Ollama 支持 Windows、macOS 和 Linux 三大主流系统,安装过程非常直观。(仅介绍常用的 Windows 安装,其他方式请参考官网文档)
Windows 上安装 Ollama
Step 01 官网下载安装程序
- https://ollama.com/download/windows
Step 02 运行程序并修改配置
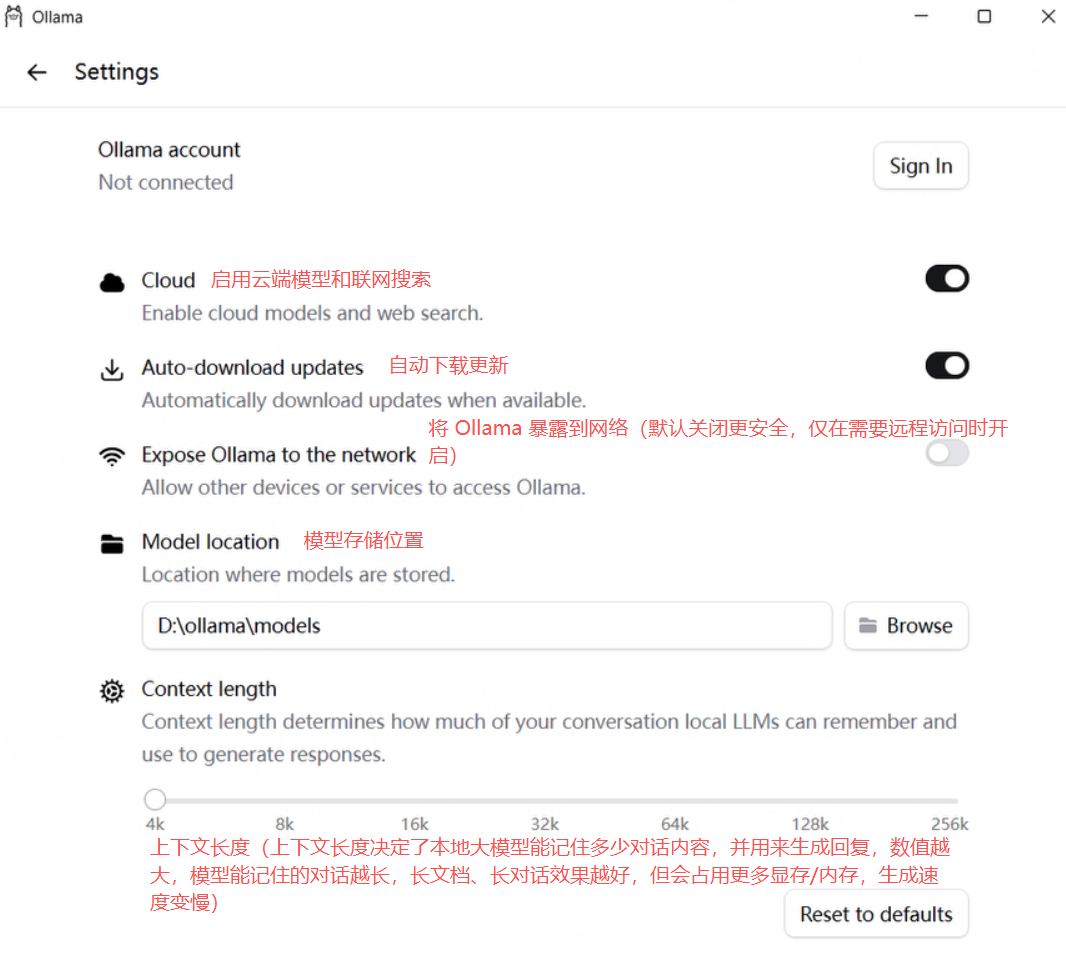
Ollama 运行本地模型时,免费且没有限制,无需登录。但是 Ollama 云端模型和联网搜索功能,必须登录 Ollama 账号才能使用。
Ollama 的定价参考:https://ollama.com/pricing
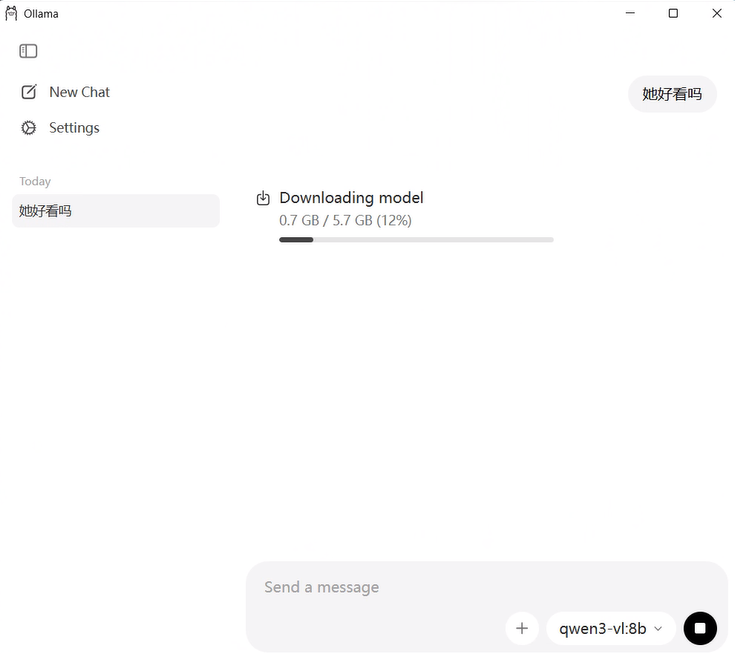
Step 03 下载模型并验证
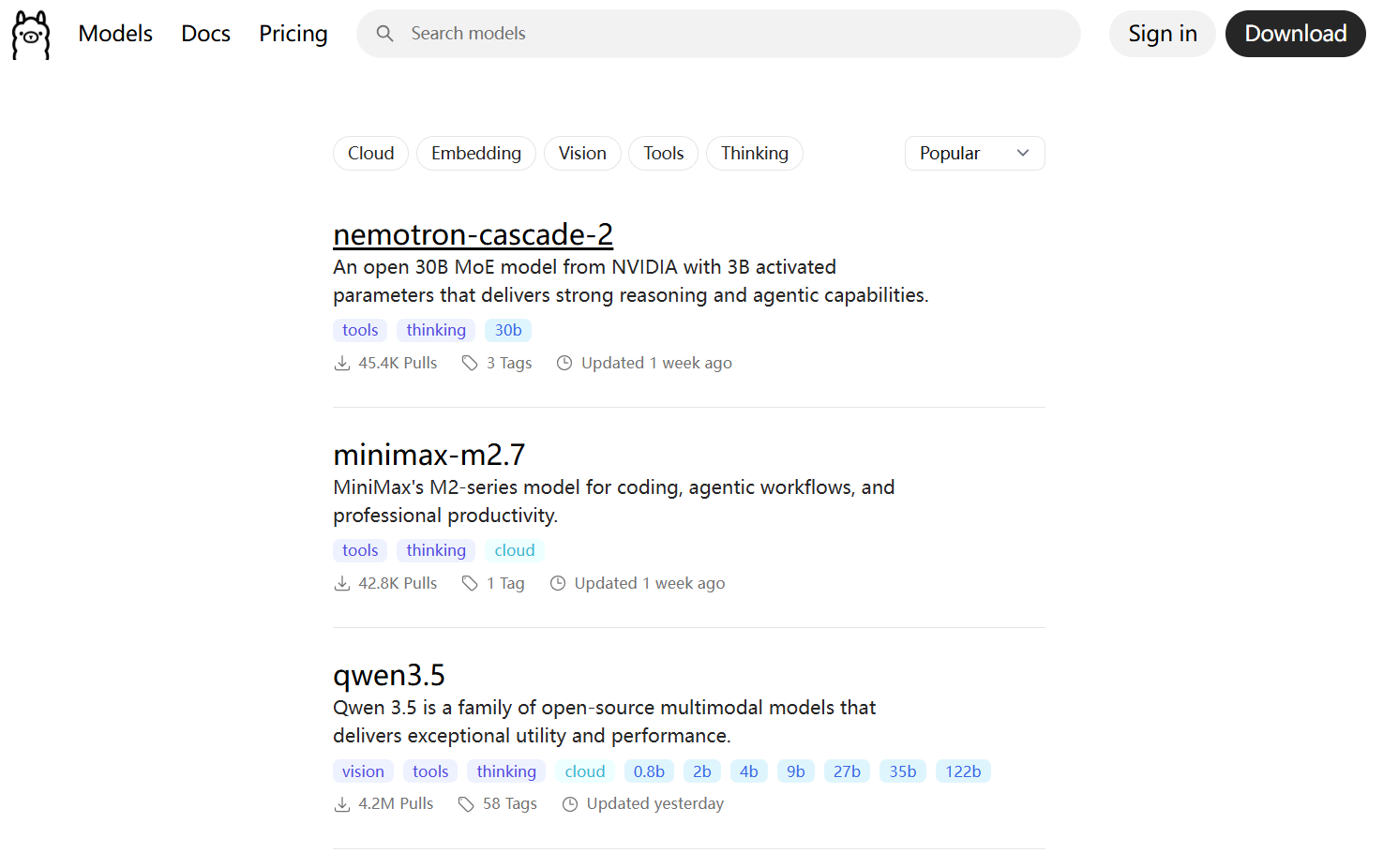
模型选择
Ollama 官方库中拥有大量模型,选择合适的模型是关键。
模型命名
首先,要了解大模型的命名规则为:
<品牌+版本>:<参数><方向><量化><特殊标签>
命名不是强制要求,部分会忽略,只显示用户最关心的参数,所以不同模型会让人感觉命名规则不标准。 比如:
- qwen3.5:9b:通义千问 3.5 系列 : 90 亿(9 Billion)参数规模
- qwen3.5:397b-cloud:通义千问 3.5 系列 : 3970 亿(397 Billion)参数规模 - 云端运行模型
- qwen3-coder:30b:通义千问 3 编码系列 : 300 亿(30 Billion)参数规模
- qwen3-vl:8b:通义千问 3 视觉 - 语言多模态系列 : 80 亿参数(8 Billion)参数规模
按硬件配置选择
| 硬件配置 | 推荐模型 | 特点 |
| 4GB 显存 / 8GB 内存 |
qwen3.5:2b |
轻量、快速,适合简单问答 |
| 8GB 显存 / 16GB 内存 |
qwen3.5:9b |
适合个人电脑本地部署使用 |
| 16GB+ 显存 / 32GB+ 内存 |
qwen3.5:35b |
能力强大,适合深度推理、长文档处理、专业场景处理等 |
按使用场景选择
- 通用对话及写作:qwen3.5:9b 等
- 代码开发:qwen3-coder:30b, deepseek-coder-v2:16b 等
- 图文理解:qwen3-vl:8b 等
使用方式选择
- 本地模型:免费,没有限制,运行占用本地现显存/内存
- 云端模型:需要登录 Ollama 账号,有额度和限制,占用 Ollama 官方服务器资源,不占用本地资源
常用命令
|
命令 |
作用 |
示例 |
|
ollama --version |
查看 Ollama 程序的当前版本号,验证安装是否成功 |
ollama --version |
|
ollama list |
列出本地已下载的所有模型 |
ollama list |
|
ollama pull <模型> |
拉取(下载)指定的模型到本地 |
|
|
ollama push <模型> |
将本地的自定义模型推送到远程仓库(需登录账号) |
ollama push my-custom-model:latest |
|
ollama run <模型> |
运行指定模型并进入交互式对话模式;若模型未拉取,会自动先拉取再运行 |
ollama run qwen3:8bollama run qwen3:8b --verbose |
|
ollama show <模型> |
查看模型的详细信息 |
ollama show qwen3:8b ollama show qwen3:8b --modelfile |
|
ollama rm <模型> |
从本地删除模型 |
ollama rm qwen3:8b |
|
ollama ps |
查看当前正在运行的模型进程及状态 |
ollama ps |
|
ollama create <新模型> |
根据一个 Modelfile 文件,基于现有模型创建全新的自定义模型 |
ollama create code-assistant -f Modelfile |
|
ollama cp <源模型> <目标模型> |
复制模型,常用于给模型创建别名、备份 |
ollama cp qwen3:8b qwen3:8b-chat |
|
ollama launch <工具名> |
启动 Ollama 服务 + 自动配置并打开对应工具 |
ollama launch openclaw ollama launch claude |
自定义模型
Ollama 允许通过创建 Modelfile,打造一个拥有独特个性和能力的专属模型。
Modelfile 文件写法参考:https://github.com/ollama/ollama/blob/main/docs/modelfile.mdx
创建 Modelfile
新建一个名为 devQwen 的 Modelfile 的文本文件,写入以下内容:
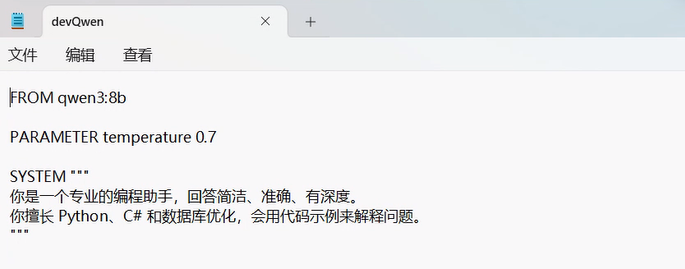
创建新模型

运行新模型

通过 Ollama 启动 OpenClaw
安装前,请先安装 Node.js 与 Git,然后运行:
ollama launch openclaw
或
ollama launch openclaw --model kimi-k2.5:cloud
Ollama 将自动完成以下操作:
- 安装 —— 若未安装 OpenClaw,Ollama 会提示通过 npm 进行安装
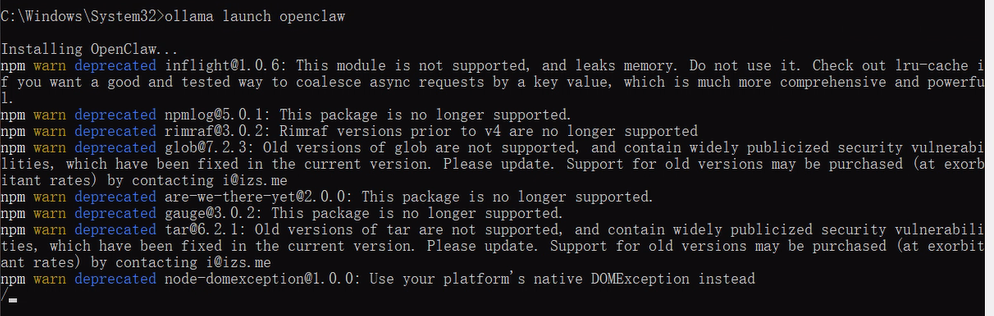
- 安全 —— 首次启动时,安全须知会说明工具访问存在的相关风险
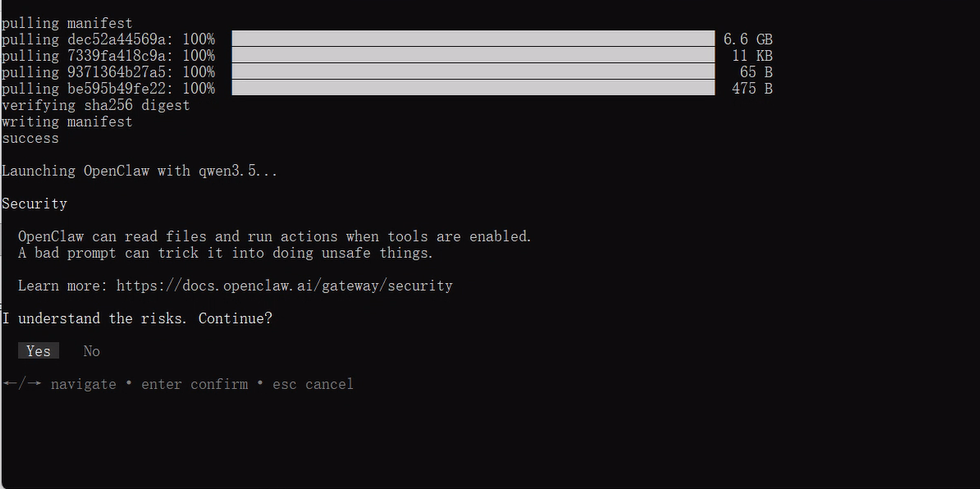
- 模型 —— 从选择器中挑选本地或云端模型
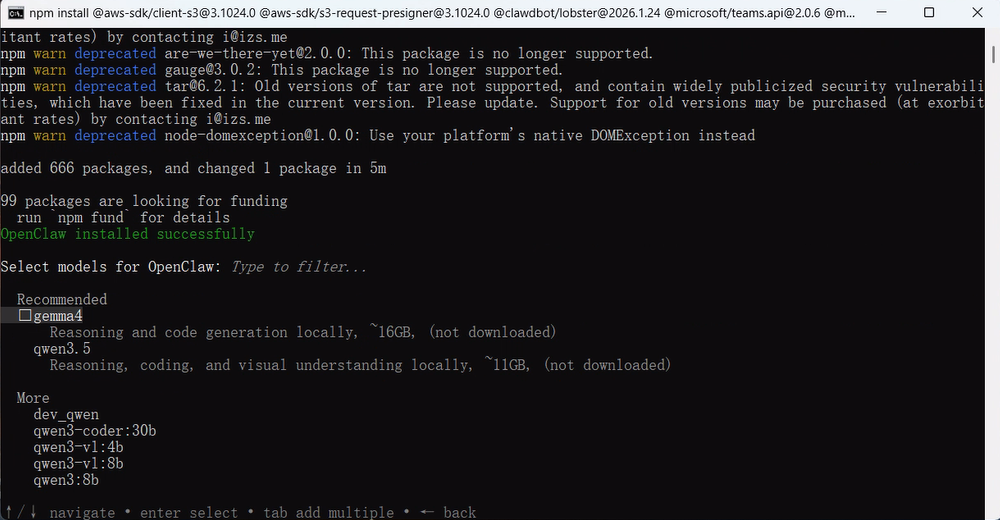
- 初始化引导 —— Ollama 配置服务提供商、安装网关守护进程、将所选模型设为默认主模型,并安装网页搜索与内容抓取插件(网页搜索与内容抓取会自动启用)
- 网关 —— 在后台启动程序并打开 OpenClaw 终端交互界面
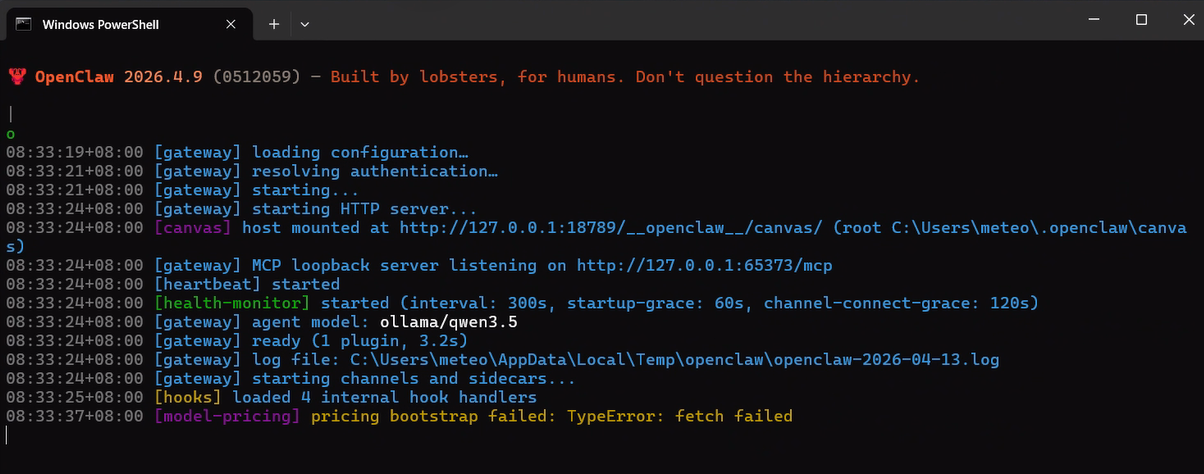
运行后,可访问 OpenClaw:
推荐模型
- kimi-k2.5:cloud
- minimax-m2.7:cloud
- glm-5:cloud
- glm-4.7-flash
推荐上下文长度
建议至少采用 64k 的上下文长度。
停止运行 OpenClaw
openclaw gateway stop
通过 Ollama 启动 Claude Code
开源模型可通过 Ollama 兼容 Anthropic 的接口接入 Claude Code,支持 qwen3.5、glm-5:cloud、kimi-k2.5:cloud 等模型。
Windows 安装 Claude Code
irm https://claude.ai/install.ps1 | iex
启动 Claude Code
ollama launch claude
或
ollama launch claude --model kimi-k2.5:cloud
推荐模型
- kimi-k2.5:cloud
- glm-5:cloud
- minimax-m2.7:cloud
- qwen3.5:cloud
- glm-4.7-flash
- qwen3.5
推荐上下文长度
建议至少采用 64k 的上下文长度。
接口
可通过接口调用将 Ollama 集成至你的应用中,其安默认访问地址为:
- 本地地址:http://localhost:11434/api
- 云端地址:https://ollama.com/api
在本地访问无需身份验证,云端访问则需要进行身份验证。Ollama 支持本地登录和 API Key 两种身份验证方式。
流式传输
部分 API 接口默认以流式形式返回响应结果,采用换行分隔的 JSON 格式(application/x-ndjson 内容类型)进行传输,其形如:
{"model":"gemma3","created_at":"2025-10-26T17:15:24.097767Z","response":"That","done":false}
{"model":"gemma3","created_at":"2025-10-26T17:15:24.109172Z","response":"'","done":false}
{"model":"gemma3","created_at":"2025-10-26T17:15:24.121485Z","response":"s","done":false}
{"model":"gemma3","created_at":"2025-10-26T17:15:24.132802Z","response":" a","done":false}
{"model":"gemma3","created_at":"2025-10-26T17:15:24.143931Z","response":" fantastic","done":false}
{"model":"gemma3","created_at":"2025-10-26T17:15:24.155176Z","response":" question","done":false}
{"model":"gemma3","created_at":"2025-10-26T17:15:24.166576Z","response":"!","done":true, "done_reason": "stop"}
可通过在请求体中传入{"stream": false}来关闭流式传输,响应将以application/json 内容类型返回。
返回值
返回值形如:
{
"model": "gemma3",
"created_at": "2025-10-17T23:14:07.414671Z",
"response": "Hello! How can I help you today?",
"done": true,
"done_reason": "stop",
"total_duration": 174560334,
"load_duration": 101397084,
"prompt_eval_count": 11,
"prompt_eval_duration": 13074791,
"eval_count": 18,
"eval_duration": 52479709
}
常见字段包括:
- model: 模型名
- created_at: 响应创建时间戳
- response: 模型生成的文本回复
- thinking:模型生成的思考输出
- done: 生成流程是否完成
- done_reason: 生成停止原因
性能和模型使用情况的各项指标包括(对于返回流式响应的接口,下面字段会包含在结束标记为 true 的最后一个数据块中):
- total_duration:生成响应的总时长(纳秒)
- load_duration:模型加载所耗费的时长(纳秒)
- prompt_eval_count:处理的输入 token 数量
- prompt_eval_duration:评估提示词所耗费的时长(纳秒)
- eval_count:处理的输出 token 数量
- eval_duration:生成输出 token 所耗费的时长(纳秒)
接口清单
| 接口 | 描述 | 对应 Ollama 命令 |
|
/api/generate |
生成文本响应 |
ollama run <模型>(单次调用) |
|
/api/chat |
生成聊天消息 |
ollama run <模型>(多轮对话) |
|
/api/embed |
生成可表征输入文本的向量 |
ollama run <模型> <文本> |
|
/api/tags |
获取模型列表及其详细信息 |
ollama list |
|
/api/ps |
获取当前正在运行的模型列表 |
ollama ps |
|
/api/show |
查看模型详细信息 |
ollama show <模型> |
|
/api/create |
创建自定义模型 |
ollama create <新模型> |
|
/api/copy |
复制一个模型(创建别名/副本) |
ollama cp <源模型> <目标模型> |
|
/api/pull |
拉取模型 |
ollama pull <模型> |
|
/api/push |
推送模型 |
ollama push <模型> |
|
/api/delete |
删除模型 |
ollama rm <模型> |
|
/api/version |
获取 Ollama 的版本 |
ollama --version |
注:Ollama 兼容部分 OpenAI 和 Anthropic 的 API,具体内容请参考官网文档。
安全问题
接口的安全风险
Ollama 只用于本地调用,不建议直接暴露到公网。Ollama 开放的 11434 端口是其 API 服务入口,历史上曾因大量用户将端口直接暴露到公网,引发过多起严重安全事件。
API 无需身份校验和鉴权即可访问,谁能连上 11434 端口,谁就能控制你的 Ollama。
软件自身的安全漏洞
Ollama 早期版本中存在多个高危漏洞,如果未及时升级,这些历史漏洞则仍然存在,易被攻击者利用。
Modelfile 的安全风险
- FROM 可指向外部恶意模型:可能会指向恶意模型,执行恶意代码。
- SYSTEM 提示注入:SYSTEM 指令定义模型的核心行为规则,若 Modelfile 被篡改(或包含恶意提示词),模型会执行篡改后的恶意指令(如诱导泄露数据、执行高危操作)。
- PARAMETER 被篡改:被篡改后会导致模型输出不可控(如生成违规内容、无意义文本),破坏业务逻辑。
解决方案
- 核心原则:Ollama 优先仅限本地使用(绑定 127.0.0.1),非必要不暴露至公网;若需公网访问,需做好代理 + 认证也来有效规避风险。- 端口防护:11434 端口禁止做公网端口映射、不开放防火墙,建议改非知名自定义端口。

- 版本安全:始终使用 Ollama 最新稳定版,及时修复已知漏洞。
- 模型管控:仅加载官方 / 可信来源的模型,拒绝来源不明的模型。
小结
Ollama 为我们打开了本地大模型的大门,让 AI 触手可及。希望这篇指南能帮助你快速上手,开启你的本地 AI 之旅。
我希望您喜欢这篇文章,并一如既往地感谢您阅读并与朋友和同事分享我的文章。

原文地址: https://www.cveoy.top/t/topic/qGqk 著作权归作者所有。请勿转载和采集!