Agent 17 种架构模式 分析 & 思考
Agent 17 种架构模式 分析 & 思考
- Agent 17 种架构模式 分析 & 思考
- 0x00 概要
- 0x01 核心概念
- 0x02 评估维度
- 0x03 17 种架构总述
- 0x04 17 种架构逐一分析
- 4.1 Reflection (反思模式)
- 4.2 Tool Use (工具调用模式)
- 4.3 ReAct (推理-行动循环)
- 4.4 Planning (规划模式)
- 2.5 PEV (计划-执行-验证)
- 4.6 Multi-Agent (多智能体协作)
- 4.7 Blackboard (黑板架构)
- 4.8 Meta-Controller (元控制器)
- 4.9 Ensemble (集成模式)
- 4.10 Episodic & Semantic Memory (记忆模式)
- 4.11 Graph Memory (图记忆模式)
- 4.12 Tree-of-Thoughts (思维树)
- 4.13 Mental Loop / Simulator (心智模拟)
- 4.14 Dry-Run Harness (预演执行)
- 4.15 Reflexive Metacognitive (自反元认知)
- 4.16 Self-Improvement Loop (自改进循环)
- 4.17 Cellular Automata (元胞自动机)
- 4.18 常见坑
- 4.19 6 维度矩阵
- 0x05 演化路径与升级触发条件
- 0xEE 广告
- 购买链接
- 0xFF 参考来源
0x00 概要
本文是对于 https://github.com/FareedKhan-dev/all-agentic-architectures 的总结和思考:理论框架 × 统一分析 × 形式化描述 × 组合策略 × 工程实践 × 产业视角。
从0开发大模型的17种Agent架构演进详细拆解 也给我很大的启发,在此感谢。
注:太卷了太卷了。我还没看完 miles,朱大佬就放出了面向 Agent 时代的 slime v0.3.0。我写博客/写PPT的速度都比不上业界开发的速度。
所以,我接下来会把之前写的一些文章(不是那么完善)陆续放出来。因为,如果再不放出来,就过时了。
因此,会不定期打断“OpenClaw-RL”的连载(一共17篇),还请大家理解。
0x01 核心概念
对于 Agent Design Patterns,其实有两个维度可以衡量:评估维度和公式维度。评估 6 维度指定设计目标, 公式 6 维度指定设计变量。评估维度定义了优化的目标函数, 公式维度定义了可调参数的搜索空间。两者相辅相成。
1.1 设计目标(评估6维度)
有一种说法是:所有 Agent Design Patterns 本质上围绕 6 个核心维度 进行设计和权衡:
- 维度一: 🧠 推理质量 (Reasoning Quality)。其核心问题: 如何让 Agent 输出更准确、更可靠?
- 维度二: ⚡ 控制流 (Control Flow)。其核心问题: 谁决定下一步做什么? 如何决定?
- 维度三: 🔒 安全与信任 (Safety & Trust)。其核心问题: 如何确保 Agent 不做错误/危险的事?
- 维度四: 🌿 任务分解与协作 (Decomposition & Collaboration)。其核心问题: 复杂任务如何拆解? 多个执行单元如何协调?
- 维度五: 🗄️ 记忆与状态 (Memory & State)。核心问题: Agent 如何记住过去、利用经验?
- 维度六: 📊 可观测性与评估 (Observability & Evaluation)。核心问题: 如何知道 Agent 做得好不好? 如何持续改进?
本文的每个 Design Pattern 本质上是在这 6 个维度上做出特定的取舍
| Pattern | 主要侧重维度 | 牺牲的维度 |
|---|---|---|
| Reflection | 推理质量 | 延迟 (多次LLM调用) |
| Tool Use | 推理质量 (知识增强) | 成本、复杂性 |
| ReAct | 控制流灵活性 | 可预测性 |
| Planning | 任务分解 | 灵活性 (计划可能过时) |
| Multi-Agent | 任务分解 + 推理质量 | 协调成本 |
| PEV | 安全 + 可观测性 | 延迟 |
| Dry-Run Harness | 安全 | 速度 |
| Blackboard | 任务分解 (灵活协作) | 确定性 |
| Episodic + Semantic Memory | 记忆 | 系统复杂性 |
| Tree of Thoughts | 推理质量 | 计算成本 |
| Mental Loop | 安全 (预测后果) | 延迟 |
| Meta-Controller | 控制流 (智能路由) | 路由准确性依赖 |
| Ensemble | 推理质量 (多视角) | 计算成本 |
| RLHF Loop | 记忆 (经验学习) | 时间成本 |
| Reflexive Metacognitive | 安全 (自我认知) | 自主性 (会拒绝行动) |
| Cellular Automata | 任务分解 (涌现) | 可解释性 |
1.2 设计变量(公式6维度)
Agent = State × Topology(Routing) × Guards × Σ(Plugins via Hooks) × Tools(ACI) @ Mode
这个公式将 Agent 架构分解为六个正交维度,六个维度的笛卡尔积构成了架构的设计空间:
- State 承载系统记忆。
- topology + Routing 定义控制流拓扑与转移决策。
- Guard 提供安全闸门。
- Hook 提供生命周期扩展。
- ACI 定义工具接口。
- Mode 决定执行模式。
这六个正交维度涉及七个概念,具体如下:
| 概念 | 本质 | 一句话解释 |
|---|---|---|
| State | 系统快照 | 系统在任意时刻的完整状态, 包括对话历史、中间结果、memory、任务队列等 |
| Topology | 连接结构 | 节点间的静态连接关系: 线性链 / 循环 / 分叉-汇聚 / 树 / 网格 |
| Routing | 转移决策 | 在拓扑上决定下一步去向: 静态路由 / 条件分支 / LLM 动态 / 策略驱动 |
| Guard | 验证闸门 | 转移前的安全检查: 输入校验 / 边守卫 / 执行守卫 / 输出守卫 / 人工确认 |
| Hook | 扩展点 | 生命周期回调: before / after / on_error / on_timeout, 插件化插入横切逻辑 |
| Mode | 执行模式 | live(真实执行) / dry_run(副作用拦截) / simulate(反事实模拟) |
| Tool (ACI) | 接口协议 | Agent-Computer Interface: 系统与外部世界(API/DB/FS/人类)的标准化交互协议 |
1.3 联系
两套维度的核心区别: 一个是"你要什么"(评估维度), 一个是"你怎么做"(构造维度)。
映射关系如下:
| 评估维度 (WHAT) | 构造维度 (HOW) | 关系 |
|---|---|---|
| 推理质量 | Topology(Routing) + Mode | 拓扑决定推理路径, simulate 模式支撑深度推理 |
| 控制流 | Topology(Routing) | 直接对应 |
| 安全与信任 | Guards + Mode | Guard 是闸门, dry_run 是沙盒 |
| 任务分解与协作 | Topology (多节点/DAG/Fan-out) | 协作结构被编码在拓扑里 |
| 记忆与状态 | State | 直接对应 |
| 可观测性与评估 | Hooks + Guards | Hook 埋点做观测, Guard 做评估 |
1.4 产业视角: ETCLSVG 七层分类法
来源: Agent Harness Engineering: A Survey (Li et al., 2026)
| 层级 | 英文 | 中文 | 关注点 |
|---|---|---|---|
| E | Execution | 执行环境 | 沙箱、容器、进程隔离、blast radius 控制 |
| T | Tooling | 工具集成 | ACI 标准化、工具注册、schema 管理 |
| C | Context | 上下文管理 | 窗口压缩、memory 检索、上下文组装 |
| L | Lifecycle | 生命周期 | 任务编排、状态转移、终止条件、重试策略 |
| O | Observability | 可观测性 | 追踪、日志、指标、归因分析 |
| V | Verification | 验证体系 | Guard、evaluator、输出校验、一致性检查 |
| G | Governance | 治理控制 | 权限、审计、合规、成本控制、人机协作 |
与七核心概念的映射:
| 核心概念 | 对应 ETCLSVG 层 |
|---|---|
| State | C (Context) |
| Topology + Routing | L (Lifecycle) |
| Guard | V (Verification) |
| Hook | L + V (Lifecycle + Verification) |
| Mode | E (Execution) |
| Tool (ACI) | T (Tooling) |
本篇的 17 种模式分析主要覆盖 L (Lifecycle) 和 V (Verification) 两层,E (Execution) 和 G (Governance) 更多的是从实践角度进行补充。
0x02 评估维度
我们再来分析下评估维度(其中涉及到的模式并不限于本篇的17种模式)。
2.1 维度一: 推理质量 (Reasoning Quality)
核心问题: 如何让 Agent 输出更准确、更可靠?
| 策略 | 对应模式 | 机制 |
|---|---|---|
| 自我纠正 | Reflection, Evaluator-Optimizer | 迭代审视 → 改进 |
| 多路径探索 | Tree of Thoughts | 生成多个方案 → 评估 → 选最优 |
| 多视角综合 | Ensemble, Voting | 不同 agent/prompt 独立分析 → 聚合 |
| 知识增强 | Tool Use, RAG, Graph Memory | 外部知识弥补 LLM 知识盲区 |
设计思考: 单次 LLM 调用的推理有上限, 如何通过 结构化的多步过程 突破这个上限?
2.2 维度二: 控制流 (Control Flow)
核心问题: 谁决定下一步做什么? 如何决定?
| 策略 | 对应模式 | 机制 |
|---|---|---|
| 预定义路径 | Prompt Chaining | 代码编排, 确定性 |
| 条件路由 | Routing, Meta-Controller | LLM 分类后走固定分支 |
| 动态循环 | ReAct, PEV | LLM 每步决定继续/停止 |
| 完全自主 | Autonomous Agent | LLM 控制全部决策, 步骤数不确定 |
设计思考: 确定性 vs 灵活性 的权衡—越自主越强大, 但越难控制和预测。
2.3 维度三: 安全与信任 (Safety & Trust)
核心问题: 如何确保 Agent 不做错误/危险的事?
| 策略 | 对应模式 | 机制 |
|---|---|---|
| 预执行模拟 | Dry-Run Harness, Mental Loop | 先模拟后执行, 可回滚 |
| 人工门控 | Human-in-the-Loop | 关键操作前需人类批准 |
| 自动验证 | PEV (Plan-Execute-Verify) | 每步执行后自动校验结果 |
| 自我认知 | Reflexive Metacognitive | Agent 知道自己不知道什么, 主动升级 |
| 并行护栏 | Guardrails (Parallelization) | 护栏与主逻辑并行运行, 不阻塞 |
设计思考: Agent 的 能力边界 在哪里? 如何让它在边界内自主、在边界外求助?
2.4 维度四: 任务分解与协作 (Decomposition & Collaboration)
核心问题: 复杂任务如何拆解? 多个执行单元如何协调?
| 策略 | 对应模式 | 机制 |
|---|---|---|
| 静态分解 | Planning, Prompt Chaining | 预先规划步骤 |
| 动态分解 | Orchestrator-Workers | 运行时根据输入决定子任务 |
| 角色专业化 | Multi-Agent, Meta-Controller | 每个 agent 有专长 |
| 共享工作空间 | Blackboard | 通过共享状态间接协作 |
| 并行独立 | Parallelization, Ensemble | 无依赖的并行执行 |
设计思考: 分工的粒度和协调成本 的平衡—拆得太细协调开销大, 拆得太粗失去专业性优势。
2.5 维度五: 记忆与状态 (Memory & State)
核心问题: Agent 如何记住过去、利用经验?
| 策略 | 对应模式 | 机制 |
|---|---|---|
| 短期工作记忆 | State (TypedDict/Pydantic) | 图的状态对象, 单次执行内 |
| 情景记忆 | Episodic Memory (FAISS) | 过去对话的向量检索 |
| 语义记忆 | Semantic Memory (Neo4j) | 结构化知识图谱 |
| 涌现记忆 | Cellular Automata | 局部状态 → 全局模式 |
设计思考: LLM 无状态, 如何用 外部存储 + 检索机制 赋予它"记忆"和"学习"能力?
2.6 维度六: 可观测性与评估 (Observability & Evaluation)
核心问题: 如何知道 Agent 做得好不好? 如何持续改进?
| 策略 | 对应模式/工具 | 机制 |
|---|---|---|
| 执行追踪 | LangSmith, OpenTelemetry | 每个节点/工具调用的 trace |
| 离线评测 | Datasets + LLM-as-Judge | 基准测试、回归检测 |
| 在线评测 | Online Scoring | 生产流量实时打分 |
| 中间步骤评估 | Trajectory evaluation | 不只看最终结果, 看路径质量 |
| 反馈闭环 | Production → Dataset → Eval → Improve | bad case 反哺测试集 |
设计思考: Agent 行为非确定性, 传统的"对/错"测试不够, 需要 概率性的、多维度的评估体系。
0x03 17 种架构总述
3.1 统一形式化框架
我们可以把Agent 系统定义为一个六元组,后续会据此对17种架构进行分析。
A = (S, T, δ, s₀, F, Γ)
S = 状态空间 (所有可能的系统状态)
T = 拓扑结构 (有向图 G(V, E), 节点 v ∈ V 为处理单元, 边 e ∈ E 为转移路径)
δ = 转移函数 δ: S × E → S (在当前状态 s 下沿边 e 转移到新状态 s')
s₀ = 初始状态 (s₀ ∈ S)
F = 终止条件集合 (F ⊆ S, 系统进入任意 f ∈ F 则停止)
Γ = 不变量集合 (∀ 状态 s 在合法执行路径上, s 必须满足 Γ 中的所有约束)
3.2 演化路径与升级触发
3.2.1 演化图
17 个模式的演化路径与条件如下:
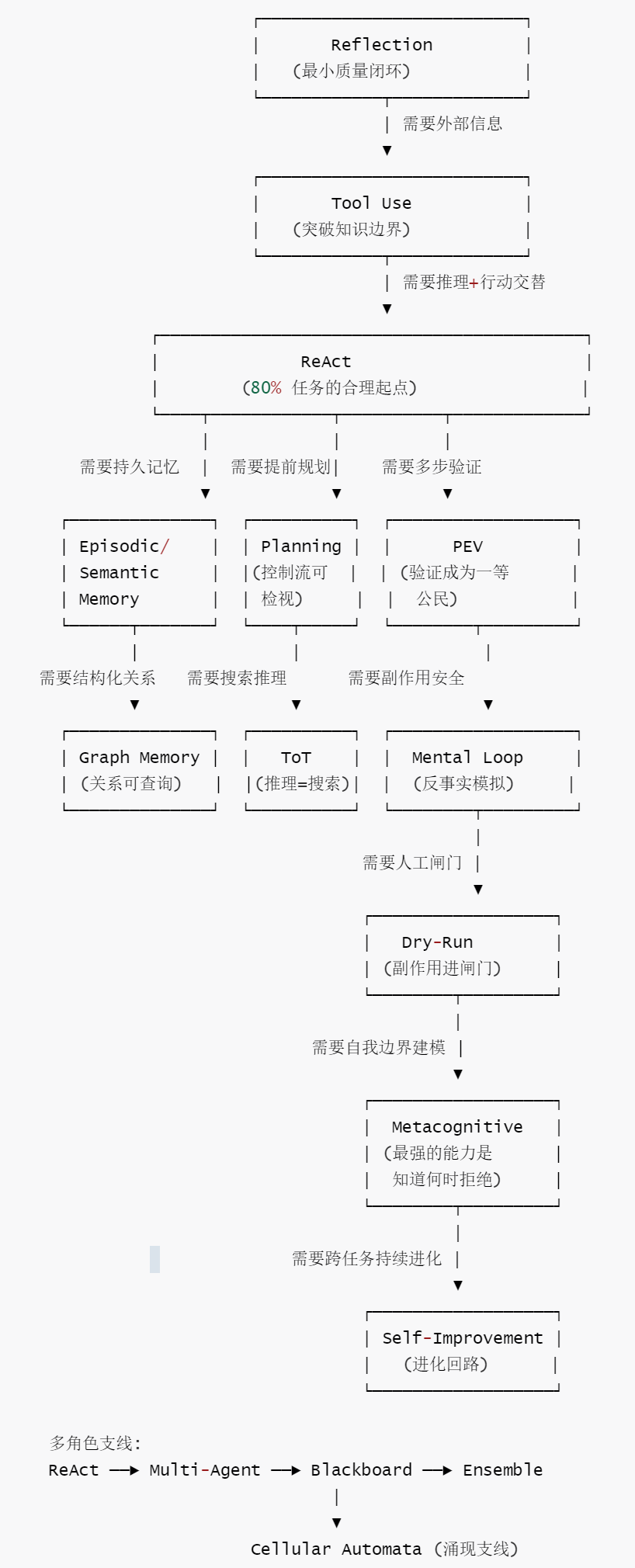
3.2.2 升级触发条件表
这些模型彼此升级之间的关系如下。
| 当前架构 | 触发信号 | 升级方向 |
|---|---|---|
| 单次 LLM 调用 | 输出质量不稳定, 需要自查 | Reflection |
| Reflection | critique 缺乏外部信息, 需要查资料 | Tool Use |
| Tool Use | 工具调用间需要推理链条 | ReAct |
| ReAct | 输出重复循环, 缺乏全局视角 | Planning |
| ReAct | 需要记住用户偏好和历史 | + Memory |
| ReAct | 需要多个专家角色协作 | Multi-Agent |
| Planning | plan 执行后结果不对但未被发现 | PEV |
| PEV | 验证器本身不可靠, 需要冗余 | Ensemble |
| Multi-Agent | 角色固定但任务类型多变, 需动态调度 | Blackboard |
| PEV | 执行前需要预判, 不能先做了再说 | Mental Loop |
| Mental Loop | 模拟与现实可能有差异, 需要真实环境 | Dry-Run |
| Dry-Run | 人工审批成为瓶颈, 需要自主判断 | Metacognitive |
| Metacognitive | 判断能力停滞, 需要从经验学习 | Self-Improvement |
3.2.3 成熟度“模型”
我们可以将这些模式分为几个等级。
| 等级 | 特征 | 典型架构组合 | 适用场景 |
|---|---|---|---|
| L1 基础 | 单次 LLM 调用, 无状态, 无工具 | 裸 prompt | 简单 Q&A, 文本分类, 摘要 |
| L2 交互 | 多轮对话, 有 tool use, 有基本循环 | ReAct + Tool Use | 客服, 信息检索, 简单自动化 |
| L3 可控 | 有规划, 有验证, 有终止保证 | Planning + PEV | 代码生成, 数据处理 pipeline |
| L4 可靠 | 多 agent 协作, 有 memory, 有安全闸门 | Multi-Agent + Memory + Dry-Run | 生产级自动化, 金融/医疗 |
| L5 自适应 | 自我评估, 自我改进, 自主边界判断 | Metacognitive + Self-Improvement | 研究型 agent, 长期自主运行 |
升级路径: L1 → L2 → L3 → L4 → L5
不要跳级原则:
- 在没有 Tool Use (L2) 前不要上 Multi-Agent (L4)——因为你还不知道单 agent + 工具的能力边界在哪里
- 在没有 PEV (L3) 前不要上 Dry-Run (L4)——因为你还不知道哪些步骤需要人工闸门
- 在没有 Memory (L4) 前不要上 Self-Improvement (L5)——因为 gold 积累需要持久化基础设施
3.3 跨层张力
来源: ETCLSVG 研究揭示的 agent 系统内在矛盾。
1. Cost-Quality-Speed 三难困境
问题: 更多验证 → 更高质量 → 更高成本 + 更高延迟。
应对: 分层验证策略——关键步骤深度验证, 常规步骤采样验证, 低风险步骤跳过验证。
2. Capability-Control 权衡
问题: 更强的 agent (更多工具+更自主) → 更难控制 (blast radius 更大)。
应对: Guard 应该随 capability 同步升级。每新增一个 tool, 至少新增一个对应的 guard。
3. Harness 耦合问题
问题: agent 代码与 LLM 能力强耦合。模型升级后, prompt 策略/验证逻辑/超参可能失效。
应对: 将 LLM 依赖隔离在可替换的 "reasoning layer" 中, harness 逻辑保持模型无关。
4. 自适应简化
"每一个 wrapper 都编码了一个假设。"
问题: 随着模型能力提升, 许多 wrapper (如手工验证规则) 可能成为不必要的瓶颈。
应对: 持续评估每个 wrapper/guard 的边际贡献。当 LLM 在某个任务上 pass rate > 99% 时, 考虑降级为采样验证。
3.4 统一分析法: 6 个固定问题
对任意 Agent 架构, 回答以下 6 个问题即可完成基本分析:
- 它要解决什么问题? —— 该模式的原始动机和核心场景
- 它的 State 是什么? —— 状态空间 S 的结构定义
- 它的拓扑是什么? —— 节点连接方式
- 它的 Router 怎么工作? —— δ 转移函数的决策逻辑
- 它的失败模式是什么? —— 常见退化场景及根因
- 什么时候该升级到下一种? —— 能力边界与升级触发信号
3.5 速查工具
3.5.1 三问判断法
面对一个新提出的"架构", 问三个问题:
- 新增了什么 State? —— 有没有引入新的状态字段或状态结构?
- 新增了什么 Router? —— 有没有引入新的路由决策机制?
- 新增了什么 Evaluator? —— 有没有引入新的验证或评估方式?
→ 三个都答不出来 = 不是新架构, 只是已有模式的变体或重命名。
3.5.2 三条核心设计原则
- 从终止性开始设计: 先定义"系统在什么条件下停止", 再倒推状态和转移
- 从失败模式开始选型: 不是"我需要什么能力", 而是"我最不能接受什么失败"
- 从最简组合开始: 从 ReAct 出发, 只在明确触发信号下叠加新模式
3.5.3 终极三句话
- 先把状态和控制流画清楚 —— 画出 S 和 δ, 一切架构讨论从此开始
- 大多数系统从 ReAct 起步, 可靠系统引入验证/记忆/边界控制 —— 不要过早设计
- 真正高级的 agent 不是更敢做事, 而是更知道什么时候不该做 —— 拒绝 > 幻觉
0x04 17 种架构逐一分析
4.1 Reflection (反思模式)
基础
定义: 一个线性三步流水线,LLM 先生成、再批评、再改进自己的输出,无需外部工具即可提升质量。
核心思想: LLM 做 critic 比做 generator 更稳定。把生成拆成 "创作" 和 "评估" 两个 pass, 比单次尝试效果更好。
核心工作流: ① LLM 生成初始草稿 → ② Critic LLM 审视草稿并输出批评意见 → ③ Refiner LLM 根据批评改进草稿 → ④ 输出最终优化结果。
形式化描述:
S = {s₀} ∪ {(d, c, r) | d ∈ Drafts, c ∈ Critiques, r ∈ Refinements}
δ : s₀ → draft → critique → refined → F
F = {refined} (单一终止状态)
Γ = {critique ≠ ∅, refined ≠ draft}
终止性: 结构性终止 —— 三步走完即终止, 无循环。
示意图
Generator ----> Critic ----> Refiner ----> Final Output
(LLM) (LLM) (LLM)
draft critique refined
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | LLM 输出质量不稳定, 需要自检自修闭环 |
| 2. State | S = {draft, critique, refined}, 三个离散阶段 |
| 3. 拓扑 | 线性三步链: Generate → Critique → Refine |
| 4. Router | 静态: 始终沿 draft → critique → refined 单向流动 |
| 5. 失败模式 | critique 泛泛而谈; refine 不收敛; 无外部信息注入导致"自说自话" |
| 6. 何时升级 | 需要外部工具获取新信息时 → Tool Use; 需要多步交互时 → ReAct |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 线性链 |
| Routing | 静态 |
| Guard | 无 (最小实现) |
| Mode | live |
| 核心维度 | State + Topology |
核心洞察: LLM 作为 critic 比作为 generator 更稳定。把生成和评判分离, 是最小但最有效的质量闭环。
4.2 Tool Use (工具调用模式)
基础
定义: LLM 可以调用外部工具(API、数据库、计算器)来获取训练数据之外的真实世界信息,然后综合结果。
核心思想: 突破不在于 "会函数调用", 而在于文本控制流可以跨越到结构化世界再返回。真正的难点是序列化 / 反序列化,不是 prompting。
核心工作流: ① 用户发起请求 → ② LLM 决定是否需要调用工具及调用哪个 → ③ 执行工具调用并获取结构化结果 → ④ LLM 综合工具返回结果生成最终回答。
形式化描述:
S = H × TC × TR (H=对话历史, TC=tool calls, TR=tool results)
δ : (h, ∅, ∅) → (h, tc, ∅) → (h, tc, tr) → F (每次工具调用)
F = {s | LLM 输出不含 tool_call}
Γ = {∀ tc ∈ TC, tc.tool_name ∈ RegisteredTools}
终止性: 条件终止 —— 需 max_iterations 兜底, 防止 tool-call loop。
示意图
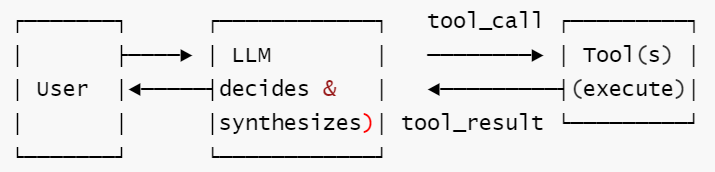
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | LLM 知识有截止日期, 无法访问外部系统 |
| 2. State | S = |
| 3. 拓扑 | LLM ⇄ Tool 双向交互, 可多轮 |
| 4. Router | LLM 动态决定是否调用工具、调用哪个工具 |
| 5. 失败模式 | tool hallucination (调用不存在的工具); 参数错误; tool 返回超长截断 |
| 6. 何时升级 | 需要在工具调用间加入推理时 → ReAct |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 星形 (LLM 为中心, tool 为叶子) |
| Routing | LLM 动态 |
| Guard | tool schema 校验 |
| Mode | live |
| 核心维度 | ACI |
核心洞察: Tool Use 首次将 文本控制流 跨越到 结构化世界。tool_call 是 agent 的行动边界第一次突破语言.
4.3 ReAct (推理-行动循环)
基础
定义: 一个迭代循环,LLM 交替进行思考(推理下一步做什么)、行动(调用工具)、观察(处理结果), 直到任务完成。
核心思想: 从工具结果反馈到 LLM 的那条回边,是整个 agent 架构中最重要的结构元素。这是 80% 任务的合理起点。
核心工作流: ① LLM 推理当前状态并决定下一步行动 → ② 执行工具调用(Action) → ③ 接收工具返回的观测结果(Observation) → ④ 循环回到①直到 LLM 判断任务完成,输出最终答案。
形式化描述:
S = (T × A × O)^k × T (T=Thought, A=Action, O=Observation)
δ : (..., t_i) → (..., t_i, a_i) → (..., t_i, a_i, o_i) → (..., t_{i+1})
F = {s | t_k = "Final Answer" ∨ k ≥ max_iterations}
Γ = {∀ a_i, a_i ∈ AvailableActions}
终止性: 条件终止 —— 需 max_iterations 兜底 (工程上推荐默认值 20-50)。
示意图
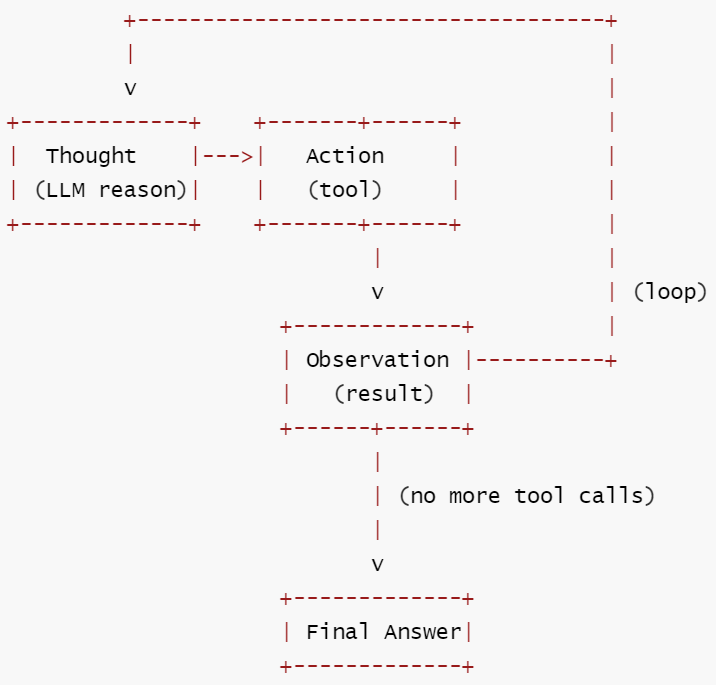
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 复杂任务需要推理与行动的交替迭代 |
| 2. State | S = {(thought, action, observation)^k}, k 为已执行轮次 |
| 3. 拓扑 | 循环: Thought → Action → Observation → Thought → ... |
| 4. Router | LLM 在每轮生成 thought+action, observation 由环境返回 |
| 5. 失败模式 | 循环不收敛; action 重复; thought 与 action 脱节 |
| 6. 何时升级 | 需要提前规划时 → Planning; 需要多角色时 → Multi-Agent |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 循环 (自环) |
| Routing | LLM 动态 |
| Guard | action schema 校验 |
| Mode | live |
| 核心维度 | Topology (首个循环拓扑) |
核心洞察: ReAct 让 Agent 真正成形。Thought→Action→Observation 是最小但完整的感知-决策-行动闭环, 也是 80% 任务的合理起点。
4.4 Planning (规划模式)
基础
定义: LLM 先生成一个显式的分步计划,然后逐步执行每一步,使控制流本身成为一等可检视对象。
核心思想: Planning 新增的不是 "更聪明的思考", 而是让控制流变得可视、可修改、可审计。plan 队列单调递减 — 这是终止性的保证。
核心工作流: ① LLM 生成显式分步计划(plan 队列) → ② 按序取出下一步并执行 → ③ 将中间结果存入状态 → ④ 重复②直到 plan 为空,综合所有结果输出。
形式化描述:
S = (P, i, R) 其中 P = [step₁, step₂, ..., stepₙ] 为计划队列
i 为当前步骤索引, R 为已执行步骤结果
δ : (P, i, R) → execute(stepᵢ) → (P, i+1, R∪{resultᵢ})
∨ replan → (P', 0, R) (当 resultᵢ 偏离预期)
F = {s | i = |P| ∨ |P| = 0} (计划执行完毕)
Γ = {|P| 单调递减 (无 replan 时), ∀ step ∈ P, step.is_executable}
终止性: 有界终止 —— 无 replan 时 plan 队列单调递减; 有 replan 时仍需 max_iterations。
示意图

扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 复杂多步任务的全局编排, 避免 ReAct 短视 |
| 2. State | S = |
| 3. 拓扑 | 外层循环: Plan → Execute_Step → Update → Plan(replan?) |
| 4. Router | LLM 生成 plan 队列, 每步后检查是否需 replan |
| 5. 失败模式 | plan 过于抽象无法执行; plan 偏差累积; 频繁 replan 震荡 |
| 6. 何时升级 | 需要验证每步结果时 → PEV; 需要多角色协作时 → Multi-Agent |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 带条件分支的循环 |
| Routing | LLM 动态 + 计划偏移检测 |
| Guard | step 可执行性检查 |
| Mode | live |
| 核心维度 | State (plan 作为一等公民) |
核心洞察: Planning 不是"更聪明的思考", 而是 把控制流变成可检视对象。plan 是一个可以审计、可打断、可恢复的数据结构。
2.5 PEV (计划-执行-验证)
基础
定义: 在 Planning 基础上增加验证步骤。每次执行后验证结果,失败则重试或重新规划,确保错误不会静默传播。
核心思想: 执行不再是 "完成了一步", 而是 "产生了一个待验证结果"。验证让失败变得显式,而非默认传播。
核心工作流: ① 生成执行计划 → ② 执行当前步骤 → ③ 验证执行结果(通过则进入下一步,失败则重试或重新规划) → ④ 全部步骤通过验证后,综合输出最终结果。
形式化描述:
S = (P, i, R, V) 其中 V = {pass, fail, uncertain}
δ : (P, i, R, ∅) → execute → (P, i, R∪{r}, ∅) → verify → (P, i, R, v)
→ (v=pass ? (P, i+1, R, ∅) : (P, i, R, ∅)) -- 重试或 replan
F = {s | i = |P| ∧ ∀ v_j ∈ V_history, v_j = pass}
Γ = {verifier ∉ executor (独立性要求), ∀ step, step.verified_before_proceed}
终止性: 条件终止 —— 需要 max_retries + max_iterations 双重兜底。
示意图
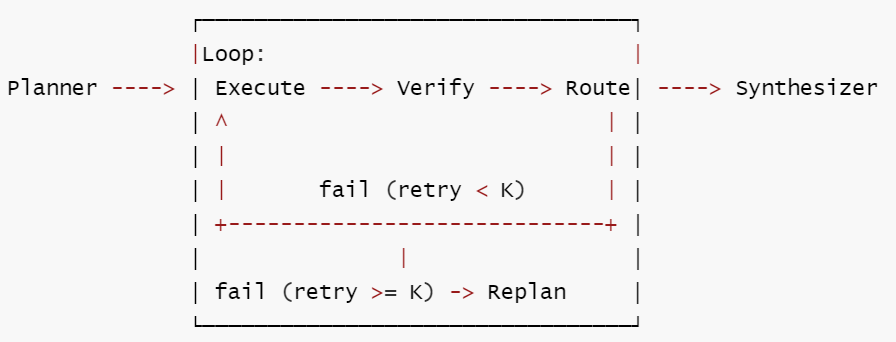
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 执行步骤后结果无声传播错误 |
| 2. State | S = |
| 3. 拓扑 | Plan → Execute → Verify → (pass? next : retry/replan) |
| 4. Router | 基于 verification_result 分支: pass → 下一步, fail → 重试或 replan |
| 5. 失败模式 | verifier 漏检; 过度验证导致效率低; verifier 与 executor 同源偏差 |
| 6. 何时升级 | 需要冗余而非单点验证时 → Ensemble; 需要预执行安全时 → Dry-Run |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | Plan→Execute→Verify 三元组循环 |
| Routing | 验证驱动的条件分支 |
| Guard | 输出守卫 (verification 作为独立闸门) |
| Mode | live |
| 核心维度 | Guard (验证成为一等公民) |
核心洞察: PEV 的核心贡献是让 验证成为一等公民。S 新增 verification_result 字段, 错误不再静默传播, 每个 step 的输出必须"签字画押"。
4.6 Multi-Agent (多智能体协作)
基础
定义: 多个具有不同角色(人设 / 工具)的 LLM Agent 按固定流水线排列,每个处理自己的领域后将结果传给综合器。
核心思想: 把单个 prompt 中的隐式角色切换变成显式独立节点。工程收益:每个 agent 可单独调试、替换、评估、赋予不同工具。
核心工作流: ① 任务分解为子领域 → ② 角色分配(给各专家 Agent) → ③ 按流水线协作(前一个的输出是后一个的输入) → ④ 由 Synthesize Agent 汇总所有角色产出,生成最终结果。
形式化描述:
S = (Agent₁.output, Agent₂.output, ..., Agentₙ.output) × SharedContext
δ : (∅, ∅, ..., ∅, ctx) → (a₁_out, ∅, ..., ∅, ctx) → (a₁_out, a₂_out, ..., ∅, ctx)
→ ... → (a₁_out, ..., aₙ_out, ctx) → F
F = {s | ∀ i ∈ [1, n], Agentᵢ.output ≠ ∅}
Γ = {∀ i, Agentᵢ.output.schema ∈ expected_input_schema(Agentᵢ₊₁)}
终止性: 结构性终止 —— 固定流水线走完即终止。
示意图
Agent A ----> Agent B ----> Agent C ----> Synthesizer ----> Output
(Finance) (Tech) (Legal) (aggregate)
role_A role_B role_C
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 单 Agent 能力边界有限, 需要认知分工 |
| 2. State | S = |
| 3. 拓扑 | 固定流水线: Agent₁ → Agent₂ → ... → Agentₙ, 或有向无环图 (DAG) |
| 4. Router | 静态: 按预设顺序传递, 每个 agent 的输出作为下一个 agent 的输入 |
| 5. 失败模式 | agent 间接口不对齐; 上游错误级联放大; 角色职责重叠或遗漏 |
| 6. 何时升级 | 需要动态调度 agent 时 → Blackboard; 需要中心路由时 → Meta-Controller |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | DAG (流水线) |
| Routing | 静态 (预设顺序) |
| Guard | agent 间 schema 校验 |
| Mode | live |
| 核心维度 | Topology (多节点) |
核心洞察: Multi-Agent 的精髓不是"让多个 LLM 聊天", 而是 把认知分工写进图里。每个 agent 可单独调试、替换、评估——这是从 craft 到 engineering 的关键一步。
4.7 Blackboard (黑板架构)
基础
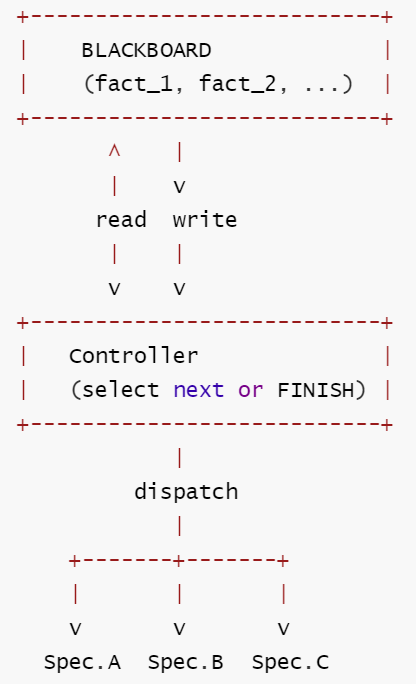
定义: 共享工作区(黑板)是系统中心。Controller LLM 读取黑板状态,动态选择下一个要调用的 specialist agent。
核心思想: 控制从 "预定义工作流" 转向 "共享状态 + 调度器"。黑板积累知识;controller 根据已有内容决定还需要什么。
核心工作流: ① Controller 读取黑板当前状态 → ② 动态选择最合适的 Specialist Agent → ③ Specialist 执行任务并将结果写回黑板 → ④ 循环回到①直到 Controller 判断信息充分,输出 FINISH。
形式化描述:
S = (BB, H) 其中 BB 为黑板字典, H 为调度历史
δ : (BBₜ, H) → Controller.select(BBₜ) → specialistᵢ(BBₜ) → (BBₜ₊₁, H∪{i})
∨ (BBₜ satisfies goal) → F
F = {s | goal_condition(BB) = true ∨ |H| ≥ max_steps}
Γ = {∀ write to BB, write.key ∈ RegisteredKeys, BB 始终为合法状态}
终止性: 条件终止 —— 需 goal_condition 或 max_steps 兜底。
示意图
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 问题求解需要多个专家动态协作, 无法预设固定顺序 |
| 2. State | S = |
| 3. 拓扑 | 星形: Controller 读写 Blackboard, 激活对应 Specialist |
| 4. Router | Controller 基于 blackboard 快照动态选择 specialist (条件+LLM) |
| 5. 失败模式 | blackboard 信息冲突; Controller 调度不稳; specialist 饥饿 |
| 6. 何时升级 | 需要大规模并行时 → Ensemble; 需要自我边界判断时 → Metacognitive |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 星形 (Blackboard 为中心) |
| Routing | 条件+LLM 动态 (Controller 决策) |
| Guard | BB 写入校验 |
| Mode | live |
| 核心维度 | State (共享状态成为系统中心) |
核心洞察: Blackboard 的精髓是把 共享状态提升为系统中心。Controller 不只路由, 它在监控一个不断演化的信息集合。这是从"消息传递"到"状态管理"的范式转换。
4.8 Meta-Controller (元控制器)
基础
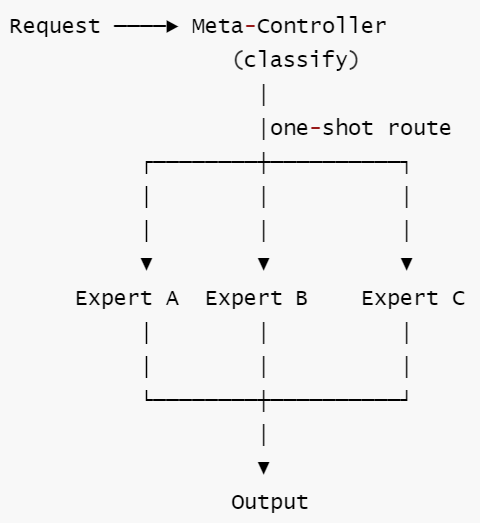
定义: 一次性路由器,将传入请求分类后派发给对应的 specialist agent。路由器本身不执行任何任务。
核心思想: 像 "分诊台" 而非 "总控台"。由于其简单性和可预测性,这是生产多 agent 系统最常见的起步架构。
核心工作流: ① 接收用户请求 → ② Meta-Controller 对请求进行一次性分类 → ③ 路由到对应领域的 Expert Agent 执行 → ④ Expert 完成任务后直接输出结果。
形式化描述:
S = (q, c, r) 其中 c ∈ Categories, r ∈ Results
δ : (q, ∅, ∅) → classify → (q, c, ∅) → route(c) → specialist_c(q) → (q, c, r) → F
F = {s | r ≠ ∅}
Γ = {c ∈ KnownCategories, route(c) ∈ Registered Specialists, specialist_c 匹配 c}
终止性: 结构性终止 —— 两步固定流程。
示意图
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 用户请求类型多样, 需要一次性路由到正确的下游系统 |
| 2. State | S = |
| 3. 拓扑 | 两步固定: Classify → Route → Specialist |
| 4. Router | 第一次 LLM 调用做分类, 然后静态映射 category → specialist |
| 5. 失败模式 | 分类错误导致路由到错误 specialist; 边界 case 无匹配 |
| 6. 何时升级 | 需要并行调用多个 specialist 时 → Ensemble |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 两层树 (根→分类→叶) |
| Routing | LLM 分类 + 静态映射 |
| Guard | 分类结果校验 |
| Mode | live |
| 核心维度 | Routing (路由是全部) |
核心洞察: Meta-Controller 是架构中最"轻"的模式——一次性路由。像分诊台: 不治病, 只判断该去哪个科室。它的价值在于把路由决策本身变成一个可审计的步骤。
4.9 Ensemble (集成模式)
基础
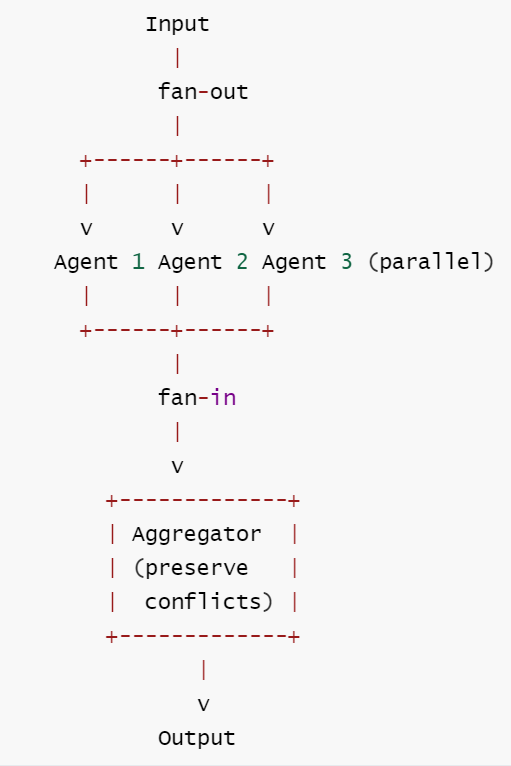
定义: 多个 agent 独立并行处理相同输入,然后由聚合器将多元视角合并为最终建议。
核心思想: 价值不在于取平均,而在于保留冲突。冗余降低个体偏差,聚合器必须暴露分歧而非掩盖它。
核心工作流: ① 将同一输入分发(Fan-out)给多个独立 Agent → ② 各 Agent 并行处理,产出独立见解 → ③ Aggregator 收集所有见解并识别分歧 → ④ 综合多元视角输出最终建议(保留冲突信息)。
形式化描述:
S = (q, O, A) 其中 O = [o₁, o₂, ..., oₙ], n ≥ 2, A 为聚合结果
δ : (q, ∅, ∅) → fan_out → (q, ∅, ∅) → ∥ᵢ modelᵢ(q) → (q, O, ∅) → aggregate → (q, O, A) → F
F = {s | A ≠ ∅}
Γ = {n ≥ 2, ∀ i ≠ j, modelᵢ ≠ modelⱼ ∨ promptᵢ ≠ promptⱼ, 冲突必须保留在 O 中}
终止性: 结构性终止 —— Fan-out → Parallel → Fan-in 一步完成。
示意图
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 单模型有盲区, 需要多角度冗余覆盖 |
| 2. State | S = |
| 3. 拓扑 | Fan-out → Parallel → Fan-in: 一分多 → 并行执行 → 汇聚 |
| 4. Router | Fan-out: 复制到 N 个模型/agent; Fan-in: 聚合策略 (投票/加权/LLM 评判) |
| 5. 失败模式 | 所有模型同时错; 聚合策略掩盖重要分歧; 成本线性增长 |
| 6. 何时升级 | 需要认知分工而非冗余时 → Multi-Agent; 需要自我评估时 → Metacognitive |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | Fan-out → Fan-in |
| Routing | 静态 fan-out + 策略 fan-in |
| Guard | 多样性校验 (model/prompt 不重复) |
| Mode | live |
| 核心维度 | Topology (并行) + Guard (冲突保留) |
核心洞察: Ensemble 的关键不是取平均, 是 保留冲突。如果三个模型给出三种答案, 这不叫失败——这叫信息。聚合策略必须保留分歧而不是抹平它。
4.10 Episodic & Semantic Memory (记忆模式)
基础
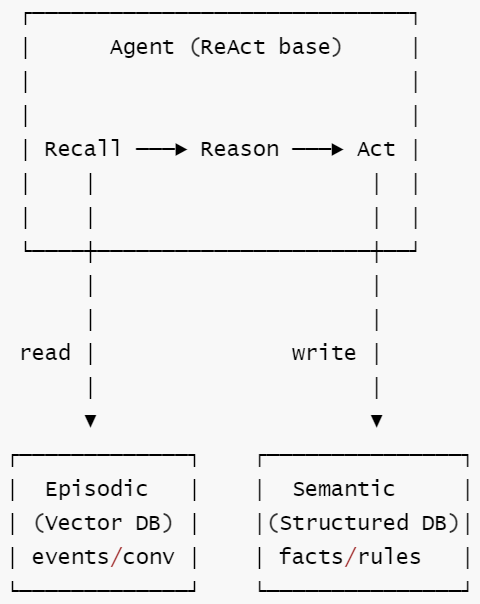
定义: 在基础 agent(通常是 ReAct)上扩展持久外部记忆 — 情景记忆(事件历史存为向量)和语义记忆(结构化事实), 支持跨会话学习。
核心思想: 记忆让系统更强大,但也让错误变得持久。关键设计决策是:何时检索、何时写入、如何防止记忆污染。
核心工作流: ① Agent 推理前先从记忆库检索相关历史(Recall) → ② 结合当前上下文和历史记忆进行推理 → ③ 执行行动并获取结果 → ④ 对话结束后提取新知识写入记忆库(情景事件→向量库,结构化事实→知识库)。
形式化描述:
S = S_core × M_e × M_s (核心状态 × 情节记忆 × 语义记忆)
δ : (s, M_e, M_s) → retrieve(q, M_e, M_s) → inject(s, memories) → act(s') → store(outcome, M_e, M_s)
F = S_core 的终止条件 (继承自主架构)
Γ = {store 仅在 outcome.verified = true 时触发, |M_e| ≤ max_episodes, |M_s| ≤ max_entries}
终止性: 继承自主架构 (通常是条件终止)。
示意图
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | agent 缺乏跨对话/跨任务的持久记忆 |
| 2. State | S 扩展为 S × M_episodic × M_semantic, memory 在"图外"可检索 |
| 3. 拓扑 | agent 主循环 + memory 读写分支 (写入: store; 读取: retrieve → inject) |
| 4. Router | 基于相似度检索 (embedding/关键词); 写入: 基于重要性阈值 |
| 5. 失败模式 | 检索噪音; 记忆膨胀; 错误记忆持久化污染后续任务 |
| 6. 何时升级 | 需要结构化关系时 → Graph Memory |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 主循环 + 读写侧枝 |
| Routing | 相似度检索 |
| Guard | 写入前验证 (重要性阈值+结果校验) |
| Mode | live |
| 核心维度 | State (外延扩展) |
核心洞察: Memory 把 State 从"图内"扩展到了"图外"。memory 让错误变持久——如果存储了错误经验, 它会系统性地污染所有后续任务。Memory 的写入门槛应该高于读取门槛。
4.11 Graph Memory (图记忆模式)
基础
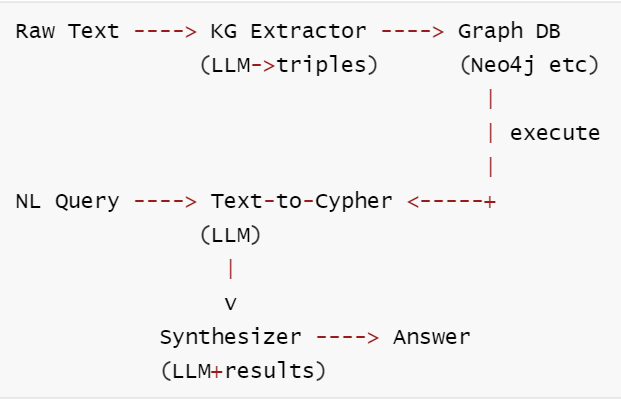
定义: 使用知识图谱(实体 + 关系)作为记忆基底,通过 Text-to-Cypher 实现向量检索无法处理的多跳关系查询。
核心思想: 关键不只是 LLM 的智能,而是整个知识建模链条:抽取→存储→查询→综合。图结构支持关于关系的结构化推理。
核心工作流: ① 从原始文本中抽取实体和关系三元组 → ② 存入图数据库构建知识图谱 → ③ 将自然语言查询转为 Cypher 并在图上执行 → ④ LLM 综合查询结果生成最终答案。
形式化描述:
S = (q, cypher, graph_result, context, response)
δ : (q, ∅, ∅, ∅, ∅) → text2cypher → (q, c, ∅, ∅, ∅) → query → (q, c, R, ∅, ∅)
→ augment → (q, c, R, ctx, ∅) → generate → (q, c, R, ctx, resp) → F
F = {s | resp ≠ ∅}
Γ = {cypher 语法合法, R ⊆ GraphDB, ctx = q + format(R)}
终止性: 结构性终止 —— 固定流水线。
示意图
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 需要结构化关系推理, 超越向量相似度匹配 |
| 2. State | S 扩展包含 KnowledgeGraph (Entity-Relationship 图) |
| 3. 拓扑 | 线性流水线: NL→Cypher→GraphDB→Context→Response |
| 4. Router | 静态: Text-to-Cypher 翻译后查询图数据库, 结果注入上下文 |
| 5. 失败模式 | Cypher 生成错误 (语法/语义); 图 schema 与自然语言不对齐; 空查询结果 |
| 6. 何时升级 | 需要搜索而非检索时 → ToT |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 线性流水线 |
| Routing | 静态 |
| Guard | Cypher 语法校验 + 查询沙箱 |
| Mode | live |
| 核心维度 | State (结构化图记忆) |
核心洞察: Graph Memory 的价值不在图数据库本身, 而在于 关系变得可查询。"A 和 B 是什么关系?"——这个问题向量数据库回答不好, 但一个 JOIN 就能回答。
4.12 Tree-of-Thoughts (思维树)
基础
定义: 将线性推理变为树搜索 — 展开多条候选思维路径,评估打分,剪枝无效分支,使用程序化搜索控制(BFS/DFS)。
核心思想: 永远不要把搜索控制交给 LLM— 交给代码。LLM 的职责只是生成候选和打分。代码管理分支、回溯和终止。
核心工作流: ① 代码控制展开多条候选思维路径 → ② LLM 对每条路径打分评估 → ③ 代码根据分数剪枝无效分支 → ④ 继续向下展开有效分支,直到找到目标或达到最大深度。
形式化描述:
S = (T, frontier, budget) T 为思维树, frontier 为待展开节点队列, budget 为剩余搜索预算
δ : select(frontier) → expand(LLM) → evaluate(LLM) → prune → update(frontier)
F = {s | budget = 0 ∨ ∃ n ∈ T.leaves, score(n) ≥ threshold}
Γ = {budget 单调递减, 每轮至少剪除 |frontier|×p 的候选}
终止性: 有界终止 —— budget 单调递减。
示意图

扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 需要探索多条推理路径, 而非单线推进 |
| 2. State | S = |
| 3. 拓扑 | 树: 每个节点可 fan-out 多个候选, 搜索策略决定下一步展开哪个节点 |
| 4. Router | 代码控制搜索策略 (BFS/DFS/beam/蒙特卡洛), LLM 只做 generate_candidates + evaluate |
| 5. 失败模式 | 搜索空间爆炸; 评分不准确导致剪枝错误; 同质化候选 |
| 6. 何时升级 | 需要搜索+执行验证时 → Mental Loop |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 树 (动态展开) |
| Routing | 代码控制的搜索策略 |
| Guard | budget 约束 |
| Mode | simulate (搜索过程) |
| 核心维度 | Topology (树形)+ Routing (搜索驱动) |
核心洞察: Tree-of-Thoughts 让推理变成搜索。关键分离: 代码控制搜索策略, LLM 只生成候选和评分。这让推理从"模型内部不可见过程"变成"外部可控可调的搜索问题"。
4.13 Mental Loop / Simulator (心智模拟)
基础
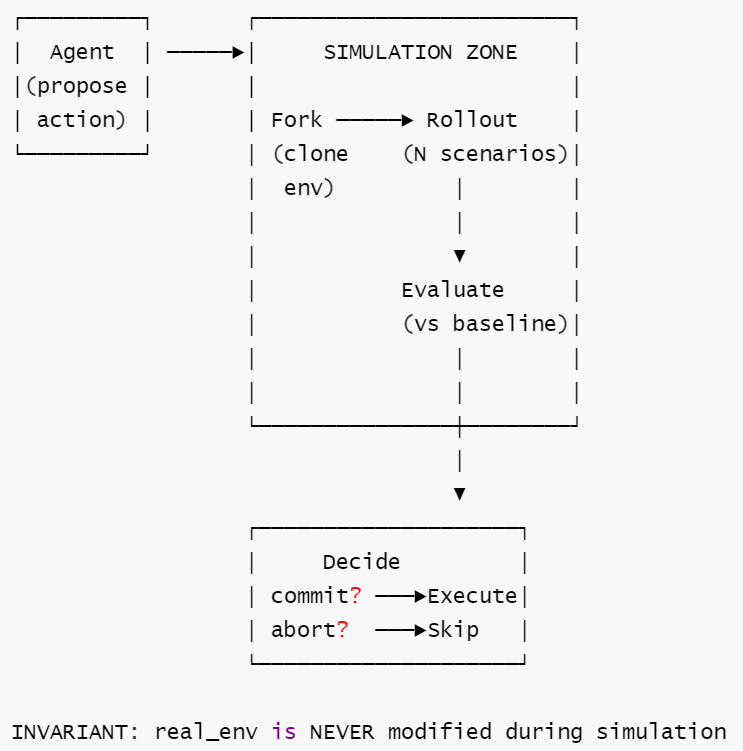
定义: 在执行真实动作前,系统 fork 一个模拟环境,推演动作后果,评估结果,仅在超过基线时才真正执行。
核心思想: 架构的上限不是 LLM, 而是模拟器的保真度。核心安全不变量:模拟绝对不能修改真实环境。
核心工作流: ① Agent 提出待执行动作 → ② Fork 当前环境创建模拟副本 → ③ 在模拟环境中推演动作后果并与基线对比评估 → ④ 评估通过则在真实环境执行,否则放弃该动作。
形式化描述:
S = (scenario, rollouts: List[Rollout], best_action)
δ : (s, ∅, ∅) → fork(s, k) → ∥ᵢ rollout(s, kᵢ) → evaluate_all → select_best → execute(real)
F = {s | real_execution_complete}
Γ = {simulate(·) 不修改 real_env (核心不变量), k ≥ 2, ∀ rollout, rollout.trajectory ∈ FeasiblePaths}
终止性: 有界终止 —— fork 数 k 固定, rollout 深度有界。
示意图
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 在执行前预演多种可能路径, 选择最优方案 |
| 2. State | S = |
| 3. 拓扑 | fork → for each branch: rollout → evaluate → select_best → execute(real) |
| 4. Router | 代码控制 fork 数量, LLM 做 rollout 生成+evaluate, 最终策略选 best |
| 5. 失败模式 | 模拟与现实偏离; rollout 数量少导致遗漏最优; 模拟成本高 |
| 6. 何时升级 | 需要真实环境但拦截副作用 → Dry-Run; 需要长期自我改进 → Self-Improvement |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | Fork → Parallel Rollouts → Merge |
| Routing | 代码控制 fork + LLM evaluate + 策略 select |
| Guard | Mode 约束: simulate 不修改 real_env |
| Mode | simulate → live (两阶段) |
| 核心维度 | Mode (simulate 与 live 切换) |
核心洞察: Mental Loop 的核心不变量是 simulate 不修改 real_env。这是"三思而后行"的工程实现——在反事实世界中犯错是免费的, 在真实世界中不是。
4.14 Dry-Run Harness (预演执行)
基础
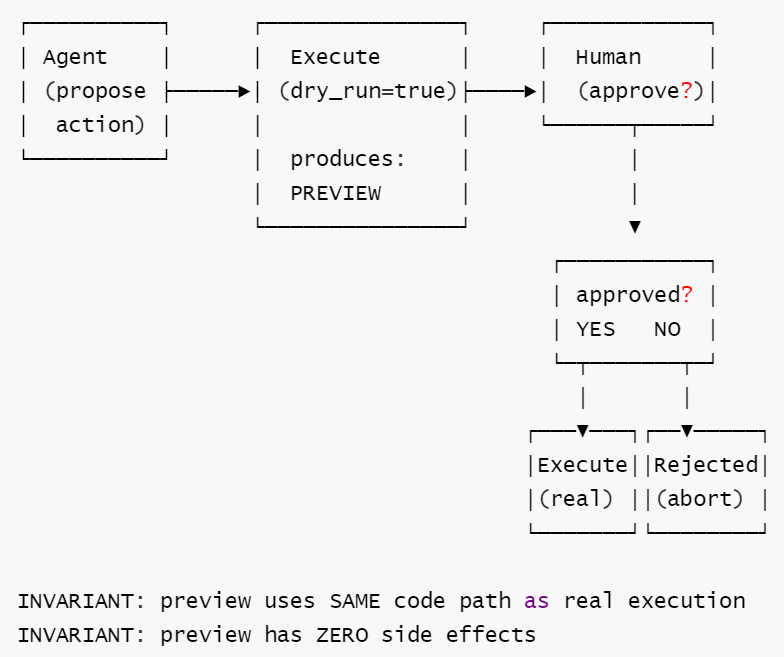
定义: 任何有副作用的动作必须先在 dry-run 模式执行(生成预览), 经人工明确批准后才进行真实执行。
核心思想: 不是让 agent 更保守,而是让 "是否允许执行" 成为一个显式的控制流决策。preview 和 execute 必须共享同一代码路径以保证保真性。
核心工作流: ① Agent 提出有副作用的动作 → ② 以 dry_run=true 模式执行生成预览(零副作用) → ③ 将预览呈现给人工审批 → ④ 批准则以 dry_run=false 真实执行,拒绝则中止。
形式化描述:
S = (a, preview(a), decision) decision ∈ {approved, rejected, modified}
δ : (a, ∅, ∅) → dry_run(a) → (a, preview, ∅) → await_human → (a, preview, d)
→ (d=approved ? execute(a) : abort) → F
F = {s | decision ≠ ∅} (无论 approve/reject, 决策即终止)
Γ = {dry_run(·) 与 execute(·) 共用同一代码路径, preview 必须完整展示副作用}
终止性: 外部终止 —— 依赖于人工决策。
示意图
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 高风险操作 (删库/付款/发邮件) 需要 human-in-the-loop 确认 |
| 2. State | S = |
| 3. 拓扑 | 线性: Action → Preview → Human Approval → Execute(real) / Reject |
| 4. Router | Human 决策: approve → execute; reject → abort/modify |
| 5. 失败模式 | preview 与实际执行不一致; 人工疲劳点"同意"; 审批延迟 |
| 6. 何时升级 | 需要 agent 自主做边界判断时 → Metacognitive |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 线性 (带外部等待) |
| Routing | 人工决策 (外部) |
| Guard | 副作用预览 (最高等级 guard) |
| Mode | dry_run → live |
| 核心维度 | Guard + Mode |
核心洞察: Dry-Run 的关键工程约束是 preview 和 execute 必须走同一代码路径。如果预览是一条路、执行是另一条路, dry-run 就自欺欺人了。
4.15 Reflexive Metacognitive (自反元认知)
基础
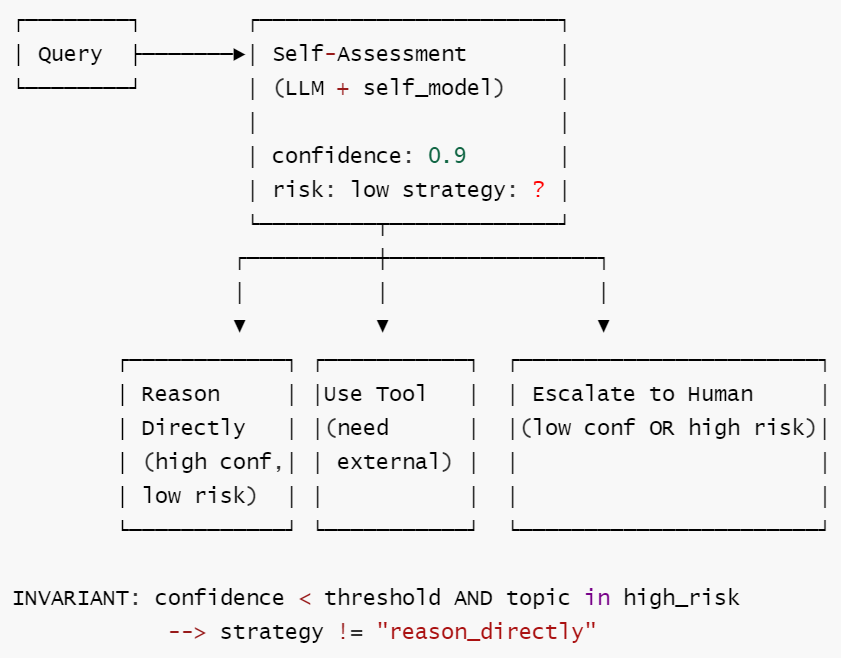
定义: 在尝试任务前,agent 基于自我模型(已知领域、工具、置信度阈值)评估自身能力,然后路由到合适策略。
核心思想: agent 最强的能力不是 "回答", 而是 "拒绝"。知道自己不知道什么,才能避免输出自信但错误的答案。
核心工作流: ① 接收任务后基于 self_model 进行自我评估(置信度 + 风险等级) → ② 根据评估结果选择策略 → ③ 高置信低风险:直接推理回答;需外部信息:调用工具;低置信或高风险:升级给人类 → ④ 输出结果或升级通知。
形式化描述:
S = S_core × SM × CF × ST (核心状态 × 自我模型 × 置信度 × 策略)
δ : (s, sm, ∅, st) → assess(s, sm) → (s, sm, cf, st)
→ (cf ≥ θ_st ? act(s, st) : escalate/refuse) → ...
F = {s | task_complete ∨ decision = "refuse"}
Γ = {cf ∈ [0,1], sm 随经验更新, escalate 优先于 hallucinate, "拒绝"是合法动作}
终止性: 结构性终止 (带拒绝分支)。
示意图
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | Agent 需要知道自己不知道什么 (self-awareness) |
| 2. State | S = S_core × |
| 3. 拓扑 | 每步执行前增加元认知检查: Assess → (confident? act : escalate/defer) |
| 4. Router | 基于 confidence 与 capability_boundary 比较: confident → 执行; 否则 → 升级/拒绝 |
| 5. 失败模式 | 过度自信 (self_model 失真); 过度谨慎 (拒绝太多); 评估本身有成本 |
| 6. 何时升级 | 需要跨任务持续改进时 → Self-Improvement |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 循环 + 元认知分支 |
| Routing | 置信度驱动的条件分支 |
| Guard | 自我边界守卫 (capability boundary) |
| Mode | live |
| 核心维度 | State (self_model) + Guard |
核心洞察: 真正高级的 agent 不是更敢做事, 而是更知道什么时候不该做。最强大的能力是 "拒绝"——在能力边界之外, silence 比 hallucination 更好。
4.16 Self-Improvement Loop (自改进循环)
基础
定义: 一个迭代精炼循环,输出经过多轮生成、批评和改进。高质量输出被存入 gold 标准库供未来参考。
核心思想: 两层进化 — 任务内迭代(生成→批评→改进)和跨任务积累(gold 库持续增长)。gold 库只接受通过 critic 的样本。
核心工作流: ① Generator 参考 gold 库中的高质量样例生成输出 → ② Critic 评估输出质量 → ③ 未通过则修订后重新提交(循环直到通过或达上限) → ④ 通过审批的输出存入 gold 库,供后续任务参考。
形式化描述:
S = (task_state, gold_set, failure_patterns)
δ : 内层: 正常执行 task → 成功: extract → gold_set ∪ {new_gold}
→ 失败: analyze → failure_patterns ∪ {new_pattern}
外层: gold_set 达到阈值 → consolidate → 更新 system_prompt / few_shot
F = 无全局终止 (持续运行系统)
Γ = {gold 添加需 verification, failure_pattern 添加需 ≥2 次复现, gold 不互相矛盾}
终止性: 有界终止 (内层) / 无全局终止 (持续系统)。
示意图
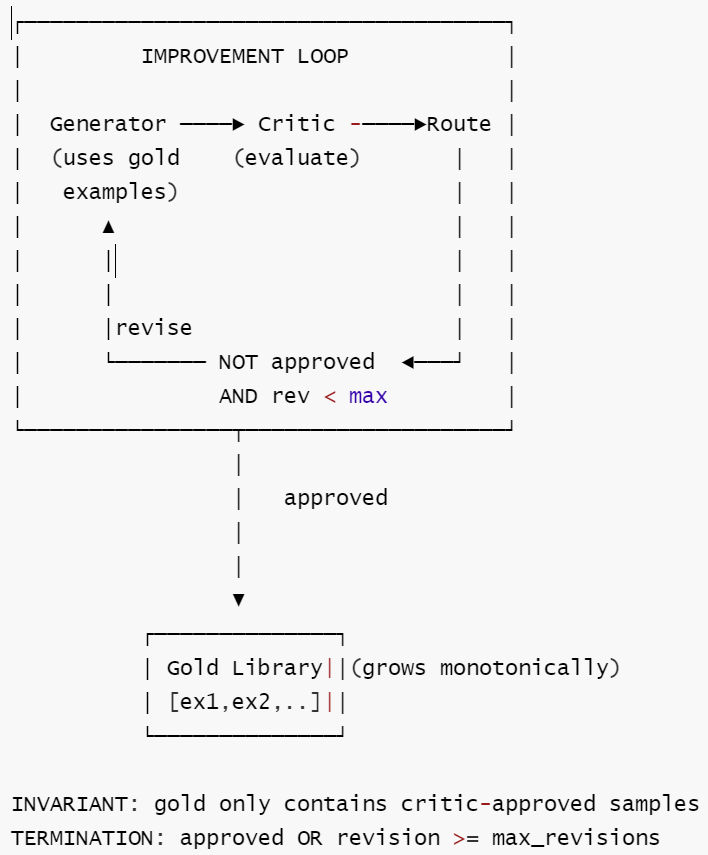
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 系统性能停滞, 需要从经验中持续改进 |
| 2. State | S = S_task × S_memory × S_gold (gold 为跨任务积累的最优解) |
| 3. 拓扑 | 两层: 内层单任务迭代, 外层跨任务 gold 积累和 prompt 优化 |
| 4. Router | 内层: 正常任务执行; 外层: 成功后提取范式 → gold, 失败后分析 → 规避规则 |
| 5. 失败模式 | gold 过拟合; 错误模式被固化; 改进方向与真实需求漂移 |
| 6. 何时升级 | (此为演化终点; 可结合其他模式升级具体环节) |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 双层嵌套循环 |
| Routing | 基于成败的条件分支 + 阈值触发的 consolidate |
| Guard | gold 加入前验证 + failure 复现确认 |
| Mode | live |
| 核心维度 | State (跨任务 gold) + Guard |
核心洞察: Self-Improvement 的进化回路有两个时间尺度: 单任务的秒级改进和跨任务的天级积累。gold_set 是系统的"经验资产", failure_patterns 是"免疫系统"。
4.17 Cellular Automata (元胞自动机)
基础
定义: 一个由 cell 组成的网格,每个 cell 是独立的 LLM 驱动 agent, 仅通过局部更新规则与邻居交互。全局行为从局部交互中涌现。
核心思想: LLM 完全退出主执行循环 — 它只负责设计局部更新规则。真正的求解通过大规模并行局部演化完成。不存在中央控制器。
核心工作流: ① 初始化网格,每个 cell 赋予初始状态 → ② 每个 cell 读取邻居状态 → ③ 根据局部更新规则计算自己的下一状态(全部 cell 同步更新) → ④ 重复②直到网格收敛或达到最大步数。
形式化描述:
S = Grid[N][M] 其中 Grid[i][j] ∈ CellStates
δ : ∀ cell(i,j): new_state = Rule(neighbors(i,j), self) (同步或异步更新)
LLM 的职责: 设计 Rule, 而非控制 cell
F = {s | global_stability(s) ∨ step ≥ max_steps}
Γ = {Rule 在更新中不变 (由 LLM 设计一次), local-only: cell 仅访问 Moore/Von Neumann 邻域}
终止性: 有界终止 —— 达到稳态或 max_steps。
示意图
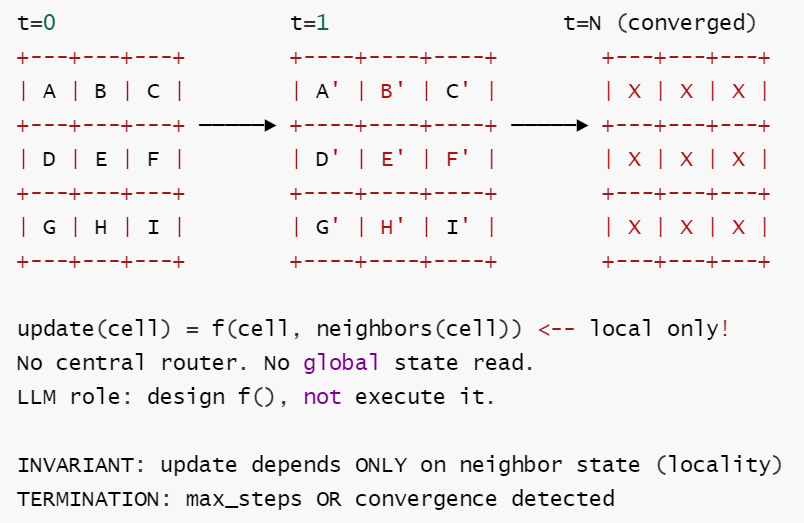
扩展
| 维度 | 分析 |
|---|---|
| 1. 要解决什么 | 探索大规模去中心化 agent 涌现行为 |
| 2. State | S = Grid[N][M] 每个 cell 有自己的状态和局部规则 |
| 3. 拓扑 | 网格 (每个 node 只与邻居通信) |
| 4. Router | 无中心 router, 每个 cell 基于局部规则自主决策 |
| 5. 失败模式 | 边界效应; 规则设计不当导致全局退化; 收敛到平庸稳态 |
| 6. 何时升级 | (实验性模式, 产业应用是开放问题) |
框架映射:
我们来看看 本模式 如何映射到其它模式上。
| 维度 | 取值 |
|---|---|
| Topology | 网格 (Moore/Von Neumann 邻域) |
| Routing | 无中心 (去中心化涌现) |
| Guard | 局部性约束 |
| Mode | simulate |
| 核心维度 | Topology (去中心化网格) |
核心洞察: Cellular Automata 是唯一一个 LLM 不参与运行时决策 的模式。LLM 只设计规则, 然后退场——智能从局部交互中涌现。这是对"LLM 必须是中控器"这一假设的最大挑战。
4.18 常见坑
| 坑 | 根因 | 解法 |
|---|---|---|
| Agent 无限循环 | 缺少 max_iterations 或 goal_condition 永远不满足 | 硬上限 + 循环检测 (重复 action 计数) |
| Tool 调用幻觉 | LLM 生成不存在的 tool_name 或参数 schema | strict mode function calling + schema 校验 |
| 上下文窗口爆炸 | 历史消息无限增长 | 滑动窗口 + 摘要压缩 + token 预算管理 |
| 验证器同源偏差 | verifier 与 executor 同模型/prompt | 独立模型或独立 prompt + 程序化验证混合 |
| Memory 污染 | 错误经验被持久化 | 写入前验证 + 来源标注 + 定期清洗 |
| Ensemble 假共识 | 模型多样性不足, 输出高度相关 | 不同模型家族 + 不同 prompt 策略 + 温度调节 |
| Plan 偏差累积 | 早期步骤小偏差, 后期步骤完全偏离 | 每步后验证 + 中间 checkpoints + 偏差阈值 |
| Dry-Run 不一致 | preview 与实际执行走不同代码路径 | 强制统一代码路径, preview 只拦截副作用 |
4.19 6 维度矩阵
| 模式 | 推理质量 | 控制流 | 安全信任 | 分解协作 | 记忆状态 | 可观测性 |
|---|---|---|---|---|---|---|
| Reflection | ★★★ | ★★ | ★★ | ★ | ★ | ★★ |
| Tool Use | ★★★ | ★★ | ★★ | ★ | ★ | ★★★ |
| ReAct | ★★★ | ★★★ | ★★ | ★ | ★★ | ★★★ |
| Planning | ★★★★ | ★★★★ | ★★ | ★★ | ★★★ | ★★★★ |
| PEV | ★★★★ | ★★★★ | ★★★★ | ★★ | ★★★ | ★★★★ |
| Multi-Agent | ★★★★ | ★★★★ | ★★★ | ★★★★★ | ★★★ | ★★★ |
| Blackboard | ★★★★ | ★★★★ | ★★★ | ★★★★★ | ★★★★★ | ★★★ |
| Meta-Controller | ★★★ | ★★★ | ★★★ | ★★★ | ★★ | ★★★★ |
| Ensemble | ★★★★★ | ★★★ | ★★★★ | ★★ | ★★ | ★★★ |
| Memory | ★★★ | ★★ | ★★ | ★ | ★★★★★ | ★★ |
| Graph Memory | ★★★★ | ★★ | ★★ | ★ | ★★★★★ | ★★★ |
| ToT | ★★★★★ | ★★★★ | ★★ | ★ | ★★★ | ★★★ |
| Mental Loop | ★★★★★ | ★★★★ | ★★★★ | ★ | ★★★ | ★★★ |
| Dry-Run | ★★★ | ★★★ | ★★★★★ | ★ | ★ | ★★★★★ |
| Metacognitive | ★★★★ | ★★★★★ | ★★★★★ | ★ | ★★★★ | ★★★★ |
| Self-Improvement | ★★★★ | ★★★ | ★★★ | ★ | ★★★★★ | ★★★ |
| Cellular Automata | ★★★ | ★★ | ★ | ★★★★ | ★★★ | ★ |
0x05 演化路径与升级触发条件
5.1 选型决策表
| 你缺的能力 | 优先架构 | 为什么 |
|---|---|---|
| 输出质量不够好 | Reflection | 最小成本的自检自修闭环 |
| 需要获取最新/外部信息 | Tool Use | ACI 突破知识截止边界 |
| 复杂多步任务 | ReAct | 感知-决策-行动标准循环, 80% 任务够用 |
| 任务步骤多且相互依赖 | Planning | plan 队列提供全局视角和可检视性 |
| 每步结果需要验证 | PEV | 验证独立于执行, 错误不静默传播 |
| 需要多个专长领域协作 | Multi-Agent | 认知分工结构化, 每个 agent 可独立优化 |
| 任务类型多变无法预设流程 | Blackboard | 共享状态 + 动态调度 specialist |
| 请求类型多样化需分流 | Meta-Controller | 一次性分类路由, 分诊台模式 |
| 关键决策需要多角度验证 | Ensemble | 冗余而非分工, 保留冲突信息 |
| 需要记住用户偏好和上下文 | Memory | State 外延到持久化存储 |
| 需要结构化关系推理 | Graph Memory | 图查询替代向量搜索 |
| 需要探索多条推理路径 | ToT | 推理变成可控搜索问题 |
| 执行前需要安全预演 | Mental Loop | 反事实模拟, simulate 不修改真实环境 |
| 高风险操作需要人工确认 | Dry-Run | 副作用预览, 同一代码路径 |
| 需要知道自己的能力边界 | Metacognitive | 自我边界建模, 该拒绝时就拒绝 |
| 需要从经验中持续进化 | Self-Improvement | 双层学习回路, gold 积累 |
5.2 组合策略
组合原则
三个核心原则判断两种模式是否可以组合:
- State 可合并: 两种模式的 State 定义不冲突, 可以求并集
- 拓扑可嵌套: 一个模式的拓扑可以作为另一个模式的子图
- 不变量不互斥: Γ₁ ∩ Γ₂ ≠ ∅, 两者的约束不互相矛盾
经典组合
组合 A: ReAct + Memory (长期交互助手)
State : S = (T×A×O)^k × M_e × M_s
拓扑 : ReAct 主循环 + Memory 读写侧枝
每轮 thought 前 retrieve 相关记忆
每轮 observation 后 store 重要信息
execute(task):
memories = memory_store.retrieve(task)
context = task + memories
while not done and steps < max_iterations:
thought, action = llm.think(context, history)
observation = execute(action)
if is_significant(observation):
memory_store.save(episode=(action, observation))
history.append((thought, action, observation))
return final_answer
组合 B: Planning + PEV + Multi-Agent (可靠多角色系统)
State : S = (plan, i, results, verifications, agent_outputs)
拓扑 : Planner → [Agent₁→Verify₁ → Agent₂→Verify₂ → ...] (流水线每步带验证)
execute(task):
plan = planner.generate(task) # Planning: plan 队列
approved = False
while not approved:
for step in plan:
agent = select_agent(step) # Multi-Agent: 角色分工
result = agent.execute(step)
verdict = verifier.check(step, result) # PEV: 独立验证
if verdict == "fail":
plan = replan(plan, step, verdict)
break # 回到 planning
results.append((step, result, verdict))
if all_verified(results):
approved = True
return results
组合 C: Meta-Controller + Ensemble + Dry-Run (高可靠生产系统)
State : S = (query, category, parallel_results, preview, decision)
拓扑 : Classify → [Fan-out→Parallel→Fan-in] → Preview → Human → Execute
execute(query):
category = classifier.classify(query) # Meta-Controller
specialist_set = route(category)
results = parallel_execute(specialist_set, query) # Ensemble
final = aggregate(results, strategy="conflict_preserving")
preview = dry_run(final.action) # Dry-Run
decision = await_human(preview)
if decision == "approved":
return execute(final.action)
else:
return abort(final.action)
组合 D: Metacognitive + ToT + Mental Loop (高风险决策系统)
State : S = (scenario, tree, rollouts, confidence, strategy)
拓扑 : Assess → [ToT 搜索] → [Mental Loop rollout] → confidence_check → decide
execute(scenario):
sm = self_model.load()
if sm.capability_boundary.exceeds(scenario):
return refuse("超出能力边界") # Metacognitive
tree = tot.search(scenario) # ToT: 搜索推理
candidates = tree.top_k(k=3)
rollouts = []
for candidate in candidates:
rollout = mental_loop.simulate(candidate) # Mental Loop
rollouts.append(rollout)
best = select(rollouts, criteria=["safety", "outcome", "cost"])
confidence = estimate_confidence(best, sm)
if confidence < sm.min_threshold:
return escalate(best, rollouts) # Metacognitive
else:
return execute(best.action)
5.3 组合反模式
| 组合 | 冲突 | 后果 |
|---|---|---|
| Ensemble + ToT (深层嵌套) | ToT 的搜索空间 × Ensemble 的冗余 = 成本爆炸 | 一次任务耗费 $10+ 且延迟不可接受 |
| Blackboard + Multi-Agent (静态流水线) | Blackboard 的动态调度 vs Multi-Agent 的固定顺序, 互相抵消 | 复杂度增加但无收益, 退化为其中之一 |
| PEV + Reflection (验证器即 generator) | PEV 的独立性要求 Γ 被打破: verifier = executor | 自评自查, 验证失去意义, 同源偏差 |
| Memory (无写入门槛) + Self-Improvement | Memory 写入错误→Self-Improvement 提取为 gold→系统性污染 | 越"改进"越差, 正反馈退化回路 |
5.4 组合决策树
需要组合多个模式? 从你的核心痛点出发:
你的系统需要持久化状态吗?
├── 是 → + Memory (Episodic/Semantic 或 Graph Memory)
└── 否 → 继续
你的系统需要安全保证吗?
├── 是 → 多高风险的?
│ ├── 普通 → + PEV
│ ├── 较高 → + Mental Loop
│ └── 极高 → + Dry-Run (human-in-loop)
└── 否 → 继续
你的系统需要多角色/多模型吗?
├── 是 → 任务类型固定还是多变?
│ ├── 固定 → + Multi-Agent
│ ├── 多变 → + Blackboard
│ └── 只需冗余 → + Ensemble
└── 否 → 继续
你的系统需要自我认知吗?
├── 是 → + Metacognitive
└── 否 → 你已经有了一个合理的基础组合
5.5 汇总表
| # | 模式 | 拓扑 | 终止性 | 关键创新 |
|---|---|---|---|---|
| 01 | Reflection | 线性 | 结构性 | Critique pass |
| 02 | Tool Use | 线性 + 分支 | 条件 | ACI 接口 |
| 03 | ReAct | 循环 | 条件 | 反馈回边 |
| 04 | Planning | 线性 + 循环 | 有界 | 显式控制流 |
| 05 | PEV | 循环 + 条件 | 有界 | 内联验证 |
| 06 | Multi-Agent | 流水线 | 结构性 | 角色分离 |
| 07 | Blackboard | 动态循环 | 条件 | 共享状态调度 |
| 08 | Meta-Controller | 分支 | 结构性 | 一次性分诊 |
| 09 | Ensemble | 分叉汇聚 | 结构性 | 冗余 |
| 10 | Episodic+Semantic | 循环 + 外部 | 条件 | 持久记忆 |
| 11 | Graph Memory | 流水线 | 结构性 | 关系查询 |
| 12 | ToT | 树 | 有界 | 搜索即推理 |
| 13 | Mental Loop | Fork + 评估 | 有界 | 反事实执行 |
| 14 | Dry-Run | 线性 + 闸门 | 外部 | 人工审批门 |
| 15 | Metacognitive | 分支 | 结构性 | 自我边界建模 |
| 16 | Self-Improvement | 循环 + 积累 | 有界 | 跨任务进化 |
| 17 | Cellular Automata | 网格 | 有界 | 去中心化涌现 |
0xEE 广告
继续给第二本书打广告。

购买链接
0xFF 参考来源
| 来源 | 贡献 |
|---|---|
| Andrew Ng (Agentic Design Patterns, 2024) | 提出 Reflection / Tool Use / Planning / Multi-Agent 四种基础模式 |
| Anthropic (Building Effective Agents, 2024) | 工程实践指导: 从最简开始, 只在必要时增加复杂度 |
| LangChain (LangGraph, 2024-2025) | 图状态机 Agent 框架, Topology + State + Routing 的工程实现 |
| Li et al. (Agent Harness Engineering: A Survey, 2026) | ETCLSVG 七层分类法, "可靠性取决于基础设施而非模型"的核心论点 |
| linkxzhou (知乎专栏: Agent 架构演进, 2025) | 中文社区对 17 种模式的系统梳理和对比分析 |
| all-agentic-architectures (GitHub, 2025) | 本项目的模式聚合与形式化分析框架 |
原文地址: https://www.cveoy.top/t/topic/qGNA 著作权归作者所有。请勿转载和采集!