《Dream to Control: Learning Behaviors by Latent Imagination》随记
阶段一:学习世界模型(Dynamics Learning)
具体可以参考链接:《Learning Latent Dynamics for Planning from Pixels》随记
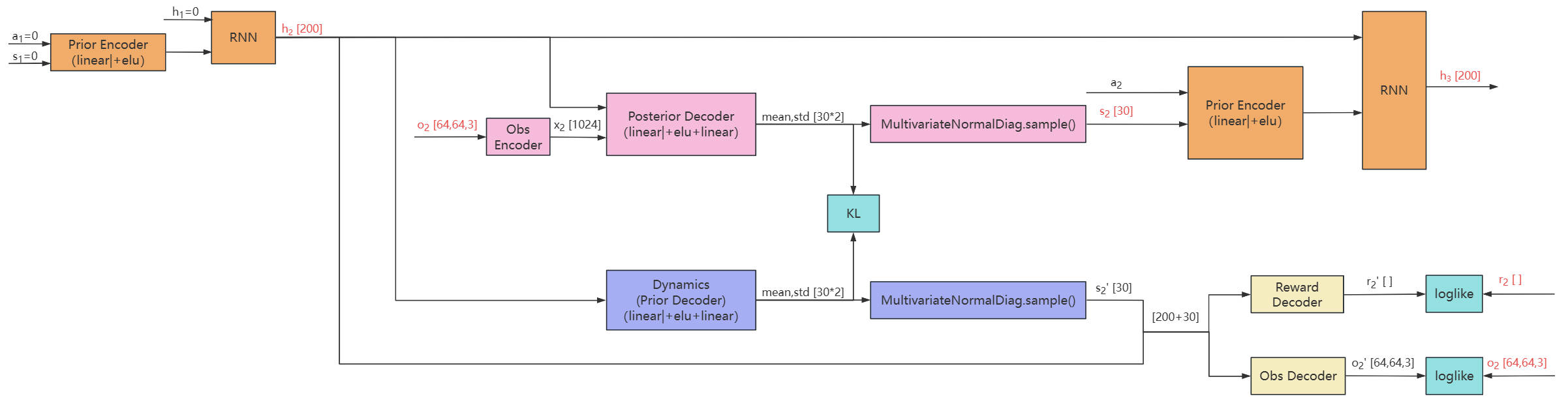

阶段二:在潜空间中想象(Behavior Learning)
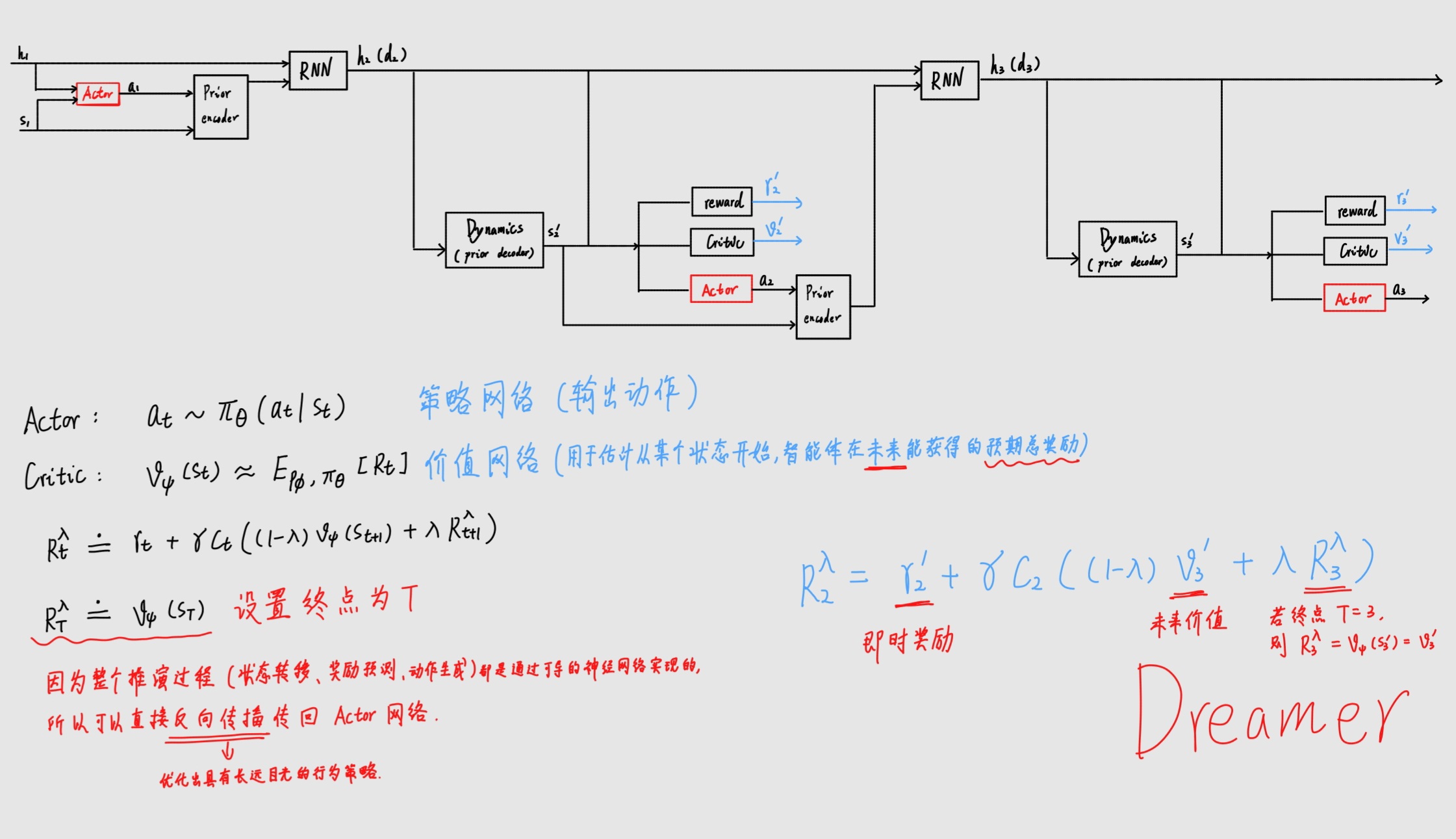

阶段三:与环境交互(Environment Interaction)

PlaNet 和 Dreamer 的异同
PlaNet = 世界模型(RSSM) + 在线实时推演找最优解 。
Dreamer = 世界模型(RSSM) + 离线在梦境中训练 Actor/Critic + 依靠 Actor 实时反应 。
PlaNet 不是 Dreamer 的前奏,而是它的“前身”。Dreamer 是站在 PlaNet 的肩膀上,把耗时的“在线规划”替换成了更优雅、更具长远目光的“梦境 Actor-Critic 训练” 。
相同点
不管是 PlaNet 还是 Dreamer,它们认识世界的方式是一模一样的 。它们都会收集过去的经验,然后训练 RSSM(循环状态空间模型)。

不同点
有了“预测未来”的能力后,它们采取了不同的战术

原文地址: https://www.cveoy.top/t/topic/qGah 著作权归作者所有。请勿转载和采集!