《Mastering Diverse Domains through World Models》随记
DreamerV3 的主要贡献

但是其实需要摄像头一直朝向前方,如果摄像头有发生左转或者右转,出现跳变的话,会比较难预测。
DreamerV3 在 DreamerV2 上的改动
在 encoder 和 decoder 上有非常多的种类
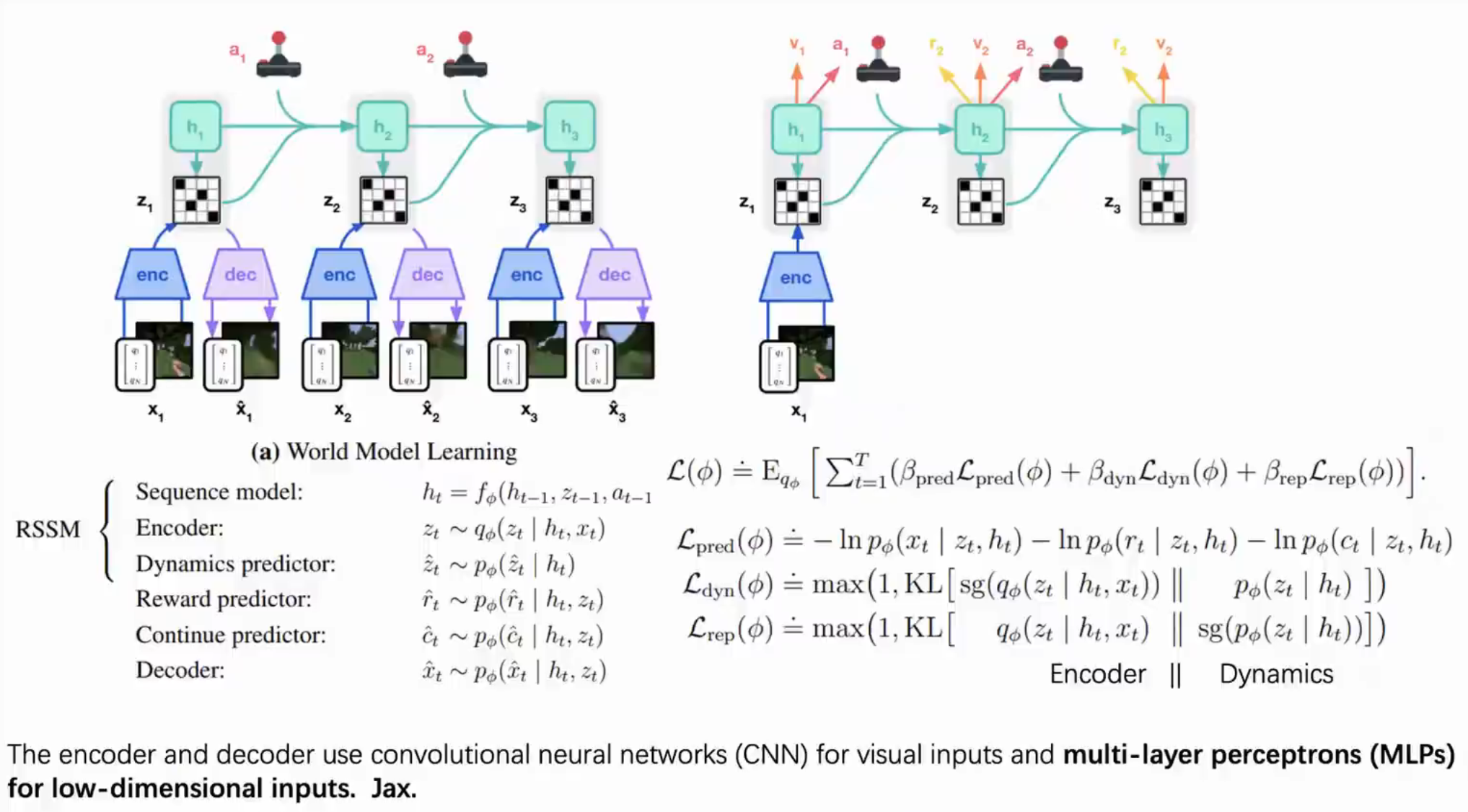
DreamerV3 的架构和 DreamerV2 是差不多的
实现跨不同领域【主要的三个 trick】
通过这主要的三个 trick,能够让在不同的环境下尺度不一样的 reward 和 observation 的尺度统一在一个空间下。
让它的 World Model、Critic、Actor 的输入和输出在不同的环境下都统一,从而在不同的环境下达到很好的效果。
Symlog and Symexp

把不同目标(不同量纲)都映射到同一个平滑的区域,让不同量纲的 loss 的 scale 到同一个空间里面。
Twohot Encodeing

onehot 是把一个单词映射成一个向量
twohot 是把一个连续值映射成两个离散值
那网络就变成只要预测离散的值就可以了,将回归任务变成一个分类任务
Returns Normalization
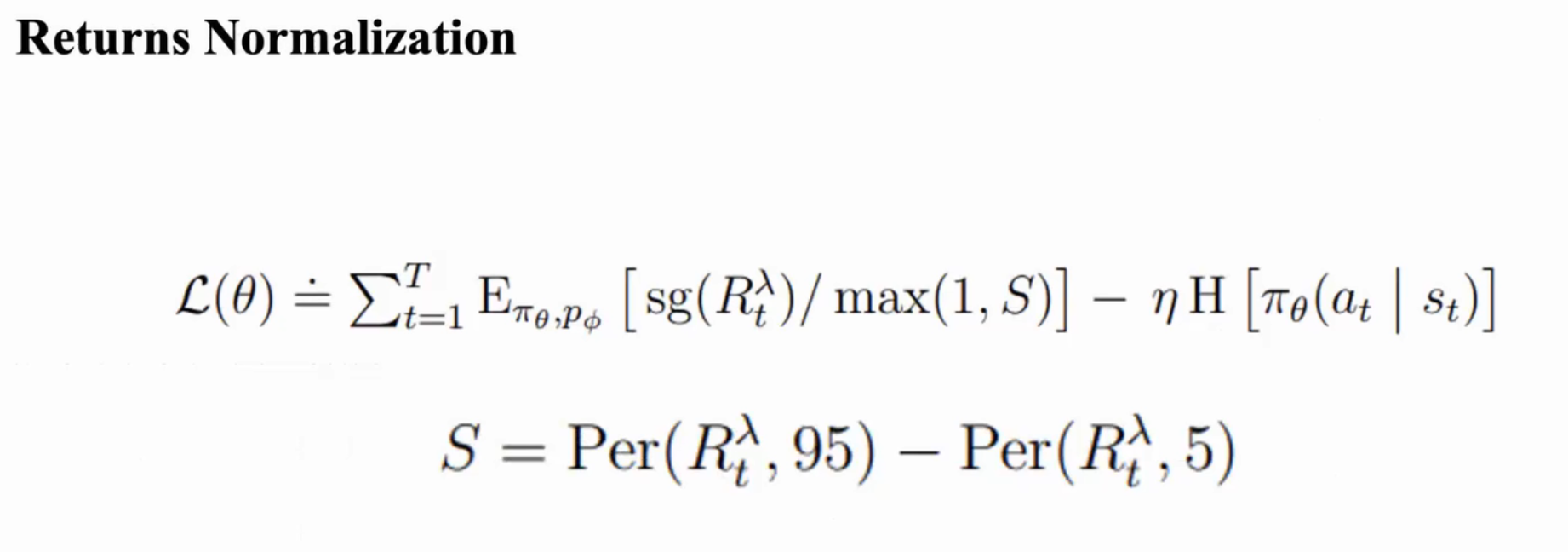
用在 Actor 的更新上
能让稀疏情况下的 reward 能够更好的进行归一化,能够在奖励稀疏的情况下更好地训练 Actor
原文地址: https://www.cveoy.top/t/topic/qGaD 著作权归作者所有。请勿转载和采集!