13、PushbackInputStream和StreamTokenizer的源码分析和使用方法详细分析
一、PushbackInputStream源码——可以对输入Stream进行回退的装饰器类
PushbackInputStream适合语法解析过程中的语法回退,因为这个类提供了有限字节(内部定义了一个默认长度为1的byte[] buf字节数组)的缓冲式回退能力,具体过程如下:
①、当调用unread()函数时会将任意字节(可以是从被装饰的输入流中读取的字节,也可以是自己定义的字节)压入byte[] buf字节数组的头部;
②、当后续调用read()函数时优先读取这个byte[] buf字节数组中被压入的字节;
当使用PushbackInputStream进行语法解析时,需要注意 unread()函数的调用顺序、EOF 处理及嵌套回退风险等。
因为语法解析器常需要先预读一个字符判断类型,如果发现不是目标类型再退回去,而 InputStream.class 本身不支持回退,所以PushbackInputStream.class就是为此设计的。
很多语法解析需要预读多个字符才能确定 token 类型,比如识别 == 和 =、或 /* 注释起始符。PushbackInputStream默认构造函数只分配 1 字节缓冲(内部定义了一个默认长度为1的byte[] buf字节数组),根本不够用,因此需要使用
new PushbackInputStream(in, 4)
构造一个长度为4的byte[] buf字节数组作为缓冲区用来覆盖大多数双字符操作符和简单分隔符场景,如果要支持 Unicode 转义(如 \u0061)或长标识符前缀判断,缓冲区需更大,但别盲目设成 1024,同时缓冲区byte[] buf字节数组的长度在构造后不可变,运行时并无法扩容。比如下面是一个识别数字字面量(含小数点)时的安全回退示例,伪代码如下所示:
...省略部分代码...
int ch = in.read();
if (ch == '.') {
int next = in.read();
if (Character.isDigit(next)) {
// 确认是小数,继续解析
parseFractionPart();
} else {
// 不是小数,退回两个字符:'.' 和 next
in.unread(next);
in.unread('.');
}
} else {
// 其他情况按原逻辑处理
}
...省略部分代码...
1.1、PushbackInputStream的源码分析
PushbackInputStream.class 的UML关系图,如下所示:
PushbackInputStream.class的源码,如下所示:
package java.io;
public class PushbackInputStream extends FilterInputStream {
//有限长度的用于回退的字节数组缓冲区,默认长度为1
protected byte[] buf;
//可读指针,byte[] buf(有限长度的用于回退的字节数组缓冲区)中该指针(包括该指针)索引之后的所有字节都可以读
protected int pos;
//检查被装饰的输入流是否关闭
private void ensureOpen() throws IOException {
if (in == null)
throw new IOException("Stream closed");
}
//构造函数,in为被装饰的输入流,size为byte[] buf(有限长度的用于回退的字节数组缓冲区)的长度
public PushbackInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("size <= 0");
}
this.buf = new byte[size];
this.pos = size;//将可读指针指向byte[] buf(有限长度的用于回退的字节数组缓冲区)中最后一个索引(size-1)之后
}
//构造函数,in为被装饰的输入流
public PushbackInputStream(InputStream in) {
this(in, 1);//构造一个默认长度为1的byte[] buf(用于回退的字节数组缓冲区)
}
//如果byte[] buf(用于回退的字节数组缓冲区)中有可读的字节的话,就从该缓冲区中读取1个字节
//如果byte[] buf(用于回退的字节数组缓冲区)中没有可读的字节的话,就从被装饰的输入流中读取1个字节
//如果byte[] buf(用于回退的字节数组缓冲区)和被装饰的输入流中都没有可读的字节的话,返回-1
public int read() throws IOException {
ensureOpen();
if (pos < buf.length) {
return buf[pos++] & 0xff;
}
return super.read();
}
//尽可能的从byte[] buf(用于回退的字节数组缓冲区)和被装饰的输入流中读取len个字节到byte[] b的[off,off+len)索引位置,总共分为以下5种场景:
//①、如果byte[] buf(用于回退的字节数组缓冲区)中有len个字节的话,就从该缓冲区中读取len个字节到字节数组byte[] b的[off,off+len)索引位置
//②、如果byte[] buf(用于回退的字节数组缓冲区)中没有任何字节并且被装饰的输入流中有len个字节,那就从被装饰的输入流中读取len个字节到字节数组byte[] b的[off,off+len)索引位置
//③、如果byte[] buf(用于回退的字节数组缓冲区)中没有任何字节并且被装饰的输入流中只有avail(avail b.length - off) {//相当于off + len > b.length(源码中这样写代码的好处我没看出来)
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;//要从PushbackInputStream 对象中读取的len个字节==0时,返回0
}
int avail = buf.length - pos;//用于回退的字节数组缓冲区中实际装载了buf.length - pos个字节
if (avail > 0) {
if (len < avail) {
avail = len;
}
System.arraycopy(buf, pos, b, off, avail);
pos += avail;
off += avail;
len -= avail;
}
if (len > 0) {
len = super.read(b, off, len);
if (len == -1) {
return avail == 0 ? -1 : avail;
}
return avail + len;//场景④中的x就是这里的avail + len
}
return avail;
}
//一次只可以回推1个字节数据到byte[] buf(用于回退的字节数组缓冲区)中
public void unread(int b) throws IOException {
ensureOpen();
if (pos == 0) {//pos=0时,表示byte[] buf(用于回退的字节数组缓冲区)中已经没有足够的容量再放置数据,所以抛出一个IOException异常。
throw new IOException("Push back buffer is full");
}
buf[--pos] = (byte)b;
}
//一次回推byte[] b字节数组中[off,off+len)索引位置的len个字节数据到byte[] buf(用于回退的字节数组缓冲区)中
public void unread(byte[] b, int off, int len) throws IOException {
ensureOpen();
if (len > pos) {//如果byte[] buf(用于回退的字节数组缓冲区)中没有足够的位置放置len个字节,则抛出一个IOException
throw new IOException("Push back buffer is full");
}
pos -= len;//如果byte[] buf(用于回退的字节数组缓冲区)中有足够的位置放置len个字节,则使用System.arraycopy()函数进行回退
System.arraycopy(b, off, buf, pos, len);
}
public void unread(byte[] b) throws IOException {
unread(b, 0, b.length);
}
//返回byte[] buf(用于回退的字节数组缓冲区)+被装饰的输入流中可以被使用的字节总数量
public int available() throws IOException {
ensureOpen();
int n = buf.length - pos;//先计算用于byte[] buf(用于回退的字节数组缓冲区)中可以被使用的字节总数量
int avail = super.available();//再计算被装饰的输入流中可以被使用的字节总数量
return n > (Integer.MAX_VALUE - avail)
? Integer.MAX_VALUE
: n + avail;//byte[] buf(用于回退的字节数组缓冲区)中可以被使用的字节总数量+被装饰的输入流中可以被使用的字节总数量
}
//从byte[] buf(用于回退的字节数组缓冲区)+被装饰的输入流中跳过n个字节,如果byte[] buf(用于回退的字节数组缓冲区)+被装饰的输入流中的字节数量 0) {
if (n < pskip) {
pskip = n;
}
pos += pskip;
n -= pskip;
}
if (n > 0) {
pskip += super.skip(n);//从被装饰的输入流中跳过的字节累加到从byte[] buf(用于回退的字节数组缓冲区)中跳过的字节
}
return pskip;
}
public boolean markSupported() {
return false;
}
public synchronized void mark(int readlimit) {
}
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
//关闭被装饰的输入流和用于回退的字节数组缓冲区
public synchronized void close() throws IOException {
if (in == null)
return;
in.close();
in = null;
buf = null;
}
}
1.2、PushbackInputStream的read()函数和unread()函数
package java.io;
public class PushbackInputStream extends FilterInputStream {
//有限长度的用于回退的字节数组缓冲区,默认长度为1
protected byte[] buf;
//可读指针,byte[] buf(有限长度的用于回退的字节数组缓冲区)中该指针(包括该指针)索引之后的所有字节都可以读
protected int pos;
...省略部分代码...
//尽可能的从byte[] buf(用于回退的字节数组缓冲区)和被装饰的输入流中读取len个字节到byte[] b的[off,off+len)索引位置,总共分为以下5种场景:
//①、如果byte[] buf(用于回退的字节数组缓冲区)中有len个字节的话,就从该缓冲区中读取len个字节到字节数组byte[] b的[off,off+len)索引位置
//②、如果byte[] buf(用于回退的字节数组缓冲区)中没有任何字节并且被装饰的输入流中有len个字节,那就从被装饰的输入流中读取len个字节到字节数组byte[] b的[off,off+len)索引位置
//③、如果byte[] buf(用于回退的字节数组缓冲区)中没有任何字节并且被装饰的输入流中只有avail(avail b.length - off) {//相当于off + len > b.length(源码中这样写代码的好处我没看出来)
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;//要从PushbackInputStream 对象中读取的len个字节==0时,返回0
}
int avail = buf.length - pos;//用于回退的字节数组缓冲区中实际装载了buf.length - pos个字节
if (avail > 0) {
if (len < avail) {
avail = len;
}
System.arraycopy(buf, pos, b, off, avail);
pos += avail;
off += avail;
len -= avail;
}
if (len > 0) {
len = super.read(b, off, len);
if (len == -1) {
return avail == 0 ? -1 : avail;
}
return avail + len;//场景④中的x就是这里的avail + len
}
return avail;
}
//一次回推byte[] b字节数组中[off,off+len)索引位置的len个字节数据到byte[] buf(用于回退的字节数组缓冲区)中
public void unread(byte[] b, int off, int len) throws IOException {
ensureOpen();
if (len > pos) {//如果byte[] buf(用于回退的字节数组缓冲区)中没有足够的位置放置len个字节,则抛出一个IOException
throw new IOException("Push back buffer is full");
}
pos -= len;//如果byte[] buf(用于回退的字节数组缓冲区)中有足够的位置放置len个字节,则使用System.arraycopy()函数进行回退
System.arraycopy(b, off, buf, pos, len);
}
...省略部分代码...
}
如果使用者使用的被装饰的输入流是 ByteArrayInputStream,然后执行PushbackInputStream的read()函数和unread()函数时,如下代码:
package com.chelong.bio;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.PushbackInputStream;
public class PushbackInputStreamTest {
public static void main(String[] args) throws IOException {
String str = "Hello,World";
InputStream inputStream = new ByteArrayInputStream(str.getBytes("UTF-8"));
//构建回退流
PushbackInputStream pushbackInputStream = new PushbackInputStream(inputStream, 8);
int len = -1;
System.out.println("输出内容:");
while ((len = pushbackInputStream.read()) != -1) {
//转为char类型
char c = (char) len;
if (c == ',') {
//为 ,号时 ,先往前读3个,再往后倒两个
byte[] b1 = new byte[3];
pushbackInputStream.read(b1);
//往后倒两个
pushbackInputStream.unread(b1, 0, 2);
} else {
System.out.print(c);
}
}
}
}
上面代码的执行结果如下:
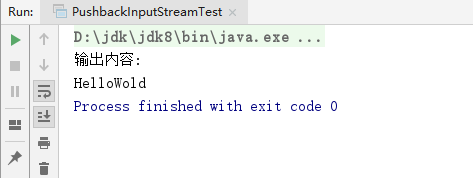
上面代码的整个执行过程分为以下5步:
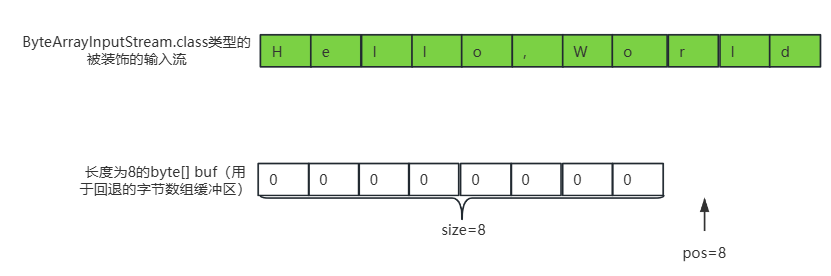
①、通过构造函数构建一个长度为8的byte[] buf(用于回退的字节数组缓冲区)和ByteArrayInputStream.class类型的被装饰的输入流,如下所示:
PushbackInputStream pushbackInputStream = new PushbackInputStream(inputStream, 8);
②、按照顺序从ByteArrayInputStream.class类型的输入流中读取字节,直到读取到','时,如下所示:
while ((len = pushbackInputStream.read()) != -1) {
//转为char类型
char c = (char) len;
if (c == ',') {
} else {
System.out.print(c);
}
}
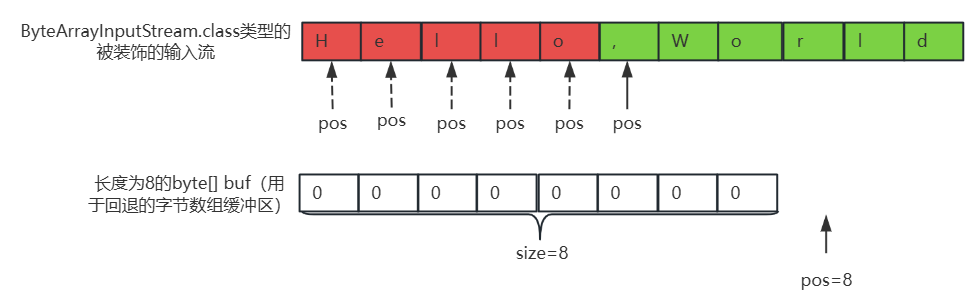
输出如下:
Hello
③、当读取到','之后,从被装饰的输入流ByteArrayInputStream.class中往byte[] b1字节数组中读取3个字节,如下所示:
//为 ,号时 ,先往前读3个,再往后倒两个
byte[] b1 = new byte[3];
pushbackInputStream.read(b1);
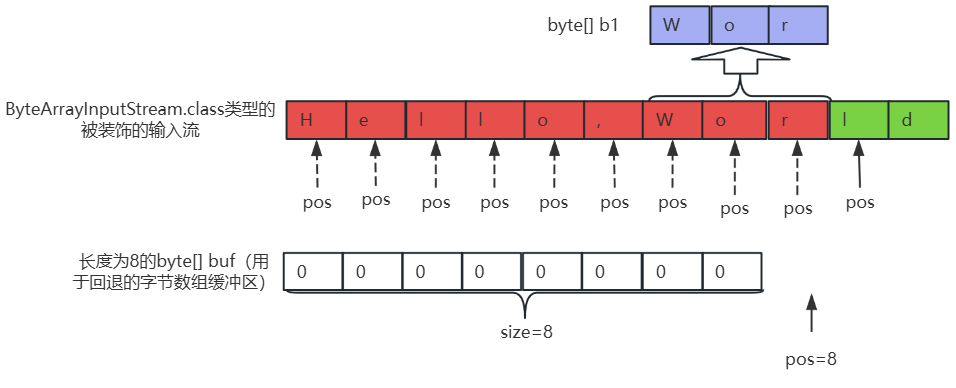
④、将步骤③中读入到byte[] b1字节数组中的[0,2)索引位置的数据读取到PushbackInputStream中的byte[] buf(用于回退的字节数组缓冲区)的[6,8)索引位置中,如下所示:
//往后倒两个
pushbackInputStream.unread(b1, 0, 2);
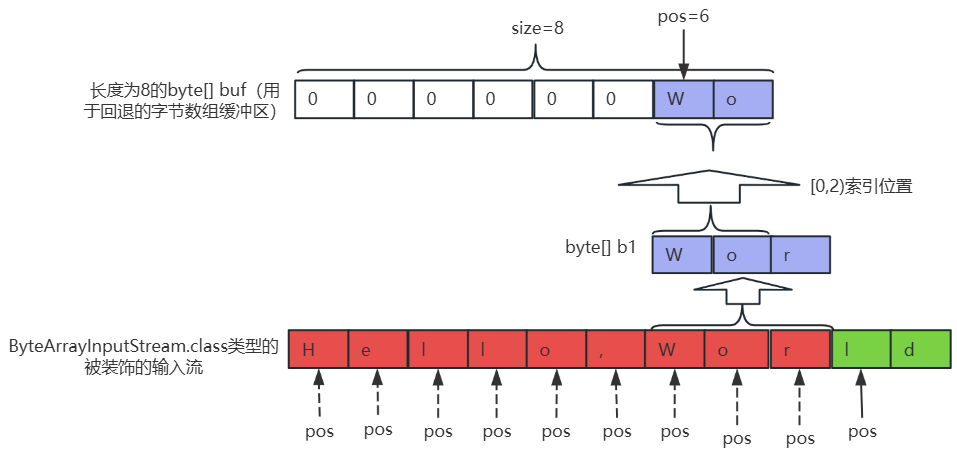
⑤、再次重复执行步骤②中按照顺序从ByteArrayInputStream.class类型的输入流中读取字节时,先读取PushbackInputStream中的byte[] buf(用于回退的字节数组缓冲区)的[6,8)索引位置,再从ByteArrayInputStream.class类型的输入流中读取剩余字节,如下所示:
while ((len = pushbackInputStream.read()) != -1) {
//转为char类型
char c = (char) len;
if (c == ',') {
} else {
System.out.print(c);
}
}
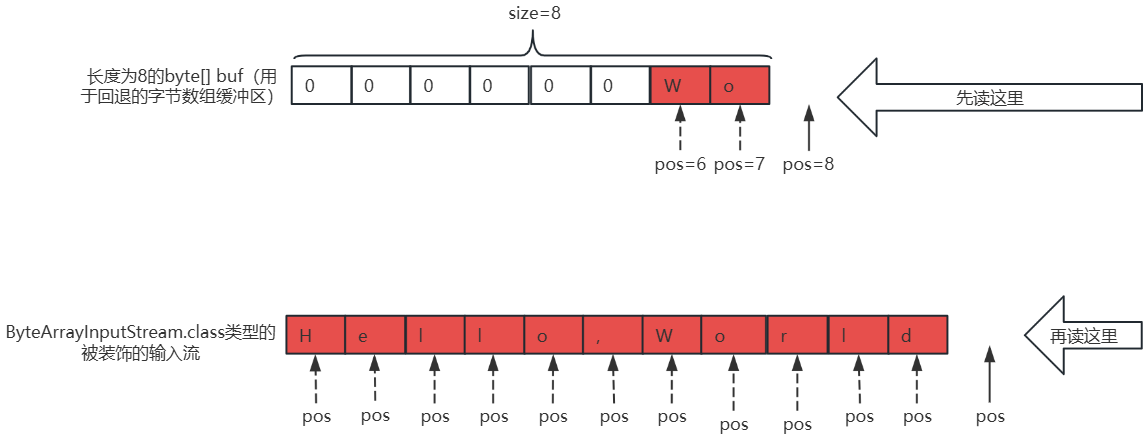
Wold
二、StreamTokenizer源码
尽管StreamTokenizer并不是继承了InputStream.class或OutputStream.class,但它的构造函数只能传入InputStream.class或者Reader.class类型的变量,所以十分恰当地包括在库的IO部分中。StreamTokenizer类用于将任何InputStream分割为一系列的“Token”(记号)。这些“Token”(记号)实际是一些断续的文本块,中间可以用使用者选择的任何东西分隔。
StreamTokenizer.class 的UML关系图,如下所示:
StreamTokenizer.class的源码,如下所示:
package java.io;
import java.util.Arrays;
public class StreamTokenizer {
//内部声明了一个Reader对象句柄和一个InputStream对象句柄,用于接收读取流。
private Reader reader = null;
private InputStream input = null;
//声明了一个char类型的数组,初始容量为20,用于存储读取时标记的内容,读取时,可以根据实际需要自动扩容。
private char buf[] = new char[20];
//声明了一个int型变量peekc,当调用nextToken方法的时候,peekc作为一个状态,用于判断是否需要继续读取下一个字符放入到标记中,初始化时赋值为NEED_CHAR。
private int peekc = NEED_CHAR;
//定义了两个常量,NEED_CHAR和SKIP_LF都表示要读取下一个字符,但后者如果遇到一个'\n',则会将它丢弃然后读取下一个字符。
private static final int NEED_CHAR = Integer.MAX_VALUE;
private static final int SKIP_LF = Integer.MAX_VALUE - 1;
//声明了一个boolean型变量pushedBack,该变量用于控制执行nextToken方法时,是否需要进行回退。
private boolean pushedBack;
//声明了一个boolean型变量forceLower,该变量用于控制sval是否需要进行小写处理。
private boolean forceLower;
//声明了一个int型变量,用于记录最后一次读取标记时的行数。
private int LINENO = 1;
private boolean eolIsSignificantP = false;
private boolean slashSlashCommentsP = false;
private boolean slashStarCommentsP = false;
//声明了一个数组作为一个语法表,存放几种类型,依次为空格,数字,字母,引号,注解等类型。
private byte ctype[] = new byte[256];
private static final byte CT_WHITESPACE = 1;
private static final byte CT_DIGIT = 2;
private static final byte CT_ALPHA = 4;
private static final byte CT_QUOTE = 8;
private static final byte CT_COMMENT = 16;
//声明了一个int型变量,表明当前标记的标记类型,初始化时为TT_NOTHING类型。
public int ttype = TT_NOTHING;
//定义了一个常量,表示此时已经读取到了流的末尾。
public static final int TT_EOF = -1;
//定义了一个常量,表示此时已经读到了一行的末尾。
public static final int TT_EOL = '\n';
//定义了一个常量,表示此时读到的标记是一个数字标记。
public static final int TT_NUMBER = -2;
//定义了一个常量,表示此时读到的标记是一个文本标记。
public static final int TT_WORD = -3;
//定义了一个常量,表示此时并没有进行标记的读取,用于初始化ttype。
private static final int TT_NOTHING = -4;
//声明了一个字符串型变量sval,如果当前的标记为字符串,那么此时将当前标记的值赋值给sval。
public String sval;
//声明了一个double型变量nval,如果当前的标记为数值,那么此时将当前标记的值赋值给nval。
public double nval;
/**
* 一个私有的构造函数,用于初始化内置的语法表,即ctype数组。
*/
private StreamTokenizer() {
wordChars('a', 'z');
wordChars('A', 'Z');
wordChars(128 + 32, 255);
whitespaceChars(0, ' ');
commentChar('/');
quoteChar('"');
quoteChar('\'');
parseNumbers();
}
/**
* 已废弃
* 一个带一个参数的构造函数,传入的参数为一个InputStream对象,先对其进行安全检测,如果不为null,则赋值给最初声明的InputStream对象句柄,input。值得注
* 意的是该方法如今已经被弃用了。
*/
@Deprecated
public StreamTokenizer(InputStream is) {
this();
if (is == null) {
throw new NullPointerException();
}
input = is;
}
/**
*一个带一个参数的构造函数,传入的参数为一个Reader对象,先对其进行安全检测,如果不为null,则赋值给最初声明的Reader对象句柄,reader。
*/
public StreamTokenizer(Reader r) {
this();
if (r == null) {
throw new NullPointerException();
}
reader = r;
}
/**
* 该方法用于重置标记的语法表,通过一个循环,将语法表中的每一个元素都置为0,即当做普通字符进行处理。
*/
public void resetSyntax() {
for (int i = ctype.length; --i >= 0;)
ctype[i] = 0;
}
/**
* 用于初始化语法表,传入的两个参数,为语法表的前后区间,将传入区间内的数据
*/
public void wordChars(int low, int hi) {
if (low < 0)
low = 0;
if (hi >= ctype.length)
hi = ctype.length - 1;
while (low <= hi)
ctype[low++] |= CT_ALPHA;
}
/**
* 用于初始化语法表,传入的两个参数,为语法表的前后区间,将传入区间内的数据都做为空白空格处理。
*/
public void whitespaceChars(int low, int hi) {
if (low < 0)
low = 0;
if (hi >= ctype.length)
hi = ctype.length - 1;
while (low <= hi)
ctype[low++] = CT_WHITESPACE;
}
/**
* 用于初始化语法表,传入的两个参数,为语法表的前后区间,将传入区间内的数据都做为普通字符处理。
*/
public void ordinaryChars(int low, int hi) {
if (low < 0)
low = 0;
if (hi >= ctype.length)
hi = ctype.length - 1;
while (low <= hi)
ctype[low++] = 0;
}
/**
* 用于初始化语法表,通过传入的参数作为语法表的索引,将对应的类型改为0,这样便会当做普通字符处理。
*/
public void ordinaryChar(int ch) {
if (ch >= 0 && ch < ctype.length)
ctype[ch] = 0;
}
/**
* 用于初始化语法表,以传入的int型值为索引,将其对应的数组划分到CT_COMMENT注解类型。
*/
public void commentChar(int ch) {
if (ch >= 0 && ch < ctype.length)
ctype[ch] = CT_COMMENT;
}
/**
* 用于初始化语法表,以传入的int型值为索引,将其对应的数组划分到CT_QUOTE引用类型。
*/
public void quoteChar(int ch) {
if (ch >= 0 && ch < ctype.length)
ctype[ch] = CT_QUOTE;
}
/**
* 用于初始化语法表,将数字0-9,'.','-'划分到CT_DIGIT数字类型。
*/
public void parseNumbers() {
for (int i = '0'; i <= '9'; i++)
ctype[i] |= CT_DIGIT;
ctype['.'] |= CT_DIGIT;
ctype['-'] |= CT_DIGIT;
}
/**
* 该方法用于设置eolIsSignificant变量的值,该值用来恒定是否将行的结尾当做一个标记来处理。
*/
public void eolIsSignificant(boolean flag) {
eolIsSignificantP = flag;
}
/**
* 该方法用于设置slashStarCommnetsP的值,该值用于恒定是否将c语言形式的注释当做特殊字符处理,如果为true,则所有包含在注释内的内容会被丢弃。为false,则
* 当做普通字符处理。
*/
public void slashStarComments(boolean flag) {
slashStarCommentsP = flag;
}
/**
* 该方法与上一个方法类似,不过是用来恒定是否认可c++形式的注释。
*/
public void slashSlashComments(boolean flag) {
slashSlashCommentsP = flag;
}
/**
* 该方法用于修改forceLower变量的值。
*/
public void lowerCaseMode(boolean fl) {
forceLower = fl;
}
/**
* 定义了一个read函数,实际上是通过调用内置的reader/input 的read函数,从中看出,优先是使用reader来进去读取的。
*/
private int read() throws IOException {
if (reader != null)
return reader.read();
else if (input != null)
return input.read();
else
throw new IllegalStateException();
}
/**
* 该函数用于获取下一个标记。
*/
public int nextToken() throws IOException {
//判断是否需要进行回退,如果pushedBack值为true,则直接返回上一个标记的类型,同时将pushedBack的值重置为false。
if (pushedBack) {
pushedBack = false;
return ttype;
}
byte ct[] = ctype;
sval = null;
int c = peekc;
if (c < 0)
c = NEED_CHAR;
if (c == SKIP_LF) {
c = read();
if (c < 0)
return ttype = TT_EOF;
if (c == '\n')
c = NEED_CHAR;
}
if (c == NEED_CHAR) {
c = read();
if (c < 0)
return ttype = TT_EOF;
}
ttype = c; /* Just to be safe */
peekc = NEED_CHAR;//将peekc重置,方便下一次进入方法时使用
//如果当前类型是空格,进行的操作
int ctype = c < 256 ? ct[c] : CT_ALPHA;
while ((ctype & CT_WHITESPACE) != 0) {
if (c == '\r') {
LINENO++;
if (eolIsSignificantP) {
peekc = SKIP_LF;
return ttype = TT_EOL;
}
c = read();
if (c == '\n')
c = read();
} else {
if (c == '\n') {
LINENO++;
if (eolIsSignificantP) {
return ttype = TT_EOL;
}
}
c = read();
}
if (c < 0)
return ttype = TT_EOF;
ctype = c < 256 ? ct[c] : CT_ALPHA;
}
//如果当前类型为数字的操作
if ((ctype & CT_DIGIT) != 0) {
boolean neg = false;
if (c == '-') {
c = read();
if (c != '.' && (c < '0' || c > '9')) {
peekc = c;
return ttype = '-';
}
neg = true;
}
double v = 0;
int decexp = 0;
int seendot = 0;
while (true) {
if (c == '.' && seendot == 0)
seendot = 1;
else if ('0' <= c && c <= '9') {
v = v * 10 + (c - '0');
decexp += seendot;
} else
break;
c = read();
}
peekc = c;
if (decexp != 0) {
double denom = 10;
decexp--;
while (decexp > 0) {
denom *= 10;
decexp--;
}
/* Do one division of a likely-to-be-more-accurate number */
v = v / denom;
}
nval = neg ? -v : v;
return ttype = TT_NUMBER;
}
//如果当前类型为字母符号的操作
if ((ctype & CT_ALPHA) != 0) {
int i = 0;
do {
if (i >= buf.length) {
buf = Arrays.copyOf(buf, buf.length * 2);//自动扩容
}
buf[i++] = (char) c;
c = read();
ctype = c < 0 ? CT_WHITESPACE : c < 256 ? ct[c] : CT_ALPHA;
} while ((ctype & (CT_ALPHA | CT_DIGIT)) != 0);
peekc = c;
sval = String.copyValueOf(buf, 0, i);
if (forceLower)
sval = sval.toLowerCase();
return ttype = TT_WORD;
}
//如果当前类型为引用符号的操作
if ((ctype & CT_QUOTE) != 0) {
ttype = c;
int i = 0;
/* Invariants (because \Octal needs a lookahead):
* (i) c contains char value
* (ii) d contains the lookahead
*/
int d = read();
while (d >= 0 && d != ttype && d != '\n' && d != '\r') {
if (d == '\\') {
c = read();
int first = c; /* To allow \377, but not \477 */
if (c >= '0' && c <= '7') {
c = c - '0';
int c2 = read();
if ('0' <= c2 && c2 <= '7') {
c = (c << 3) + (c2 - '0');
c2 = read();
if ('0' <= c2 && c2 <= '7' && first <= '3') {
c = (c << 3) + (c2 - '0');
d = read();
} else
d = c2;
} else
d = c2;
} else {
c = switch (c) {
case 'a' -> 0x7;
case 'b' -> '\b';
case 'f' -> 0xC;
case 'n' -> '\n';
case 'r' -> '\r';
case 't' -> '\t';
case 'v' -> 0xB;
default -> c;
};
d = read();
}
} else {
c = d;
d = read();
}
if (i >= buf.length) {
buf = Arrays.copyOf(buf, buf.length * 2);
}
buf[i++] = (char)c;
}
peekc = (d == ttype) ? NEED_CHAR : d;
sval = String.copyValueOf(buf, 0, i);
return ttype;
}
//对待注解形式的处理。
if (c == '/' && (slashSlashCommentsP || slashStarCommentsP)) {
c = read();
if (c == '*' && slashStarCommentsP) {
int prevc = 0;
while ((c = read()) != '/' || prevc != '*') {
if (c == '\r') {
LINENO++;
c = read();
if (c == '\n') {
c = read();
}
} else {
if (c == '\n') {
LINENO++;
c = read();
}
}
if (c < 0)
return ttype = TT_EOF;
prevc = c;
}
return nextToken();
} else if (c == '/' && slashSlashCommentsP) {
while ((c = read()) != '\n' && c != '\r' && c >= 0);
peekc = c;
return nextToken();
} else {
/* Now see if it is still a single line comment */
if ((ct['/'] & CT_COMMENT) != 0) {
while ((c = read()) != '\n' && c != '\r' && c >= 0);
peekc = c;
return nextToken();
} else {
peekc = c;
return ttype = '/';
}
}
}
//对于当前类型是注解时的操作。
if ((ctype & CT_COMMENT) != 0) {
while ((c = read()) != '\n' && c != '\r' && c >= 0);
peekc = c;
return nextToken();
}
return ttype = c;
}
/**
* 调用该函数时,首先进行安全检测,如果ttype不为TT_NOTHING,即已经调用过nextToken函数,那么将pushedBack的值设为true,下一次执行nextToeken函数时,
* 便不会修改当前标记的类型,同时也不会去修改当前nval或者sval的值。
*/
public void pushBack() {
if (ttype != TT_NOTHING) /* No-op if nextToken() not called */
pushedBack = true;
}
/**
* 该函数返回LINENO的值,即分割标记后最后的行数,值得注意的是如果将换行符设置为普通字符的话,会影响该函数的准确性。
*/
public int lineno() {
return LINENO;
}
/**
* 该函数可以得到一个字符串,字符串内容为当前标记的类型,以及标记所在的行数。
*/
public String toString() {
String ret = switch (ttype) {
case TT_EOF -> "EOF";
case TT_EOL -> "EOL";
case TT_WORD -> sval;
case TT_NUMBER -> "n=" + nval;
case TT_NOTHING -> "NOTHING";
default -> {
if (ttype < 256 && ((ctype[ttype] & CT_QUOTE) != 0)) {
yield sval;
}
char s[] = new char[3];
s[0] = s[2] = '\'';
s[1] = (char) ttype;
yield new String(s);
}
};
return "Token[" + ret + "], line " + LINENO;
}
}
2.1、StreamTokenize的2种使用方法
2.1.1、解析空格、"(英文单引号)、/(反斜杠)
我的windows操作系统的D盘下有一个StreamTokenizer.txt文件,该文件的内容如下所示:
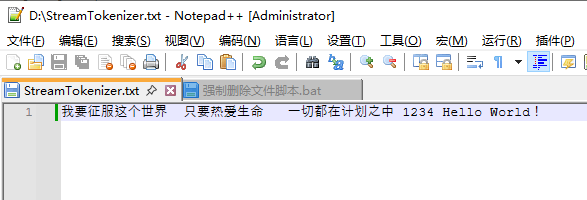
可以使用FileReader读取这个文件,然后使用StreamTokenizer来读取该文件中的每一个token以及该token对应的行号
import java.io.*;
public class StreamTokenizerTest {
public static void main(String[] args) throws UnsupportedEncodingException,
FileNotFoundException {
//通过传入一个FileReader来构建一个StreamTokenizer。这里读取的是本地的一个txt文件。
StreamTokenizer stk = new StreamTokenizer(new FileReader(new File(
"D:\\StreamTokenizer.txt")));
try {
//当没有读取到文件结尾时,不停调用nextToken方法,然后将每一个token及其行号打印出来。
while (stk.nextToken() != StreamTokenizer.TT_EOF) {
String s = null;
switch (stk.ttype) {
case StreamTokenizer.TT_WORD:
s = stk.sval;
break;
case StreamTokenizer.TT_NUMBER:
s = String.valueOf(stk.nval);
break;
default:
s = stk.sval;
}
System.out.println(stk.toString());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
上述代码的执行结果如下所示:
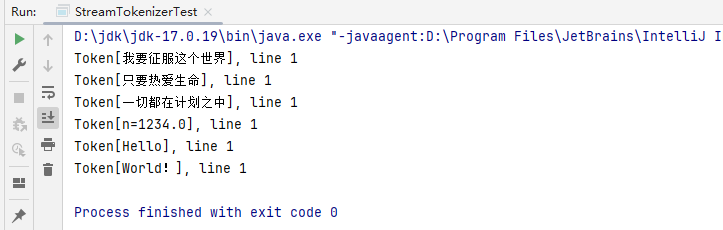
从结果中可以看出,通过nextToken()函数读取的数字型数据都是double类型的,如果不符合要求,需自行进行转换。StreamTokenizer会把双引号""中的内容作为一个Token处理,将//之后的内容作为注释(注释不会作为token进行读取),比如,修改上文中D盘下的StreamTokenizer.txt文件,如下所示:
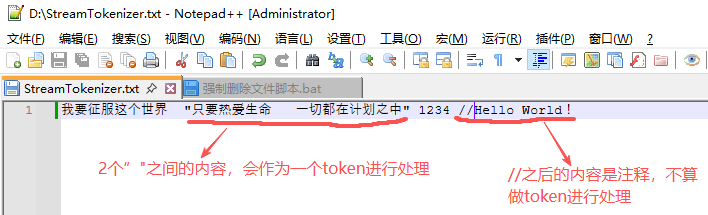
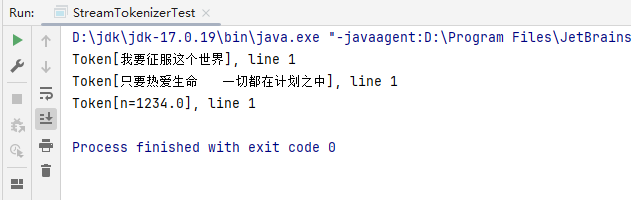
再次执行上文中的StreamTokenizerTest.class,结果如下所示:
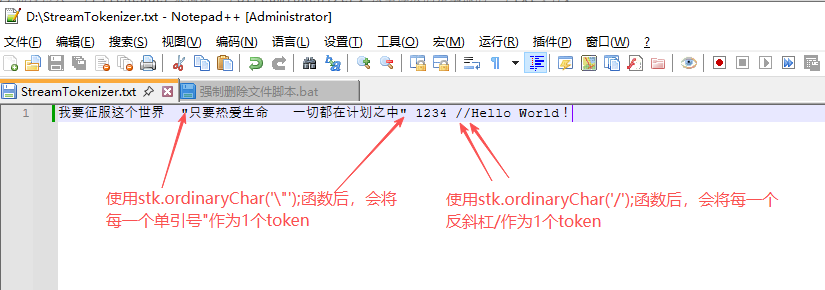
如果想让这些符号被当做普通符号来进行处理,只需调用StreamTokenize.class::ordinaryChar()函数即可将特殊的字符也当做普通字符处理,比如修改上文中的StreamTokenizerTest.class,修改后如下所示:
import java.io.*;
public class StreamTokenizerTest {
public static void main(String[] args) throws UnsupportedEncodingException,
FileNotFoundException {
//通过传入一个FileReader来构建一个StreamTokenizer。这里读取的是本地的一个txt文件。
StreamTokenizer stk = new StreamTokenizer(new FileReader(new File(
"D:\\StreamTokenizer.txt")));
stk.ordinaryChar('\"');\\ \表示转义
stk.ordinaryChar('/');\\ /不用进行转义
try {
//当没有读取到文件结尾时,不停调用nextToken方法,然后将每一个token及其行号打印出来。
while (stk.nextToken() != StreamTokenizer.TT_EOF) {
String s = null;
switch (stk.ttype) {
case StreamTokenizer.TT_WORD:
s = stk.sval;
break;
case StreamTokenizer.TT_NUMBER:
s = String.valueOf(stk.nval);
break;
default:
s = stk.sval;
}
System.out.println(stk.toString());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
继续读取D盘下的StreamTokenizer.txt文件,该文件的内容如下所示:
上述代码的执行结果如下所示:

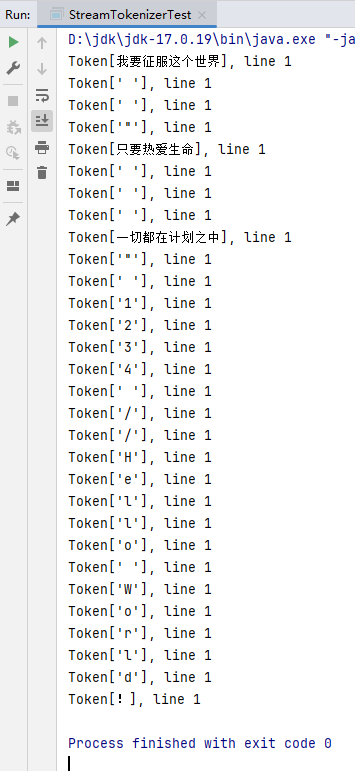
也可以使用StreamTokenize.class::resetSyntax()函数将每一个ASCII码表示的字符和中文字符串作为1个token进行处理,比如修改上文中的StreamTokenizerTest.class,修改后如下所示:
import java.io.*;
public class StreamTokenizerTest {
public static void main(String[] args) throws UnsupportedEncodingException,
FileNotFoundException {
//通过传入一个FileReader来构建一个StreamTokenizer。这里读取的是本地的一个txt文件。
StreamTokenizer stk = new StreamTokenizer(new FileReader(new File(
"D:\\StreamTokenizer.txt")));
stk.resetSyntax();
try {
//当没有读取到文件结尾时,不停调用nextToken方法,然后将每一个token及其行号打印出来。
while (stk.nextToken() != StreamTokenizer.TT_EOF) {
String s = null;
switch (stk.ttype) {
case StreamTokenizer.TT_WORD:
s = stk.sval;
break;
case StreamTokenizer.TT_NUMBER:
s = String.valueOf(stk.nval);
break;
default:
s = stk.sval;
}
System.out.println(stk.toString());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
继续读取D盘下的StreamTokenizer.txt文件,该文件的内容如下所示:
上述代码的执行结果如下所示:
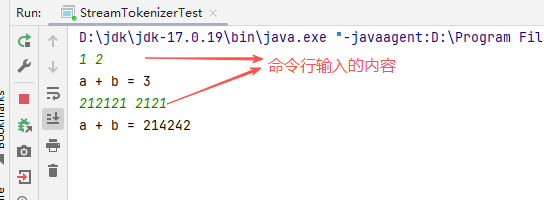
2.1.2、代替Scanner.class来读取命令行,并对命令行输入的内容进行token转换
代码如下所示:
import java.io.*;
public class StreamTokenizerTest {
public static void main(String[] args) throws IOException {
//将标准输入流传入StreamTokenizer中。
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
int a, b;
while (in.nextToken() != StreamTokenizer.TT_EOF) {
a = (int) in.nval;
in.nextToken();
b = (int) in.nval;
//out.println(a + b);
System.out.println("a + b = " + (a + b));
}
//将缓存区中的数据真实写出。
out.flush();
}
}
上述代码的执行结果如下所示:
参考资料:
https://www.cnblogs.com/moonfish1994/p/10222414.html
https://www.kancloud.cn/sunxiaoshufu/java/385495
https://www.oschina.net/uploads/doc/javase-6-doc-api-zh_CN/java/io/StreamTokenizer.html
原文地址: https://www.cveoy.top/t/topic/qGGh 著作权归作者所有。请勿转载和采集!