为什么买了 SCA 工具,开源依赖还是管不住?
开源治理不是买工具,是建流程——全生命周期设计方案
上一篇结尾留了一个问题:当开发引入一个高风险组件时,企业有没有能力阻止它进入生产环境?
答案是:大多数企业没有。
不只是没有能力,甚至根本没人知道"该由谁来决定"。
我见过的一个真实场景
有个银行客户,在 Log4j 事件之后痛下决心,采购了当时市面上主流的 SCA 工具,接入了 CI/CD 流水线,花了好几个月把所有项目的 SBOM 都跑了出来。
合规审计的时候拿出来,规格标准、字段齐全。领导看了很满意:我们的开源治理做到位了。
但实际情况呢?
半年后换了一任安全负责人。新来的问:"我们现在开源组件有多少?漏洞处理率是多少?"
团队翻了一周,翻了三千多条漏洞记录,已处理的不到两百条。
开发说没时间修——漏洞太多,没人告诉他们先修哪个。
安全说推不动——没有流程告诉开发,什么级别的漏洞什么时候必须修完。
SBOM 目录库倒是全的,但没有人维护。三个月前的数据和现在的代码已经对不上了。
工具到位了,SBOM 生成了,但治理还是没做起来。
问题出在哪里?不是工具不够好,是缺了三个东西:明确的组织、可执行的流程、闭环的机制。
这个判断在强监管行业已经有了明确要求。2021 年,中国人民银行等五部门联合发布了《关于规范金融业开源技术应用与发展的意见》¹,明确要求金融机构建立覆盖引入审批、技术评估、合规使用、漏洞检测、更新维护、应急处置、停用退出的全链条管理制度。
金融行业因为监管要求和安全压力,是国内最早把开源治理做成体系的领域。但这不代表这套方法论只适用于金融业——只要企业的软件交付依赖大量第三方组件,不管是互联网、制造、能源还是政企,迟早都要回答同样的问题:组件怎么引入、使用中怎么监控、出问题后怎么退出。
这几年,金融行业的一些先行企业已经把流程跑出了形。做得好的和做不好的差别在哪?
不在工具,在流程。
开源治理本质上就三件事
不管你用多贵的 SCA 工具,开源治理可以拆成三个问题:
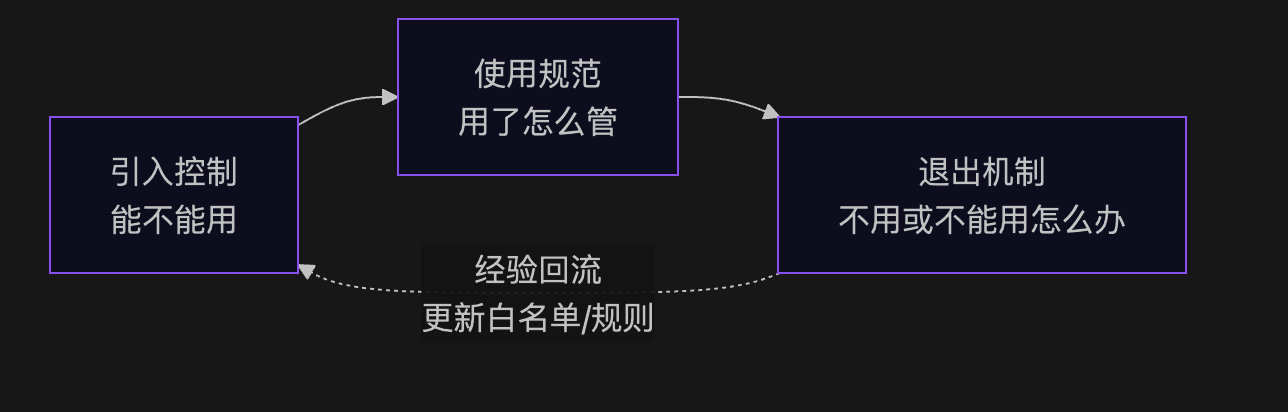
| 阶段 | 核心问题 | 关键动作 |
|---|---|---|
| 引入控制 | 这个组件能不能用? | 评估、审批、白名单 |
| 使用规范 | 用了之后怎么管? | 监控、更新、漏洞响应 |
| 退出机制 | 不用了或不能用了怎么办? | 替换、升级、下线 |
听起来简单。但把这三件事落到实处,需要回答很多具体的问题。
下面这套方法,不是照搬某一家企业的做法,而是把共性问题抽出来,形成一套可以按团队规模裁剪的流程设计。
全生命周期设计方案
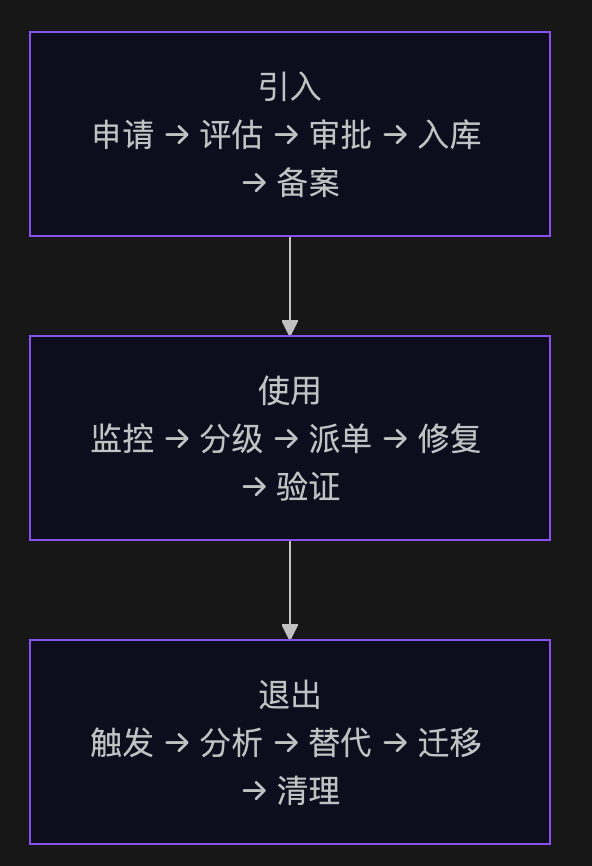
阶段一:引入——在组件进入系统之前拦住风险
引入阶段是所有治理的起点。如果入口没管住,后面再怎么监控都是亡羊补牢。
关键要解决三个问题:能不能用、谁说了算、走什么流程。
1. 白名单分流机制
不是什么组件都需要审批的。SLF4J、Spring Boot、Jackson、Guava 这类广泛使用的成熟组件,每引入一次批一次,开发会疯掉。
合理的做法是分层:
| 类别 | 处理方式 | 举例 |
|---|---|---|
| 白名单组件 | 自动通过+登记备案 | Apache Commons、Spring Boot 稳定版、SLF4J |
| 灰名单组件 | 自动评估+简易审批 | 新版、次稳定版、使用范围受限的组件 |
| 新组件 | 自动评估+人工审批+入库 | 从未引入过的第三方组件、高风险领域的组件 |
这套分层的核心逻辑是:管住少数不确定的,放开大多数已验证的。 在一些企业的实践中,分层后审批量可以显著下降——既保持了控制力,又不拖慢开发节奏。
类似思路在不少先行企业中已经出现。以农业银行²为例,他们建立了一套 12 维度的评估模型来做白名单打分,非白名单走人工审批。更进一步的企业会在设计阶段就强制使用管控基线内的组件,从源头减少下游的组件种类。
2. 统一制品库
这是另一个容易被忽略但极其关键的工程细节。
很多企业的开发者在 pom.xml 里直接引用 Maven Central、npm Registry 上的包,没有任何管控。这意味着你连"开发到底引入了什么"都控制不了。
正确的做法是搭建一个企业内部私有仓库(比如 Nexus、Artifactory)。
所有外部组件必须先经过前置库的临时区,自动完成安全扫描、许可证检查、质量检测,评估通过后才能进入正式库。开发环境的依赖管理工具强制指向这个正式库,而不是外部源。
这样做的价值:保证所有进入企业的组件都是经过审核的,来源唯一、版本可控。
3. 引入审批流程
一个组件的引入,我建议标准化为一条流程:
提交申请单 → 合规评估(许可证/License)→ 安全评估(已知漏洞)→ 技术评估(社区活力、版本稳定度)→ 登记台账 → 软件入库
这六个环节的严格程度可以根据企业规模调整。一些先行企业的实践分了八大流程,安全评估和合规评估做了更细的角色拆分。对安全等级要求最高的场景,还可以增加法务、安全、架构等多角色复核。
大多数企业不需要一开始就上这么重的流程。但至少应该明确两个角色:
- 谁审批——技术委员会或安全架构师
- 什么情况下要审批——非白名单组件必须审,白名单组件走备案
阶段二:使用——持续跟踪,分级响应
组件引入了,不等于结束。它可能随时出现新漏洞,你需要知道、需要响应。
使用阶段的关键:监控是自动的,但响应要有流程。
1. 自动检测体系
每次构建时自动更新 SBOM,自动对接 NVD、CNVD 等漏洞情报源,匹配当前所有在用的组件。这些工作工具都能做,不需要人参与。关键是把这些检测点嵌入到 CI/CD 流水线的固定位置——开发阶段自动从可信渠道下载,测试准入自动识别新组件并推送测评,投产构建自动校验完整性——整个流程不需要人手动触发。
农业银行的 TOSIM 体系³就是按这个思路建的:他们把治理嵌入 DevOps,质量门禁能根据测评结果自动决定制品能否晋级。这也是这套方法论实践得最彻底的企业之一。
2. 漏洞分级与 SLA
这是很多企业做得最差的一环。工具扫出一堆漏洞,全堆在那,没人处理。
问题不是漏洞太多,是没有分级,没有 SLA。
我见过的合理的分级方式是:
| 漏洞等级 | 响应时间 | 修复时间 | 责任人 |
|---|---|---|---|
| 严重 | 4 小时内确认 | 48 小时内修复 | 业务线技术负责人 |
| 高危 | 24 小时内确认 | 7 天内修复 | 服务 owner |
| 中危 | 纳入迭代排期 | 下一版本修复 | 开发团队 |
| 低危 | 登记备案 | 定期评估 | 开发团队 |
这里有一个很重要的现实判断:漏洞未必是风险。 一个高危漏洞如果只在内部管理后台、不暴露在公网、没有公开的利用代码,修复优先级完全没必要和面向客户的零日漏洞一样。
真正要做的是综合判断:是否可达、是否暴露、是否有补丁、是否存在公开利用代码、是否承载核心业务——而不是只看 CVSS 分数。尤其是存量系统,扫出几万个漏洞的时候,全部修复不现实也不必要。所以分级机制的关键不只是分等级,更是分优先级——渠道系统和对外暴露系统的高危漏洞先修,内部工具的中低危漏洞可以纳入迭代排期。不少企业用的就是这个思路,把分级和业务场景绑定,不是一刀切。
3. 报告给对的人看
监控数据不能转化为行动,就等于没有。而行动的前提是信息精准触达:
- 给开发看的报告:聚焦"你负责的服务有哪些需要修的漏洞"
- 给领导看的报告:聚焦"整体风险趋势、合规达标率、处理进度"
- 给安全团队看的报告:聚焦"漏洞分布、趋势变化、未处理的工单"
同一份报告给所有人看,等于没人看。
阶段三:退出——最难但也最容易被忽视的一环
引入新组件有动力——功能需求驱动。但替换旧组件没有动力——"能跑就行"。
但搁置风险不等于消灭风险。
1. 退出触发条件
以下任何一种情况都应该触发退出流程:
- 发现不可修复的高危漏洞
- 项目停止维护(废弃组件)
- License 变更导致不合规
- 业务不再需要该组件
这四种场景一旦触发,应该自动进入退出流程:系统排查 → 录入台账 → 系统整改。把存量清理作为一个正式流程来管,而不是指望开发自发去清。在这个环节,一些先行企业已经把存量治理列为单独的管理流程,有专门的责任人跟踪。
2. 退出流程
一个完整的退出流程包括:
- 影响分析——通过 SBOM 定位所有使用了该组件的服务。这一步做得好的话,定位一条依赖链应该从小时级压到分钟级。有企业在治理平台上建立了组件库+漏洞库+许可证库的关联依赖图谱,已经实现秒级定位。
- 替代方案评估——寻找功能等价、安全合规的替代品
- 替换执行——修改代码、测试验证、灰度上线
- 旧版本清理——确认所有服务已替换后,从 SBOM 和制品库中移除
3. 谁来执行退出
这是退出机制中最容易断层的一环。流程写得再好,没人执行就是废纸。
合理的责任划分:
- 发起人: 安全团队发现不可修复漏洞,或架构评审发现废弃组件 → 发起退出申请
- 执行人: 受影响服务的 owner
- 验收人: 安全团队验证所有引用已移除,架构团队确认替代方案已就位
在这个责任划分上,更细化的做法是用开源软件 Owner + 产品经理双角色制——Owner 负责选型和维护(管"选"),产品经理负责升级集成和修复验证(管"用"),权责分离、各管一段。组织大了可以用这套,小团队把发起/执行/验收三角色跑通就够。
组织保障:没有组织,流程就是空文
前面说了这么多流程设计,但如果没有人负责,一切都是白搭。
这是一个我称之为"元治理"的问题——治理别人之前,先治理自己。根据信通院可信开源治理成熟度评估体系,组织建设是评估的第一维度。我把行业里跑通的模式归纳为三种:
模式一:委员会+工作组(适合大企业,安全等级高)
三级架构:决策层(委员会制定策略)→ 执行层(工作组推动落地)→ 操作层(技术团队日常运营)。核心是把决策权和执行权分开,委员会拍板,工作组干活。比如开源治理委员会 → 工作组 → 组件管理维护 + 安全合规风控两个团队平行运作。
模式二:专职办公室+矩阵式角色(适合中型企业)
不成立专门委员会,设一个治理办公室统筹,项目管理、引入评估、安全审查、法务合规各安排一个对接人。这种方式角色清晰,成本比模式一低。
模式三:虚拟协调机制(适合小团队)
如果企业规模不大,不需要专门设一个部门。至少明确两个角色:
- 技术负责人或架构师: 负责引入审批、技术评估
- 安全负责人: 负责漏洞监控、合规检查、退出触发
组织设计的最基本原则是:每个环节都要有人负责。 没有人负责的流程,最终都会沦为没人看的文档。
三条经验
上面这些方法不是凭空想出来的,是多个企业实打实踩过的坑。说三条最有价值的。
经验一:引入流程的"度"很重要,太严了推不动,太松了没效果。
所有的组件都走审批,审批队列会积压,开发怨声载道。白名单自动通过 + 非白名单人工审批,审批压力会从"所有组件都审批"转向"只审批少数例外组件",控制力保住了,体验也没崩。
经验二:退出机制比引入机制需要更多心力去推。
引入新组件有动力(功能需求驱动),替换旧组件没有动力("能跑就行")。很多企业的退出流程写在了文档里,但从没被真正执行过。需要把漏洞修复和组件替换纳入技术债务管理,有明确的 SLA,有定期的审查。
经验三:同一份报告给所有人看,等于没人看。
给开发看的报告和给领导看的报告应该是两回事。前者要具体到"你的服务有哪些漏洞需要修",后者要宏观到"整体风险趋势和合规达标率"。信息精准分发,才有人行动。
所以,真正的治理是什么?
回到文章开头的那个银行客户。
他们不缺工具,不缺 SBOM。缺的是:
- 一个明确的组织,告诉所有人这事归谁管
- 一套可执行的流程,告诉每个人什么该做什么时候做完
- 一个闭环的机制,确保做了的事有人确认、没做的事有人追
无论监管文件怎么要求,真正要落地的始终是这些具体动作:引入前有人把关,使用中有人跟踪,出问题后有人推动退出。
工具只是手段。流程才是让治理"活起来"的东西。
流程设计到这里,只是一个开始。这些流程靠人力推动,最终还是会崩。人会遗忘,会被项目优先级挤掉,也会因为组织调整而交接断档。
要让流程真正持久运转,必须把它嵌进工程流水线里——让门禁自动拦截、让流水线自动阻断、让报告自动分发。
这就是下一篇要讲的:怎么把这三阶段的治理流程落地到 DevOps 流水线中,用工程手段保证流程不走样。
参考来源
¹ 中国人民银行、中央网信办、工业和信息化部、银保监会、证监会《关于规范金融业开源技术应用与发展的意见》,2021年9月 https://www.cac.gov.cn/2021-10/27/c_1636928705274546.htm
² 开源治理典型案例分享(汇编转),汇总自中国信通院可信开源治理评估公开资料及企业分享 https://blog.csdn.net/manok/article/details/134924332
³ 中国农业银行《传统与开源软件一体化管理体系建设实践》,北京金融科技产业联盟 https://www.bfia.org.cn/sites/home/MsgView.jsp?msgId=28303
原文地址: https://www.cveoy.top/t/topic/qGNw 著作权归作者所有。请勿转载和采集!