嵌入式—ARM 架构简介
一、背景
1.1 为什么嵌入式场景选择 ARM
从智能家居到消费电子,从汽车领域到工业场景,嵌入式产品无处不在。嵌入式系统是以微处理器为核心、能够执行特定任务的专用硬件系统,通过对微处理器进行编程,使其适应特定应用场景的需求。根据应用场景选择合适的处理器,嵌入式产品既可实现如微波炉定时控制、智能灯定时开关等简单场景的功能,也能应用于车机、手机等复杂通用场景。
在嵌入式系统中,无论是物联网设备,工业控制板卡,智能终端设备还是高性能的移动SOC,ARM 几乎是事实上的标准架构。我们知道,除了 ARM,还存在 x86,RISC-V 等架构,那么为什么是 ARM 成为嵌入式应用的主流选择?该问题可以从架构设计,设备功耗,生态等角度来说明。
在之前介绍 x86 的文章中,对复杂指令集 CISC 和精简指令集 RISC 进行了详细介绍(点击此处查看)。简单来说,CISC 指令集通过让硬件提供功能丰富、长度可变的复杂指令来降低编程难度,但这样会导致指令执行周期长短不一,且功耗较高。而 RISC 精简指令集则只保留长度固定且执行效率最高的基础指令,将复杂操作交给软件(编译器)去组合实现,从而在提升执行效率的同时降低了功耗。简单来说,CISC 让硬件做复杂的工作,RISC 则让软件做复杂的工作,因此 x86 架构(CISC)擅长高性能计算,而 ARM 架构(RISC)则更适合对功耗敏感的嵌入式与移动设备。
结合嵌入式设备的应用场景——不连接高功率电源,通常工作在低功率场景,使用电池供电,并且设备体积通常较小,要求集成度高或者便携性好,无法使用大体积散热材料和设备,因此嵌入式设备的功耗控制非常重要。而 ARM 架构在设计上天然偏向低功耗,这也是为什么在当前时代,几乎所有智能手机 SoC 都采用 ARM 架构。
ARM 的独特授权模式和其在生态上的覆盖和统一性,是其统一嵌入式世界的关键。我们知道,国内外存在大量的芯片设计(嵌入式芯片)公司,如苹果,高通,恩智浦,意法等。如果经常关注手机测评就会知道,这些芯片设计厂商的产品通常使用的都是 ARM 的内核。也就是说,ARM 公司本身并不生产芯片,而是进行 IP 核的设计,并将其授权给此类芯片设计厂商。厂商拿到 ARM 授权的内核,在此基础上结合自己的外设模块(GPU,NPU,IO等)进行后端布局设计,从而得到自家的 SOC 产品。此种商业模式降低了设计公司的开发难度,因此大量公司依赖此种买授权的方式进入市场,ARM 架构的应用和规模得以扩张覆盖。不同厂商的芯片使用同一指令集架构构成了生态上的统一,基于 ARM 平台的软件产品能够在不同平台上大量兼容,Linux,RTOS操作系统可以轻松跨平台移植,这是 ARM 能在嵌入式领域形成事实标准的决定性因素。
随着时间的推移,围绕 ARM 架构逐步形成了成熟的软件生态体系。主流编译器工具链、实时操作系统以及 Linux 内核均长期支持 ARM 平台,启动加载程序和调试工具也围绕 ARM 架构进行了深度适配。当一种架构形成完整的软件、工具与社区支持体系后,新项目在技术选型时往往会优先考虑生态成熟度较高的方案,这种正反馈进一步巩固了 ARM 在嵌入式领域的地位。此外,ARM 架构在设计上具有较强的可扩展性和可裁剪性。从资源极其受限的微控制器到运行复杂操作系统的应用处理器,ARM 提供了不同层级的核心设计方案,使开发者可以在统一架构体系下完成不同性能等级产品的开发。这种分层清晰、定位明确的体系结构,使工程师能够在不同应用场景之间平滑迁移技术经验,降低学习和开发成本。
1.2 ARM 发展历程
ARM 最初起源于英国公司 Acorn Computer 在个人计算机项目中的处理器研发工作。1985 年,该公司推出第一款 ARM 处理器 ARM1,叫做 Acorn RISC Machine。ARM 采用精简指令集设计思想,结构简单,功耗低,当时主要作为内部实验性处理器,未大规模商业化。随后推出的 ARM2 和 ARM3 逐渐完善了架构设计,并开始应用于 Acorn 的计算机产品中。
1990 年,Advanced RISC Machines (ARM) 公司由 Acorn Computers、Apple Inc. 和 VLSI Technology 共同成立。与传统半导体厂商不同,ARM 公司并不直接生产芯片,而是专注于处理器架构设计,并通过 IP 授权的方式向其他厂商提供处理器内核。这种商业模式使得 ARM 架构能够迅速被不同厂商采用,并逐渐在嵌入式领域形成规模化生态。
90 年代,ARM 架构经历了多次迭代,如 ARMv3、ARMv4 等,以 32 位处理器为主。典型的代表包括 ARM7 和 ARM9 系列。随着移动通信和消费电子的发展,ARM 架构在低功耗和高效率方面的优势逐渐显现,大量手机和嵌入式设备开始采用 ARM 处理器。
进入 21 世纪后,ARM 架构进一步扩展,形成更为清晰的产品体系。在 ARMv7 推出后,公司提出了 Cortex 系列处理器。Cortex-A 系列面向高性能应用处理器,主要用于智能手机和运行 Linux 等操作系统的平台。Cortex-R 系列面向实时控制系统,常见于工业控制和汽车电子领域。Cortex-M 系列则针对微控制器市场,广泛应用于物联网设备和嵌入式控制系统。ARMvx 是指指令集架构版本,Cortex 是指基于 ARMvx 指令集的内核(RTL级)。Cortex-X 是 Arm 自己造的参考设计,厂商可以买授权直接用或改。
2011 年发布的 ARMv8 指令集首次引入了 64 位架构 AArch64,同时兼容 32 位。ARMv8 的推出使 ARM 处理器具备了进入服务器和高性能计算领域的能力。此后,基于 ARMv8 的处理器被广泛应用于移动设备和数据中心平台,例如 Apple 的 M 系列处理器以及多种 ARM 服务器芯片。
如今 ARM 架构面向高性能和安全计算方向发展。ARMv9 架构在 ARMv8 的基础上进一步强化了安全机制、向量计算能力以及人工智能相关扩展,以适应云计算、边缘计算和智能终端的发展需求。
| 时间 | 关键事件 / 架构版本 | 说明与代表产品/意义 |
|---|---|---|
| 1978 | Acorn Computers 成立 | Chris Curry & Hermann Hauser创立,后获得BBC Micro项目(英国教育计算机计划) |
| 1983–1984 | ARM项目启动 | Sophie Wilson(指令集)+ Steve Furber(微架构)在Acorn内部启动Acorn RISC Machine项目 |
| 1985.4.26 | ARM1 第一颗硅片成功运行 | 3μm工艺、25K晶体管、26位地址空间、3MHz,原型验证RISC低功耗思路(经典生日) |
| 1986–1987 | ARM2、ARM3 | ARM2用于BBC Master第二处理器;ARM3加入4KB cache;首款商用机Acorn Archimedes (1987) |
| 1990.11 | Advanced RISC Machines Ltd. 成立 | Apple + Acorn + VLSI Technology 合资创立(Apple为Newton PDA找低功耗方案) |
| 1991 | ARM6 | 完整32位地址空间 + MMU,奠定后续基础 |
| 1993–1994 | ARM7TDMI | 经典中的经典!加入Thumb 16位压缩指令集,TI成为重要伙伴;Nokia 6110 (1997)大卖 |
| 1998–2001 | ARM9系列、ARM926EJ-S | 进入智能手机早期阶段,出货量爆发(累计50亿颗级别) |
| ~2002 | ARMv6 | 引入SIMD多媒体指令(后来发展成NEON的前身) |
| 2004–2005 | ARMv7-A 发布,Cortex品牌诞生 | 彻底改变命名方式:Cortex-A8 (2005)、A9 (2007)、A15 (2011) 等成为智能手机主力 |
| 2011 | ARMv8-A 发布(64位) | 引入AArch64(64位执行态)+ AArch32,向后兼容;Apple A7(iPhone 5s)第一个商用 |
| 2012–2013 | Cortex-A53/A57 | 第一代64位移动SoC大规模商用(高通、三星、MediaTek等跟进) |
| 2016–2017 | ARMv8.2-A、ARMv8.3-A | 增加更多安全、虚拟化、性能特性;手机SoC全面转向64位 |
| 2019–2021 | Neoverse 品牌正式发力 | 针对服务器/数据中心:Neoverse N1 (2019)、N2、V1、E1等;AWS Graviton、Ampere、富士通等采用 |
| 2021 | ARMv9-A 发布 | 强制SVE2向量扩展、MTE内存标签扩展、更强安全(Confidential Compute)、性能提升 |
| 2022–2023 | Cortex-X3/X4、A720、A520 | Armv9.0/9.2世代,性能/能效双提升;苹果M系列、Qualcomm Oryon等继续推高天花板 |
| 2024–2025 | Neoverse V3、N3、CSS(计算子系统) | 服务器性能逼近甚至部分超过x86;Arm出货量累计超2500–3000亿颗 |
| 2025.4 | Arm架构诞生40周年 | 从ARM1到如今统治几乎所有低功耗与移动计算领域 |
*表格由 ChatGPT 总结
二、ARM 架构组成
在嵌入式或计算机系统中,我们的软件程序依托于以中央处理器(CPU)为核心的硬件电路来运行。CPU 是系统的核心计算与控制器件,负责执行程序指令并协调各个硬件模块的功能。对计算机比较了解或者喜欢装机的朋友都知道,装机需要的核心部件有:CPU,内存,硬盘,显卡以及主板。其中CPU,内存,硬盘,显卡都需要嵌入到主板上,CPU 作为控制核心,其他主要部件都需要与 CPU 进行通信,主板就负责这些通信线路的连接,早期主板上会有南北桥芯片,负责 CPU 与器件间的 IO,如今北桥芯片已经被集成在 CPU 内部,南桥芯片如今叫做 PCH 或者芯片组芯片,这是 PC 的主要结构。嵌入式设备主板虽有简化,但是主要结构是类似的。一块没有烧录程序的板卡是没有灵魂的,我们编写的嵌入式程序一般放在非易失性存储器中,程序要执行时,首先会将程序文件从磁盘加载到内存中,然后 CPU 对从内存中提取指令和数据,进行取指,译码,执行等操作来完成特定任务,我们编写的嵌入式程序最终都是在 CPU 上运行。依照功能的不同,CPU 由不同的功能单元构成:控制单元,算术逻辑单元,寄存器组,高速缓存和总线等。
控制单元的主要作用是从内存中提取指令并译码,控制信号生成及流水线调度等。它会根据当前执行的指令的类型来控制寄存器的读写,ALU 运算,访存等操作,保证处理器按照规范的指令流行运行。
在控制器进行取指和译码后,指令执行单元会执行该指令。需要注意的是,在现代处理器中,ALU 是指令执行单元的运算组件,负责具体的算数或逻辑运算,是实际的执行电路,此外指令执行单元还包括专门处理浮点运算的 FPU 等;早期的 8086 处理器中,指令执行单元几乎等同 ALU。
寄存器组的作用是存储 CPU 正在处理的操作数,运算结果和状态,保存指令地址等。寄存器组是 CPU 访问速度最快的存储单元。ARM 架构的寄存器组通常包括多个通用寄存器,以及保存指令地址的程序计数器 PC 和记录处理器状态的程序状态寄存器 CPSR等。CPU 的指令执行速度是非常快的,但是外部存储器的访问速度又很慢,寄存器组的存在能够减少 CPU 对外部存储器的访问,提高指令执行效率。
高速缓存通常是指 CPU 中的一级缓存 L1,二级缓存 L2等,经常关注芯片测评的应该不陌生。整个计算机存储系统中,速度从快到慢依次为寄存器,高速缓存 Cache,内存(DDR),磁盘(Flash)。CPU 的执行速度是非常快的,但是相对于 CPU,内存的速度非常慢,如果每次取指和访存都要访问内存,那 CPU 资源会造成极大的浪费,Cache 就是为了解决这个问题。Cache 用于暂存近期访问的指令和数据,减少访问主存带来的系统延迟,从而提升系统性能。
接下来我们以 Cortex-A7(基于 ARMv7-A)为例,阐述 ARM 架构的一些主要内容。
2.1 寄存器组与工作模式
ARM 处理器设计了多种工作模式,这一设计主要出于系统安全、异常处理和任务管理的考虑。在发生中断或异常时,处理器能够切换到对应的工作模式,这些模式拥有独立的堆栈空间和部分专用寄存器,可以快速保存和恢复现场,提高模式切换效率。同时,不同模式具有不同的特权级别,特权模式可以访问所有系统资源,而非特权模式的访问受到限制,通过这种权限分级实现关键数据与系统状态的隔离保护,确保系统运行的安全可靠。
以 Linux 操作系统为例,系统运行分为用户态和内核态两种特权级别。内核态运行在 ARM 处理器的特权模式下(主要为 SVC 模式),具有最高访问权限,可以直接访问 CPU 寄存器、内存管理单元、外设 I/O 等所有硬件资源。用户态运行在 ARM 处理器的用户模式(User Mode)下,访问权限受限,无法直接操作硬件,必须通过系统调用机制切换到内核态,由内核代为完成对硬件资源的访问。这种权限分级设计,通过系统调用作为唯一的合法访问通道,既保证了数据安全性,又维护了系统稳定性,而 ARM 处理器的多模式支持为操作系统实现这种权限分级提供了硬件基础。举例来讲,假设我们使用 USB 接口的设备传输数据,Linux 内核驱动程序负责接收硬件设备传输过来的数据,而应用程序只需要通过系统调用 read()(姑且看作一个函数)从对应的设备文件中读取这些数据。
| 特性 | 用户态 | 内核态 |
|---|---|---|
| 权限级别 | 低 | 高 |
| 内存访问 | 仅限用户空间 | 全部内存空间 |
| 指令执行 | 普通指令 | 所有指令(包括特权指令) |
| 硬件访问 | 不能直接访问 | 可以直接访问 |
| 资源限制 | 受限制 | 无限制 |
2.1.1 ARM 处理器工作模式
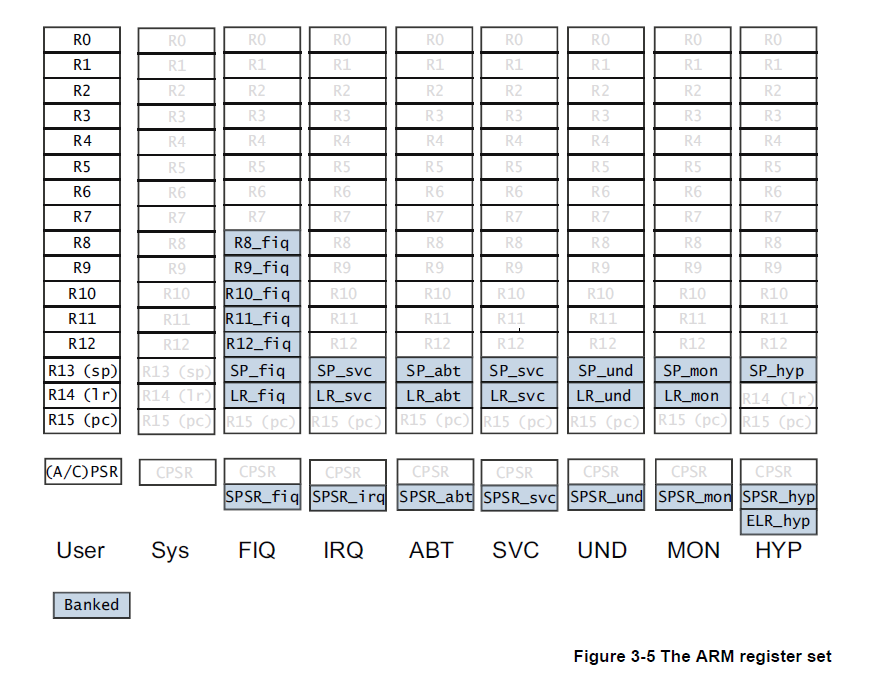
下表是 Cortex-A7 内核的 9 种工作模式。这些模式通过 CPSR 寄存器(见下一节)的特定位编码来区分。除了 USR 模式是非特权模式之外,其余均为特权模式。每个模式都有自己独立的栈指针和部分 banked(2.1.2节图示) 寄存器,异常发生时 CPU 会自动切换模式并保存现场。接下来逐一说明每种模式和实际应用举例。
| 模式名称 | 缩写 | 类型 | 主要功能 |
|---|---|---|---|
| User Mode | USR | 非特权模式 | 普通应用程序运行模式,权限最低 |
| Fast Interrupt Mode | FIQ | 特权模式 | 处理高速中断,拥有更多独立寄存器以提高响应速度 |
| Interrupt Mode | IRQ | 特权模式 | 处理普通硬件中断 |
| Supervisor Mode | SVC | 特权模式 | 操作系统内核模式,系统启动和系统调用时进入 |
| Abort Mode | ABT | 特权模式 | 处理存储访问异常(如数据或指令访问错误) |
| Undefined Mode | UND | 特权模式 | 处理未定义指令异常 |
| System Mode | SYS | 特权模式 | 与User共享寄存器,但具有特权级权限,供操作系统使用 |
| Monitor Mode | MON | 特权模式 | TrustZone安全扩展模式,用于安全世界切换 |
| Hypervisor Mode | HYP | 特权模式 | 虚拟化扩展模式,用于运行虚拟机监控程序 |
用户模式 USR:普通应用程序执行时处理器所处的模式,权限最低,无法访问硬件寄存器等底层资源。Linux 操作系统中几乎所有的用户态进程都运行在此模式下。比如在终端执行ls,code等命令时,CPU 就在 USR 模式下执行用户代码。用户态程序可通过系统调用的方式访问底层数据(相当于内核态程序给应用态程序的访问接口)。
快速中断模式 FIQ:专门为高优先级、实时性要求极高的中断场景设计。Linux 可把部分中断路由到 FIQ(通过通用中断控制器 GIC 配置)。FIQ 模式拥有最多的 banked 寄存器(如 R8–R14 的独立副本),因此在进入中断处理时可以直接使用这些专用寄存器,而无需保存原有寄存器内容,从而显著减少现场保护的开销。具体来说,假设当前处理器工作在 USR 模式,当快速中断发生时,处理器会立即切换到 FIQ 模式,并使用专用的 R8_fiq–R14_fiq 寄存器。如果没有这种 banked 寄存器机制,中断处理程序就需要先将原寄存器内容保存到内存,再进行中断处理,这会增加额外的访存开销,降低中断响应速度。因此,FIQ 模式通过提供更多独立寄存器,提高了中断处理的实时性和响应效率。
普通中断模式 IRQ:用于处理通用中断控制器(GIC)产生的普通外部中断。Linux 内核中断处理主要就是工作在 IRQ 模式下。当外设产生中断请求时,处理器会暂停当前正在执行的程序,自动保存必要的运行状态,从当前模式切换到 IRQ 模式执行中断服务程序,该模式使用 banked 寄存器(R13_irq 和 R14_irq)来保存返回地址(中断处理完成后返回原本的指令执行位置)和栈指针(原来进程上下文和当前中断上下文是独立栈空间,栈指针用于保存进程上下文栈指针),从而减少保护线程的开销。当中断服务程序执行完成后,处理器会恢复原来的运行状态并返回到被中断的程序继续执行。IRQ 模式主要用于处理一般优先级的中断事件,是系统中最常见的中断处理模式。
SVC 模式:操作系统内核运行的主模式。当用户程序需要请求操作系统服务(系统调用)时,可以通过执行 SVC 指令触发异常,使处理器从用户模式切换到 SVC 模式,由内核完成相应的系统服务。ARM处理器上电或复位后进入的第一个模式也是 SVC。此时,CPU会从特定地址开始执行启动代码(如 Bootloader),为加载操作系统做准备。
中止模式 ABT:在深入理解 ARM 处理器的中止模式(ABT)之前,有必要先了解内存管理单元(MMU)的基本工作原理。MMU 负责将操作系统使用的虚拟地址转换为实际的物理地址。每个运行在 32 位 ARM 处理器上的进程都拥有独立的 4GB 虚拟地址空间,而物理内存的容量可能远小于所有进程虚拟空间的总和(例如仅有 8GB)。通过虚拟内存机制,每个进程的虚拟地址空间只有部分内容真正驻留在物理内存中,其余部分可存储在磁盘等外部存储器上,这既保证了多任务并发,又突破了物理内存容量的限制。当处理器试图访问一个虚拟地址,而该地址对应的页表项不存在或权限不足时,MMU 无法完成地址转换,便会触发一个中止异常(Abort)。根据异常发生的阶段,可分为指令预取中止(Prefetch Abort)和数据访问中止(Data Abort)。此时,处理器硬件自动完成以下操作:切换到 ABT 模式(专门用于处理存储器访问失败的情况);将返回地址保存到链接寄存器 LR_abt,并将当前程序状态寄存器(CPSR)保存到 SPSR_abt;跳转到相应的异常向量表入口,执行软件定义的中止处理程序。在典型的 Linux 操作系统中,数据访问中止的处理程序会根据中止原因进行判断:若属于合法的缺页(如尚未分配物理页框),则分配物理内存并建立页表映射,然后从异常返回,重新执行引起异常的指令;若为非法访问(如访问未授权区域),则向当前进程发送段错误信号(SIGSEGV)。整个过程中,硬件进入 ABT 模式仅完成了异常的初步捕获和现场保存,真正的映射建立或错误处理由操作系统内核在异常处理程序中完成。
未定义指令模式 UND:ARM 架构支持特定的指令集,如果处理器在执行到指令集未定义的指令时就会触发未定义指令异常,然后进入到 UND 模式执行响应的异常处理程序。
系统模式 SYS:该模式与 USR 模式使用完全相同的寄存器组,但具有特权级权限,因此可以访问系统控制寄存器和执行特权指令。该模式的设计目的是让 OS 能在不切换 banked 寄存器的情况下运行特权代码,在 Linux 内核中几乎不用,仅作了解。
监控模式 MON:该模式是 ARM 处理器在启用安全扩展(TrustZone)时提供的一种特权模式,主要用于管理 安全世界(Secure World)与普通世界(Normal World)之间的切换。当系统发生安全监控调用(SMC)或需要进行安全状态切换时,处理器会进入 MON 模式执行监控程序(Monitor)。在该模式下,处理器具有最高级别的控制权限,并拥有独立的栈指针和链接寄存器(R13_mon、R14_mon),用于保存运行状态并完成安全上下文的切换。通过 MON 模式,系统能够实现安全资源隔离和可信执行环境,从而提高整体系统的安全性。
虚拟管理模式 HYP:该模式是 ARM 处理器在支持虚拟化扩展时提供的一种特权工作模式,主要用于运行虚拟机监控程序(Hypervisor)。在虚拟化系统中,HYP 模式位于多个操作系统之上,负责管理和调度各个虚拟机,并控制它们对硬件资源(如 CPU、内存和外设)的访问。当虚拟机执行某些特权操作或需要进行资源管理时,处理器可以陷入 HYP 模式,由虚拟机监控程序进行处理。在该模式下,处理器具有较高的控制权限,并使用独立的寄存器资源来保存运行状态,从而实现对虚拟化环境的高效管理和隔离。
*后三者仅作了解即可。
2.1.2 ARM 处理器寄存器组
上一节介绍了 Cortex-A7 内核的 9 种工作模式,每种模式都对应的有一组寄存器,如下图所示。图中浅色的寄存器表示多种模式公用,Banked 寄存器表示是各模式的私有寄存器。Cortex-A7 内核一共有 43 个寄存器,每个寄存器有 32 位。寄存器根据是否在不同处理器模式下拥有副本分为未分组寄存器(Unbanked Registers)和分组寄存器(Banked Registers)。
未分组寄存器(Unbanked Registers)是指在所有处理器模式下共用同一物理寄存器的一组寄存器。当处理器从一种模式切换到另一种模式时,这些寄存器的内容不会发生变化,各个模式访问的都是同一组寄存器。例如在 ARM 体系结构中,R0–R7 通常属于未分组寄存器,因此无论处理器处于用户模式还是中断模式,这些寄存器的内容都是一致的。
分组寄存器(Banked Registers)是指在不同处理器模式下拥有独立副本的寄存器。当处理器进入某些特权模式(如 IRQ、FIQ、SVC 等)时,会自动切换到该模式对应的寄存器副本。这样可以在发生中断或异常时避免频繁地将寄存器内容保存到内存,从而减少现场保护的开销并提高响应速度。例如,FIQ 模式拥有独立的 R8_fiq–R14_fiq,而 IRQ、SVC 等模式通常具有独立的 R13(栈指针)和 R14(链接寄存器)。
未分组寄存器主要用于不同模式之间共享数据,而分组寄存器则用于提高异常处理效率和减少寄存器保存开销。
分组寄存器中有三个特殊的寄存器(R13~R15),以及 CPSR/SPSR 寄存器,下面我们逐个详细讲解。
-
R13(SP)栈指针寄存器
在讲解栈指针之前,全面描述一下一个进程的内存布局是什么样的,栈是什么,用来存放什么样的数据,这样更加深入全面地理解栈指针,否则单一概念显得太单薄。首先一个可执行程序在运行时,其内存布局如下图所示:

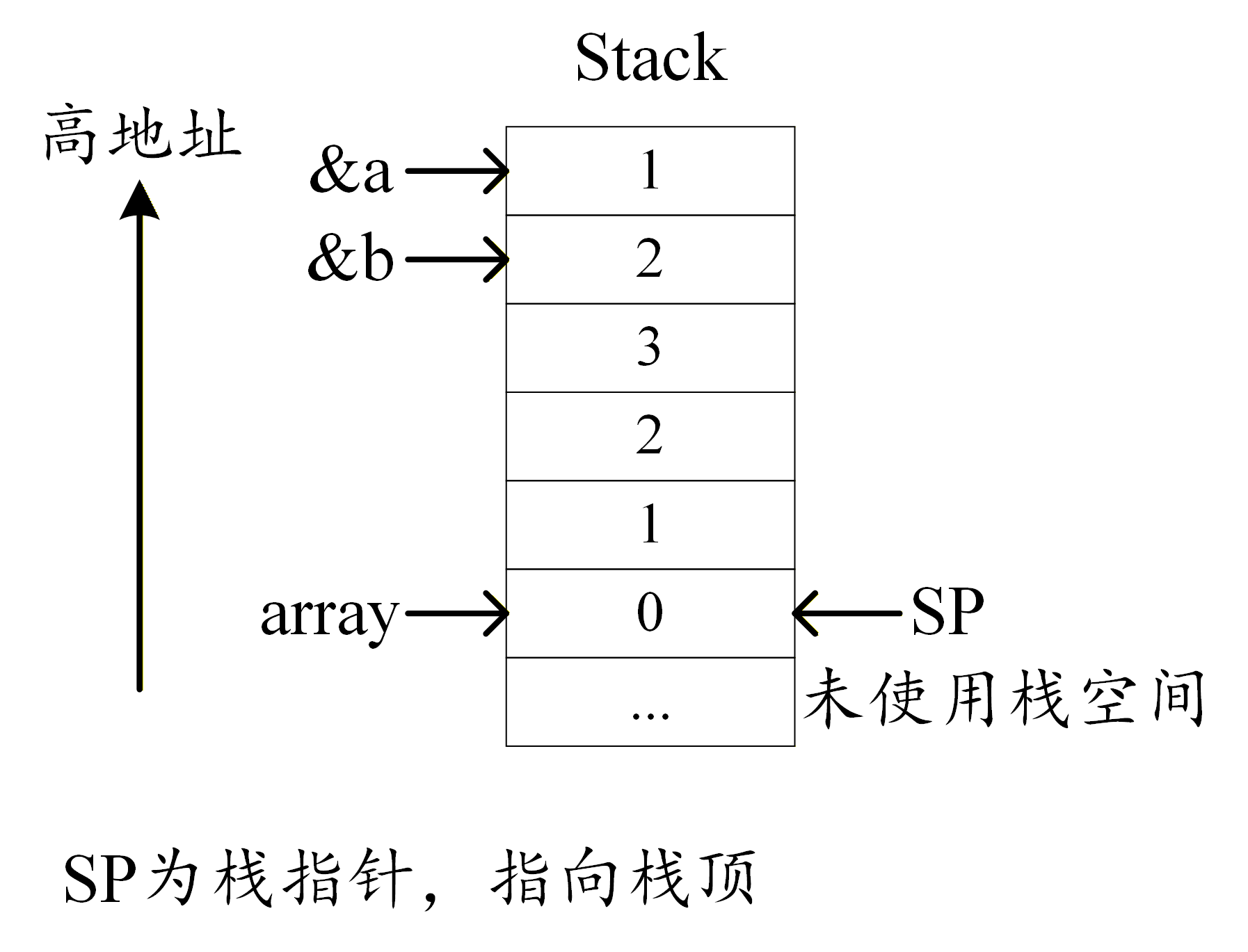
栈是一种先入后出的数据结构,先进入的数据位于栈底,后进入的数据位于栈顶。以进程上下文为例,每个进程都拥有自己的栈空间,用于存储函数中的局部变量。以一个函数为例
void func() { char a = 1; char b = 2; char array[4] = {0, 1, 2, 3}; }该函数局部变量在栈中的分布如下图所示。R13 也就是 SP 栈指针寄存器指向当前 CPU 正在执行的进程的栈空间的栈顶。将数据保存进栈空间的动作叫做压栈(push),将数据从栈空间删除的操作叫做弹栈(pop)。压栈时,先将 SP+n 再压入数据,弹栈时,先将 SP-n 再弹出数据。
栈帧就是一个函数所使用的一块栈空间,也就是从这个函数压入第一个数据(栈帧基址)到函数压入的最后一个数据之间的栈空间。通常使用帧指针 FP 指向栈帧基址,如果函数中再调用子函数的话,子函数首先要把父函数的 FP 压入子函数栈底,然后 FP 赋值为当前子函数的栈基址,子函数运行完成后,再把刚才压入的父函数 FP 赋值给帧指针。FP 没有专门的寄存器,通常使用 R11 或 R7。
-
R14(LR)链接寄存器
链接寄存器(LR)用于存储子程序调用或异常触发时的返回地址,即执行完子函数或异常处理程序后,需要继续执行的原始程序位置。也就是说,在程序需要跳转执行时,将当前指令的下一条指令的地址写入 LR,在跳转执行完成后,将 LR 中保存的指令地址再赋值给 PC 接着执行。对于常规函数调用,LR 用于保存函数返回地址,从而避免使用栈来保存返回地址(除非发生嵌套调用),大大提升了执行效率。当系统发生异常(如 IRQ 中断、FIQ 快速中断、SVC 系统调用、ABT 中止等)时,硬件会将特定的返回地址自动保存到对应异常模式的链接寄存器中,比如发生IRQ中断时,返回地址保存到
R14_irq。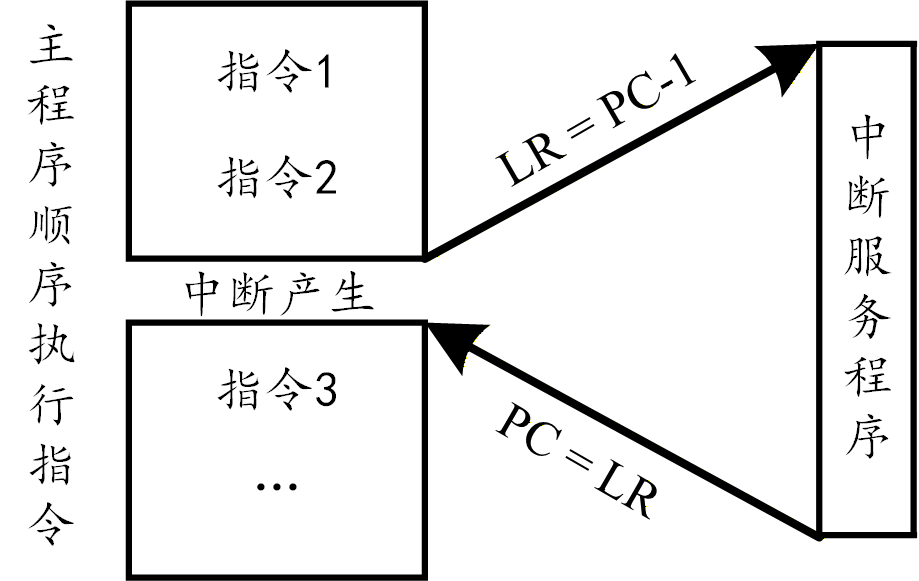
-
R15(PC)程序计数器
PC 寄存器用于保存当前正在执行或即将执行的指令地址。处理器在执行程序时,会按照 PC 中的地址从存储器中取指令,并在每条指令执行完成之后自动更新 PC 的值,从而实现程序的顺序执行。当发生跳转指令或者异常、中断时,PC 的值会被修改,使程序跳转到新的地址继续执行。执行完成之后将原本的指令地址重新赋值给 PC 继续顺序执行。
下一节中,我们将会详细介绍 ARM 处理器的流水线结构。在介绍 ARM 处理器的流水线结构之前,我们可以先来看一个生活中的生产场景,以此理解流水线设计的核心思想。假设有一个产品的制作需要依次经过三道完全不同的工序。如果我们采用最原始的方式,即由完成某个产品的所有工序后,再开始下一个产品。那么,在产品流转的间隙,工人和机器不可避免地会有空闲时间,生产效率极其低下。为了解决这个问题,工厂引入了流水线作业。它将生产过程分解为三个连续的车间,每个车间只专注于一道工序,并且三个车间可以同时工作。当产品 1 进入第二道工序的车间时,产品 2 就可以进入第一道工序的车间开始加工。这样一来,虽然单个产品的完成时间并没有缩短,但在同一时间内,有三个产品分别在经历不同的阶段,整体的产出效率(即吞吐率)得到了成倍的提升。ARM 处理器的指令执行正是借鉴了这种流水线思想。它将一条指令的执行过程也分解为取指、译码、执行等多个阶段,让多条指令在时间上重叠处理,从而极大地提高了程序的执行效率。
由于 ARM 处理器采用的流水线结构,当程序读取 PC 的值时,得到的通常不是当前正在执行的地址,而是当前指令地址加上一定的偏移量。以三级流水线为例,即取指,译码,执行,PC 中存放的是取指的地址,而非执行的地址,因此 PC 中保存的通常是当前指令地址 +8 字节(ARM 状态下一条指令四个字节,Thumb 状态下一条指令 2 个字节,默认 ARM 状态)。这也就说明了上图中为什么
LR=PC-1。PC-1正是下一条要执行的指令。此外,PC 也是一个可读可写寄存器。通过向 PC 写入新的地址,可以实现程序跳转或函数返回。例如,执行
MOV PC, LR可以实现函数返回,而某些异常返回操作也会通过修改 PC 来恢复程序执行位置。因此,R15(PC)在 ARM 处理器中既承担指令地址指示的作用,又参与程序流程控制,是处理器运行过程中最关键的寄存器之一。 -
CPSR 当前程序状态寄存器
当前程序状态寄存器用于保存处理器当前的运行状态信息,是 CPU 中非常重要的一个控制寄存器。它记录了处理器的运算结果标志、当前工作模式、中断屏蔽状态以及指令集状态等信息。处理器在执行指令、发生异常或进行模式切换时,都会对 CPSR 的相关位进行更新或读取,从而控制系统运行行为。CPSR 是一个 32 位寄存器,其各个位域具有不同的功能,如下图所示,下面进行详细介绍。
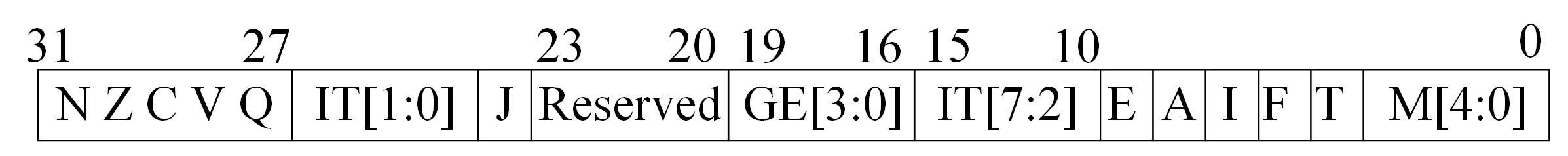
-
条件标志位
位 名称 含义 N Negative 结果为负数时置 1 Z Zero 运算结果为 0 时置 1 C Carry 加法产生进位或减法未借位时置 1 V Overflow 有符号运算产生溢出时置 1 -
中断标志位
位 名称 含义 I IRQ mask 为 1 时禁止普通中断 IRQ F FIQ mask 为 1 时禁止快速中断 FIQ A Abort mask 为 1 时禁止外部终止异常 -
指令状态位
位 名称 含义 T Thumb state 为 1 表示处于 Thumb 状态,为 0 表示 ARM 状态 ARM 处理器支持多种指令状态,不同状态下处理器执行的指令格式和长度不同。这些状态主要用于在性能、代码密度和兼容性之间进行平衡。下表是常见的指令状态对比表:
指令状态 指令长度 主要特点 应用场景 ARM 状态 32 位 指令长度固定,功能完整,大多数指令支持条件执行,执行效率高 高性能计算、操作系统内核 Thumb 状态 16 位 指令长度较短,代码密度高,占用存储空间小,但指令功能相对简化 存储资源受限的嵌入式系统 Thumb-2 状态 16/32 位混合 结合 ARM 与 Thumb 的优点,同时支持 16 位和 32 位指令,兼顾性能与代码密度 现代嵌入式系统和移动设备 Jazelle 状态 8 位字节码执行 用于直接执行 Java 字节码,由硬件加速 Java 虚拟机 早期 Java 嵌入式系统 ThumbEE 状态 16/32 位 为托管语言(如 Java)优化的执行环境,支持异常检测等特性 托管运行环境(现已较少使用) -
处理器模式位
M[4:0]模式值 模式名称 0x10 User 0x11 FIQ 0x12 IRQ 0x13 Supervisor 0x17 Abort 0x1B Undefined 0x1F System 通过修改这些位,处理器可以在不同运行模式之间进行切换。
-
大小端模式位
位 名称 主要功能 E Endian State 控制大小端模式 大小端表示在存储数据时不同的字节序规则,E = 0 表示处于小端模式(Little Endian),E = 1 表示处于大端模式(Big Endian)。在小端模式下,低地址存储低位字节;在大端模式下,低地址存储高位字节。大多数 ARM Linux 系统通常使用小端模式。
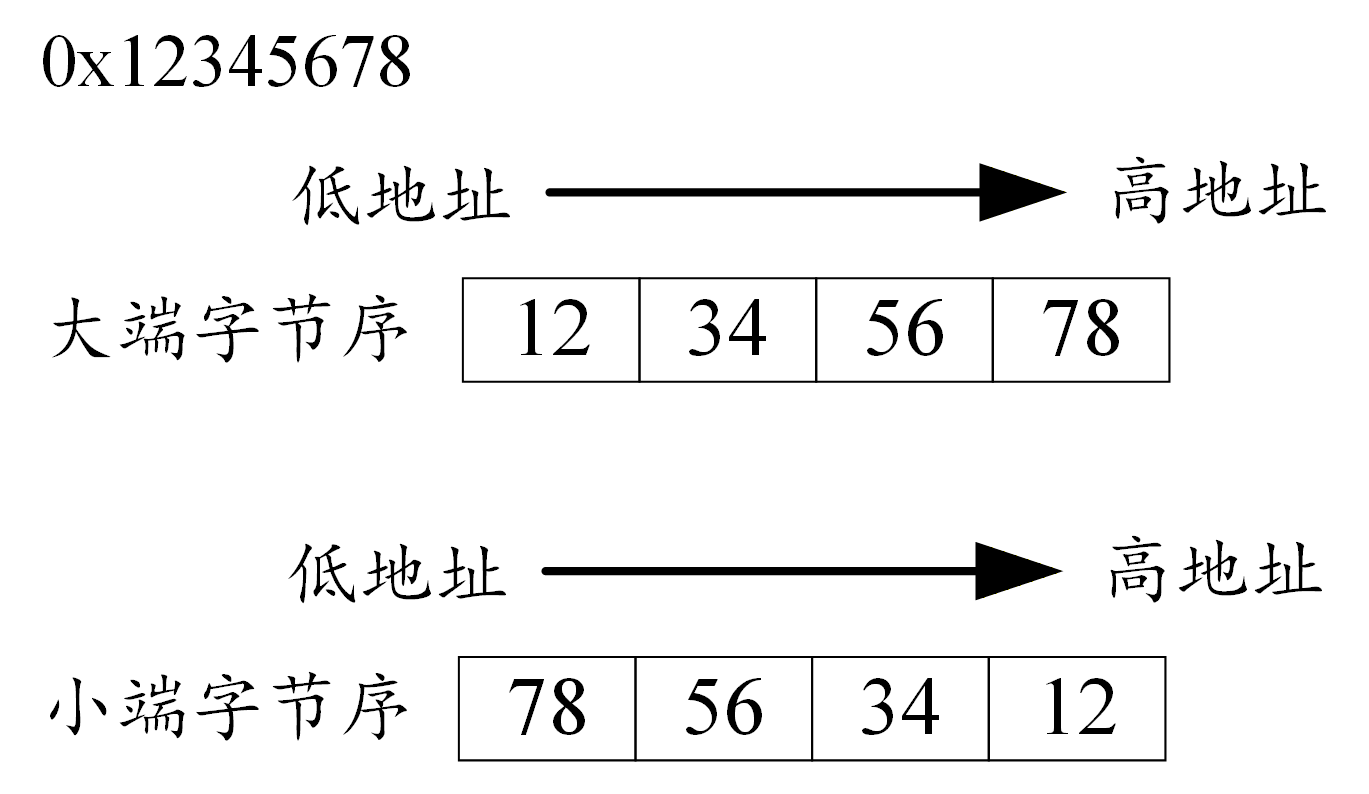
-
其余状态位——了解即可
位 名称 主要功能 Q Saturation Flag 饱和运算溢出标志 GE[3:0] SIMD Compare Flags 并行运算比较结果 IT[7:0] If-Then State Thumb 条件执行控制 J Jazelle State Java 字节码执行状态 Q 位用于表示饱和运算溢出标志。在 ARM 的 DSP 指令或饱和算术运算(Saturation Arithmetic)中,如果运算结果超过了数据表示范围,处理器不会产生普通溢出,而是将结果限制在最大或最小范围,这种运算称为饱和运算。当发生饱和时Q 位会被置 1,并且该位具有 “粘性”特性(sticky),即一旦被置位不会自动清零,需要软件显式清除。这种机制常用于数字信号处理,音频处理和图像处理算法。
GE[3:0] 是 SIMD/DSP 指令使用的比较标志位。它主要用于 ARM 的 并行加减运算指令(如
UADD8、USUB8等),这些指令可以同时对多个字节或半字进行运算。GE 位的含义:每一位对应一个并行运算单元,表示该运算单元的结果是否满足大于等于 0 或未产生借位。GE[i] 表示第i个字节运算结果。这些标志位常用于并行比较或数据选择操作。IT 位用于支持 Thumb 指令集中的条件执行机制。在 ARM 状态下,大部分指令都可以带条件码执行,而在 Thumb 指令集中,为了保持代码密度,引入了 IT(If-Then)指令。IT 指令会指定接下来几条指令的执行条件,相关状态信息会存储在 CPSR 的 IT[7:0] 位中。
J 位用于表示处理器是否处于 Jazelle 执行状态。Jazelle 是 ARM 提供的一种硬件加速技术,用于直接执行 Java 字节码(Java Bytecode)。J = 1 表示处理器进入 Jazelle 状态;J = 0 表示正常 ARM 或 Thumb 状态。不过在现代 ARM 处理器中,Jazelle 已经逐渐被 Thumb-2 和软件虚拟机取代,因此该位在实际系统中很少使用。
-
-
SPSR 保存程序状态寄存器
在 ARM 处理器中,SPSR(Saved Program Status Register,保存程序状态寄存器)用于在异常或中断发生时保存原来程序的处理器状态。当处理器从当前运行模式进入某个异常模式时,当前的 CPSR(Current Program Status Register) 会自动复制到该异常模式对应的 SPSR 中,以便在异常处理结束后能够恢复原来的运行状态,从而保证程序能够正确继续执行。从结构上看,SPSR 与 CPSR 具有完全相同的位结构,同样是一个 32 位寄存器,其中包括条件标志位(N、Z、C、V)、中断屏蔽位(I、F、A)、指令状态位(T、J)、执行控制位以及处理器模式位等信息。因此,当异常发生时,处理器通过将 CPSR 的内容保存到 SPSR 中,可以完整记录异常发生时的处理器状态,例如当前工作模式、条件标志以及中断状态等。
需要注意的是,SPSR 只存在于异常模式中,用户模式(USR)和系统模式(SYS)并没有 SPSR。每一种异常模式都有自己独立的 SPSR,例如:SPSR_irq、SPSR_fiq、SPSR_svc、SPSR_abt、SPSR_und、SPSR_mon 和 SPSR_hyp。当处理器进入对应异常模式时,会自动使用该模式的 SPSR 保存状态信息。
在异常处理结束后,系统通常需要恢复异常发生前的运行环境。这时可以通过特定指令(如异常返回指令)将 SPSR 中保存的值重新加载到 CPSR 中,从而恢复处理器原来的工作模式、条件标志和中断状态,并继续执行被中断的程序。因此,SPSR 在 ARM 异常处理机制中起到了保存和恢复处理器运行状态的重要作用,是保证系统正确处理中断和异常的重要寄存器。
2.2 ARM 内核存储系统 & MMU
2.2.1 存储系统
ARM 处理器通常采用分层的存储结构。在了解一件新事物的时候,我们要意识到它的存在一定是解决某个问题,所以带着问题去理解知识往往会达到事半功倍的效果。我们知道处理器的主频是非常高的,能够达到几个 GHz,相比之下,内存的速度就显的很低,比如常见的 DDR5/4800MHz,速度差了好几倍,CPU 使用内存存取数据的时候,在等待过程中如果 CPU 一直等待,那 CPU 的这么高的性能频率就没有意义了,分层的存储结构就是为了解决这个问题。处理器的存储系统从快到慢通常由寄存器,Cache,内存(RAM),Flash 等组成。
寄存器是集成在 ARM 内核中的存储单元,距离执行单元最近,采用全定制电路设计并由高速触发器构成,因此它是整个存储体系中速度最快的一级存储介质,用于暂存指令执行过程中的数据、地址或状态信息。尽管寄存器速度极快,但其数量通常十分有限,这主要是由几个物理和架构层面的因素决定的。首先,处理器内核的芯片面积非常宝贵,而寄存器的晶体管结构较为复杂,占用面积较大,过多的寄存器会挤占运算单元和控制逻辑的空间。其次,指令集架构在设计时会将寄存器编号编码在固定长度的指令字段中,也就是说对寄存器读写不需要寻址,直接使用寄存器名即可,如果寄存器数量过多,指令编码长度就需要扩展,这会大幅增加指令的复杂度和硬件开销。此外,寄存器组的读写操作非常频繁,如果数量过多,会显著增加内核的动态功耗和发热量,影响处理器的稳定性和能效比。相比于 Cache,寄存器的速度优势不仅在于其物理位置更靠近核心,还在于它无需经过 MMU 进行地址转换和查表操作,可以实现数据的直接访问,从而消除了地址转换带来的延迟开销。
Cache 高速缓存是由高速静态随机存储器(SRAM)构成的缓冲阵列,Cache 设计的目的就是为了弥补 CPU 核心与外部主存(板卡级)之间的巨大速度差距。它通过局部性原理来运作。局部性原理就是指程序在执行过程中,对于地址空间内的访问往往会呈现出相对集中的现象,Cache 中就保存着这些极大概率被执行的指令和被访问的数据。局部性原理分为时间局部性和空间局部性。时间局部性是指如果某个数据或指令被访问过,那么在不久的将来它很可能会被再次访问,这源于程序中的循环结构和频繁调用的函数。空间局部性则是指如果某个存储单元被访问,那么它附近的存储单元也很有可能在不久的将来被访问,这源于指令的顺序执行以及数组或数据结构等连续存储的访问模式。Cache 通过将最近访问过的数据以及与之相邻的数据提前从相对较慢的主存中加载到高速缓存中,从而在CPU再次需要这些数据时能够以极快的速度直接提供给CPU,避免了每次都去访问速度较慢的主存,进而显著提升了系统的整体性能。
寄存器 和 Cache 都是集成在 SoC 内部,而内存一般是焊接在板卡上。主存(内存)通常采用动态随机存取存储器(DRAM),其主要作用是临时存放当前正在执行的程序指令以及这些程序运行时所需的数据。当用户启动一个程序时,操作系统会将该程序从速度较慢的硬盘或固态硬盘中加载到主存中,以便CPU能够以较快的速度进行读取和执行。在存储体系中,主存起到了缓冲和桥梁的作用。CPU内部的寄存器速度极快但容量极小,而外部的硬盘速度很慢。主存的读写速度虽然远不及寄存器,但比硬盘快好几个数量级。它作为 CPU 和 I/O 设备之间数据交换的周转区域,确保了数据能够相对顺畅地在高速部件和低速部件之间流动。相比于寄存器(仅几十字节)和 Cache,主存提供了更大的存储空间(通常为几 GB 到几百 GB),能够容纳现代操作系统、大型应用程序以及多任务环境下并行运行的各种进程。主存属于随机访问存储器,这意味着CPU可以通过地址直接访问主存中的任何一个存储单元,访问所需的时间与存储单元的位置无关,且访问速度基本恒定。这种特性支持了程序的非连续执行和数据的高效读取。在现代计算机系统中,主存与硬盘配合实现了虚拟内存机制。当主存容量不足以容纳当前运行的所有程序时,操作系统会将暂时不用的数据从主存交换到硬盘上,需要时再换回主存,这使得计算机可以运行比主存实际容量大得多的程序,下面介绍 MMU 时会对该机制进行详细解释。
Flash(硬盘)的核心作用是数据的持久化存储,属于非易失性存储器,哪怕设备断电,硬盘上的数据也不会丢失。操作系统、应用软件、个人文档、照片、视频等需要长期保存的数据,都是存放在硬盘中的。CPU无法直接执行存储在硬盘上的程序或直接处理硬盘上的数据。当要运行一个程序时,操作系统会先将该程序从硬盘加载到主存中,然后CPU才能从主存中读取指令并执行。硬盘就像是存储仓库,而主存则是工作台。相比于上层存储介质,硬盘提供了最大的存储空间。这种大容量特性使得计算机能够安装庞大的操作系统、复杂的应用程序以及海量的用户数据。在现代操作系统的虚拟内存机制中,硬盘充当了内存的“后备仓库”。当物理内存(主存)容量不足时,操作系统会将暂时不用的内存数据页面转移到硬盘上专门划分的区域,等到需要时再重新调入内存。这使得计算机能够运行超过其物理内存限制的大型程序或多任务环境。
2.2.2 内存管理单元 MMU
概述
MMU 用于虚拟地址和物理地址之间的相互转换,那么直接使用物理地址不行吗,为什么要引入虚拟地址呢。直接使用物理地址寻址虽然既直观又简单,但如果运行操作系统进行多任务处理的时候会遇到很多问题。首先就是无法运行多个程序,如果要同时运行两个程序,就必须事先约定好各自使用哪段物理内存,否则很有可能出现数据相互覆盖的情况导致程序崩溃。其次,如果一个程序运行出现问题比如内存越界访问等,极有可能会破换其他进程的数据导致整个系统的崩溃。此外,如果只使用物理内存,那么程序必须要全部加载到内存中才能运行,要知道我们平时运行的任务占用的内存量很有可能超过我们的内存实际大小。总之,只使用物理内存会给多任务执行造成很大的制约,系统运行不稳定并且多任务之间的隔离性非常差。虚拟内存的引入就是为了解决这些问题。MMU 作为介于 CPU 核心和内存之间的关键模块,负责虚拟地址到物理地址的转换。当操作系统启用 MMU 后,程序不再直接看到真实的物理内存,而是面对一个独立的、连续的、私有的虚拟地址空间。程序发出的所有地址都是虚拟地址,这些地址在被送到内存之前,必须先经过 MMU 的转换。在讲解转换方式之前,先对一些关键概念进行详细说明。
-
页(Page)
页是指操作系统和 MMU 将虚拟地址划分成的固定大小的连续块(常见大小为 4KB),它是分页式内存管理的基本单位。通过将虚拟地址空间分割为若干页,并将物理内存划分为同样大小的页框,操作系统可以利用页表建立虚拟页到物理页框的映射,从而在进程间实现内存隔离与保护,并支持虚拟内存机制——当物理内存不足时,暂时不用的页可以被换出到磁盘,需要时再重新载入,使得每个进程都能拥有独立的、连续的、且可能大于实际物理内存的地址空间。
-
页帧
页帧,又称物理页或页框,是指将物理内存按照固定大小划分而成的连续区域,其大小通常与虚拟地址空间中的页完全相同。作为内存管理的最小物理单位,页帧是操作系统和 MMU 进行内存分配的真正实体,当进程需要加载数据时,系统会从空闲的页帧池中分配一个或多个页帧,并通过页表建立起虚拟页与物理页帧之间的映射关系,使得不同进程可以通过各自的页表映射到不同的页帧上,从而实现内存隔离与共享,同时也为虚拟内存的换入换出提供了物理基础。
-
页表
页表是操作系统为每个进程维护的一种核心数据结构,通常存储在物理内存中,用于记录虚拟地址空间中各页与物理内存中页帧之间的映射关系。页表中的每一个条目称为页表项(PTE),其中不仅包含对应的物理页帧号,还存储了该页的访问权限、存在位、脏位等控制信息。当 CPU 启用 MMU 后,每次内存访问都会由 MMU 根据当前进程的页表将虚拟地址转换为物理地址;若页表项指示目标页不在内存中,则会触发缺页异常,由操作系统负责将数据从磁盘载入内存并更新页表。
-
TLB
TLB(Translation Lookaside Buffer,转译后备缓冲器)是 CPU 内部 MMU 中的一个硬件缓存单元,专门用于存储最近使用过的虚拟地址到物理地址的映射关系。由于页表通常存放在速度较慢的物理内存中,若每次地址转换都去内存查询页表,会大幅降低系统性能;TLB通过以极快的速度提供缓存后的映射条目,使得绝大多数地址转换可以在一个时钟周期内完成,无需访问内存中的页表,从而极大地加速了虚拟地址到物理地址的转换过程,是缓解CPU与内存速度差异、保证系统高效运行的关键硬件组件。
MMU 工作流程
当程序执行一条访存指令(如加载或存储)时,CPU 将指令中指定的虚拟地址发送给内存管理单元(MMU)。该虚拟地址通常由两部分组成:高位部分的虚拟页号(VPN)和低位部分的页内偏移(offset)。MMU 首先从虚拟地址中提取出 VPN 和 offset。VPN 用于查找对应的物理页框,offset 则直接作为物理地址内的偏移量。MMU 首先在内部的 TLB 中查找是否存在与当前 VPN 匹配的映射条目。如果 TLB 命中,则直接获得对应的物理页框号(PFN)。MMU 将 PFN 与 offset 拼接成完整的物理地址,随后将该物理地址发送到内存总线以访问物理内存。整个过程在几个时钟周期内完成,速度极快。如果 TLB 未命中,则MMU需要执行较慢的页表遍历。
页表遍历:MMU 根据当前进程的页表基址找到页表在物理内存中的位置。页表可能采用多级页表,以减少内存占用。MMU逐级索引:将 VPN 分割成多个部分,每一部分作为对应级页表的索引。每一级页表项指向下一级页表的物理地址,直到最后一级页表项包含最终物理页框号及权限标志。在遍历过程中,MMU 会检查每一级页表项的有效位、读/写/执行权限等。如果任何一级的页表项无效,或者权限不符,则触发异常(如缺页异常或保护错误)。如果最后一级页表项有效且权限允许,则从中提取物理页框号(PFN)。MMU 会将这个映射关系(VPN→PFN及权限)填充到 TLB 中,以备后续快速访问。如果该页表项标识页面不在物理内存中(存在位为0),则MMU无法继续,转而触发缺页异常,交给操作系统处理。
缺页异常处理:操作系统根据异常原因(如页面被换出到磁盘),在磁盘上找到所需页面的内容。然后选择一个空闲的物理页框,将数据从磁盘读入该页框(可能涉及I/O操作)。随后更新进程的页表,填入新的物理页框号并设置有效位,同时清空相关 TLB 条目(或等待下次访问重新填充)。最后异常返回,重新执行触发异常的指令,此时再次进行地址转换,TLB中将命中新加载的映射。
一旦 MMU 获得了物理页框号,就将其与页内偏移组合,形成完整的物理地址,并通过内存控制器发送到物理内存。最终,内存返回数据给 CPU,完成一次访存操作。
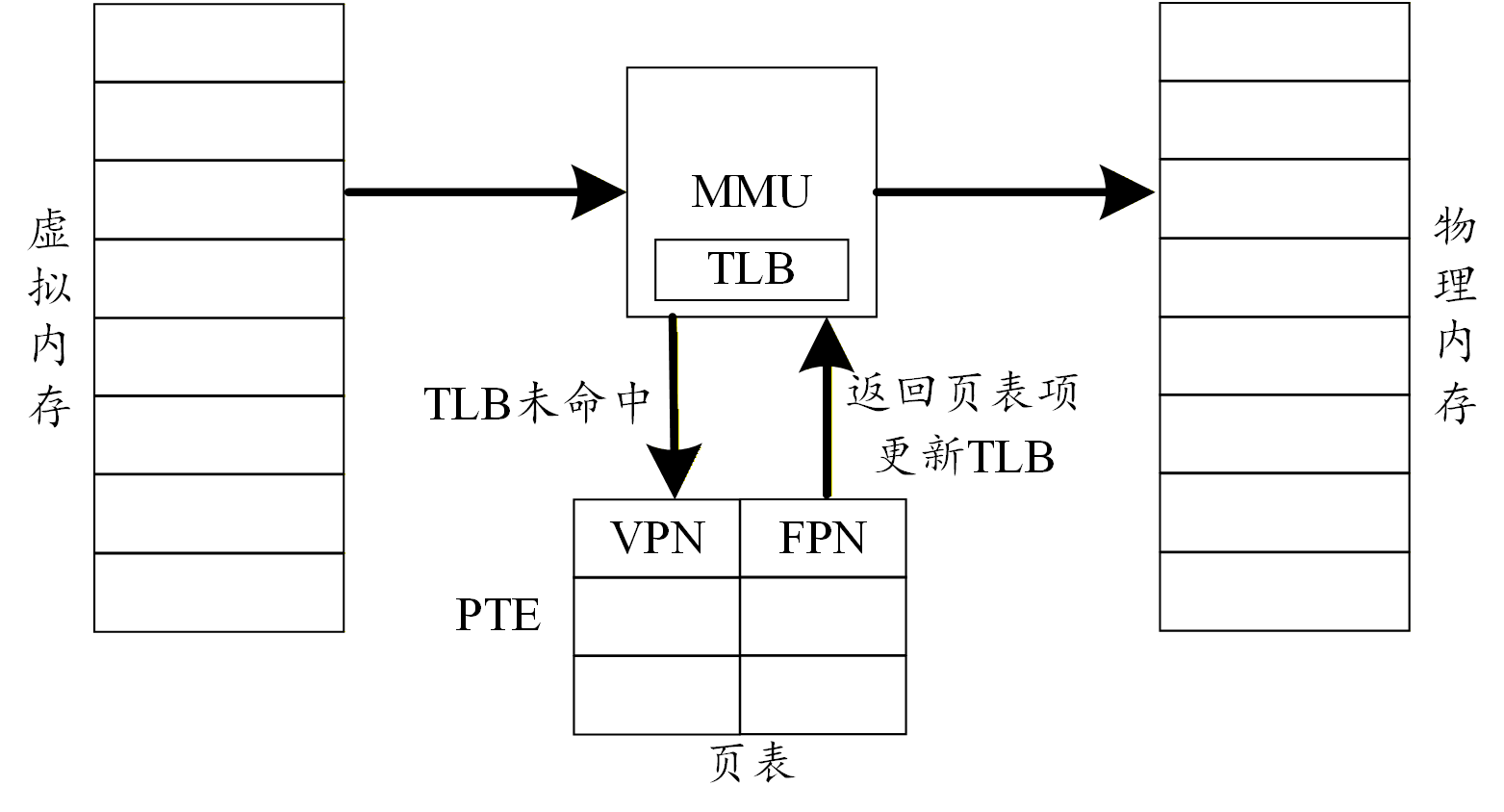
为什么虚拟地址机制能够使得操作系统能够执行超过实际物理内存大小的任务?
虚拟内存之所以能够让系统运行超过实际物理内存大小的进程,核心在于它将进程运行时所需的地址空间与实际的物理内存进行解耦,并利用了“按需加载”和“页面置换”两种机制。
首先,虚拟内存为每个进程提供了一个独立的、连续的虚拟地址空间,这个空间的大小受限于处理器的位数(如 32 位为 4GB,64 位则更大),远大于物理内存的容量。当程序运行时,操作系统并不会将整个进程的全部代码和数据一次性加载到物理内存中,而是采用按需加载的原则:只将当前正在执行的部分(如代码段、当前使用的数据页)加载到物理内存中,而其余暂时不用的部分则仍然保留在磁盘(如交换分区或页面文件)上。这意味着一个 16GB 的大程序在只有 4GB 物理内存的系统上也能启动,因为操作系统最初可能只加载了它的几 MB 启动代码。
其次,当进程运行过程中需要访问尚未加载到内存的页面时,MMU 会触发缺页异常,操作系统随即介入,将该页面从磁盘载入内存。如果此时物理内存已经占满,操作系统便会启动页面置换算法,将某些暂时用不上的页面“换出”到磁盘中,腾出空间给当前需要的页面。这种动态换入换出的过程,使得有限的物理内存得以复用,从而支撑起比自身大得多的虚拟地址空间。
举个例子,假设一台计算机只有 4GB 物理内存,但用户运行了一个需要 6GB 内存的数据库程序。虚拟内存机制让程序认为自己拥有连续的地址空间,操作系统只将程序当前正在使用的热点数据留在 4GB 内存中,而将暂时不访问的数据自动放到硬盘的交换文件中。当程序需要访问之前换出的数据时,操作系统再将其调入内存,并将其他暂时不用的数据换出。整个过程对程序完全透明,仿佛它真的拥有 6GB 内存一样。
2.3 ARM 指令执行流水线
2.1.2 节中讲解程序计数器时对流水线的基本设计思想做了大概的描述。
CPU 流水线是一种硬件实现技术,它允许 CPU 在同一个时钟周期内同时处理多条指令的不同阶段。其核心思想是将一条指令的执行过程分解成若干个独立的、由专门硬件电路完成的子步骤,然后让这些硬件单元像工厂的生产线一样并行工作。
Cortex-A7 采用 8 级流水线,较为复杂。我们以典型的 5 级流水线进行讲解,主要是理解流水线的设计思想即可。
对于 5 级流水线,一条指令从开始到结束会经历以下阶段:
- IF(取指):取指令。CPU根据程序计数器(PC)中的地址,从指令缓存(L1 Cache)中取出将要执行的指令。
- ID(译码):指令译码与读取寄存器。分析指令的类型和操作,确定需要哪些数据,并从寄存器堆中读取这些数据。
- EX(执行):执行。算术逻辑单元(ALU)开始干活,执行指令要求的操作,比如加法、减法、逻辑运算,或者计算内存访问的地址。
- MEM(访存):内存访问。如果指令需要读写数据内存(如加载或存储),这个阶段就会对数据缓存(L1 Cache)进行访问。
- WB(写回):写回。将指令的执行结果(从ALU或内存中读取的数据)写回到寄存器堆中。
我们来看一个简单的指令序列,看看它们在五级流水线中是如何重叠执行的:
ADD R1, R2, R3 ; 指令1:将R2和R3相加,结果存入R1
SUB R4, R1, R5 ; 指令2:从R1减去R5,结果存入R4
LOAD R6, [R1] ; 指令3:从R1指向的内存地址加载数据到R6
OR R7, R8, R9 ; 指令4:R8和R8进行或运算,结果存入R7
以上指令的 5 级流水线执行状态如下(这里只考虑理想情况,不考虑阻塞等等待情况):
| 时钟周期 | 取指 (IF) | 译码 (ID) | 执行 (EX) | 访存 (MEM) | 写回 (WB) |
|---|---|---|---|---|---|
| 周期1 | 指令1 | ||||
| 周期2 | 指令2 | 指令1 | |||
| 周期3 | 指令3 | 指令2 | 指令1 | ||
| 周期4 | 指令4 | 指令3 | 指令2 | 指令1 | |
| 周期5 | (下一条) | 指令4 | 指令3 | 指令2 | 指令1 |
| 周期6 | ... | ... | 指令4 | 指令3 | 指令2 |
在周期3,当指令1在执行(EX)阶段时,指令2正在译码(ID),而指令3正在取指(IF)。这意味着在同一个时钟周期内,有3条不同的指令被CPU的不同部分同时处理着。虽然单条指令的执行时间(从开始到结束的延迟)没有显著缩短,但 CPU 完成指令的整体速度(吞吐量)得到了极大提升。在上述例子中,理想情况下每个时钟周期都能完成一条指令。流水线状态下 CPU 内的各个功能单元(取指单元、译码器、ALU、内存单元、写回单元)在大部分时间里都处于忙碌状态,而不是闲置等待。
本文只对流水线概念进行了简单介绍,适用于对其进行简单理解,实际流水线执行并非如此顺畅,要面对各种“冒险”问题,并且有多种解决办法。读者感兴趣可自行深入研究。
三、总结
本文对 ARM 架构的组成和关键模块进行了简要介绍,希望对读者有所帮助。笔者水平有限,可能有诸多不严谨的地方,读者最好带着怀疑和探索的态度阅读本文。
Steady progress!
原文地址: https://www.cveoy.top/t/topic/qGbf 著作权归作者所有。请勿转载和采集!