ELK 学习总结
劳心者治人,劳力者治于人。
导航
0、前言
ELK 是一套非常经典的日志 收集、搜索、分析、可视化 的平台,它的出现完美的解决了管理多台服务器时:日志分散无法集中管理、日志排查搜索困难、日志复杂无法被统计分析等问题。
ELK 这个名字来自三个核心组件的首字母: Elasticsearch + Logstash + Kibana,其中
Logstash:负责采集日志、流转过滤日志(解析日志、清洗数据、格式转换、转发数据)Elasticsearch:负责存储最终数据、建立索引、提供搜索功能Kibana:负责为 Elasticsearch 提供可视化界面
如上所示,早期的 ELK 采集日志的工作主要是由 Logstash 负责,但由于 Logstash 太过笨重且系统资源占用严重,后来就改用更轻量化的 Filebeat,而 Logstash 则转而去负责日志数据的统一流转过滤工作。各组件扮演角色如下:【注:有关 ELK 的详细演进过程可参考这篇 文章】
Filebeat:负责采集日志Logstash:负责统一流转过滤日志Elasticsearch:负责存储最终数据、建立索引、提供搜索功能Kibana:负责为 Elasticsearch 提供可视化界面
注:日志流转过滤其实就是对日志字段进行增删查改的动作,Filebeat 也具备简单的日志流转过滤的功能,但由于它位于终端侧且处理功能较为基础,故对于统一流转过滤的任务来说还是不如 Logstash,因此才出现了下图这样的架构。而如果我们的日志需求并不复杂并不需要数据流转过滤这种功能的话,在 ELK 架构中 Logstash 完全可以被剔除掉,只使用 Filebeat + Elasticsearch + Kibana 的组合即可。
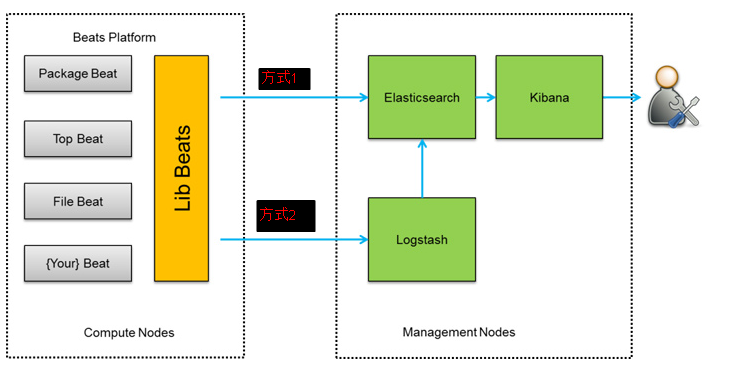
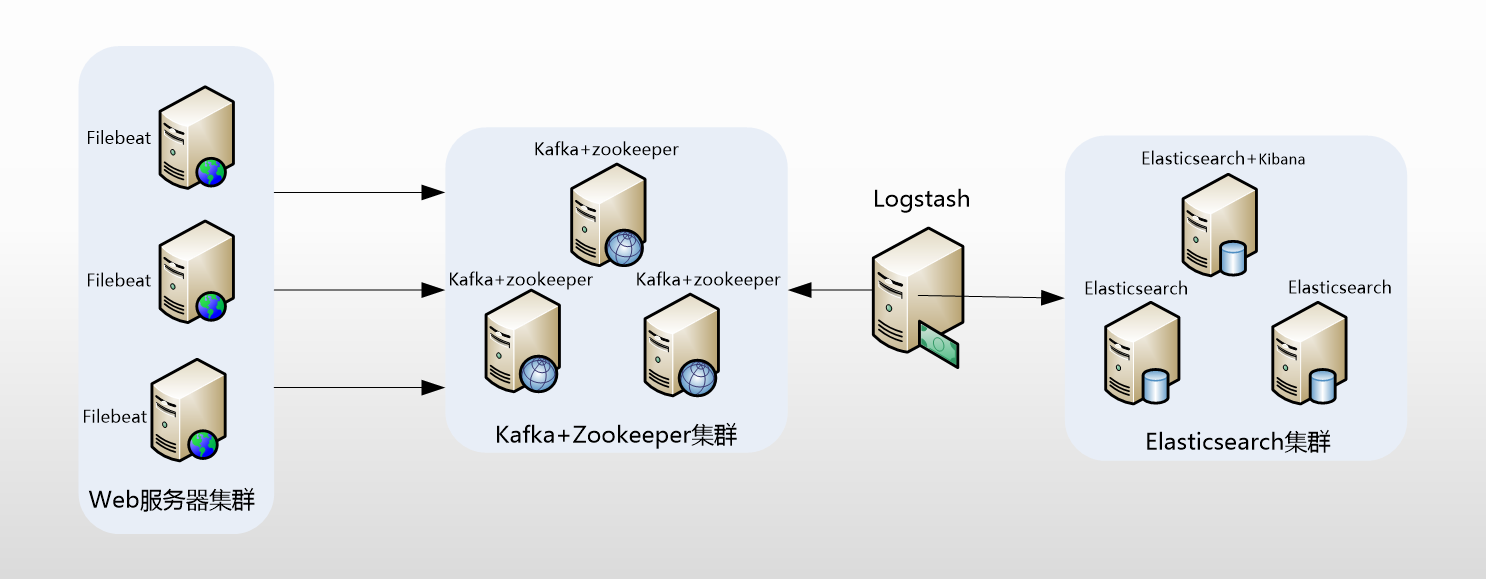
若业务更大、需求更复杂,则可以采用以下的集群架构设计:
1、绘图器 - Kibana
在 ELK 中,Elasticsearch 是整个系统的 核心存储与搜索引擎,它承担了系统中几乎全部功能,但它却只对外提供了一套 HTTP API 接口,没有提供可视化的图形交互界面,这使得普通用户使用它会非常的吃力。高级用户虽可通过 REST API 发送请求来增删改查数据、创建索引、执行搜索和聚合操作,但也极为不便。
为此,Kibana 诞生了!它是基于这套 API 接口来专门为 Elasticsearch 设计的可视化和交互界面,通过 Kibana,用户可以很方便的 查询 Elasticsearch 中的数据、绘制图表、构建仪表盘,轻松实现对日志数据的可视化和分析。
Kibana 将 Elasticsearch 的功能划分成了四个类别:分析、观测、安全、管理,虽然界面提供的功能很多,但其中大部分功能对于普通用户而言基本用不到,为此我只对自己觉得有用的页面功能做一个简要的介绍,以便能够更快的了解这套系统。
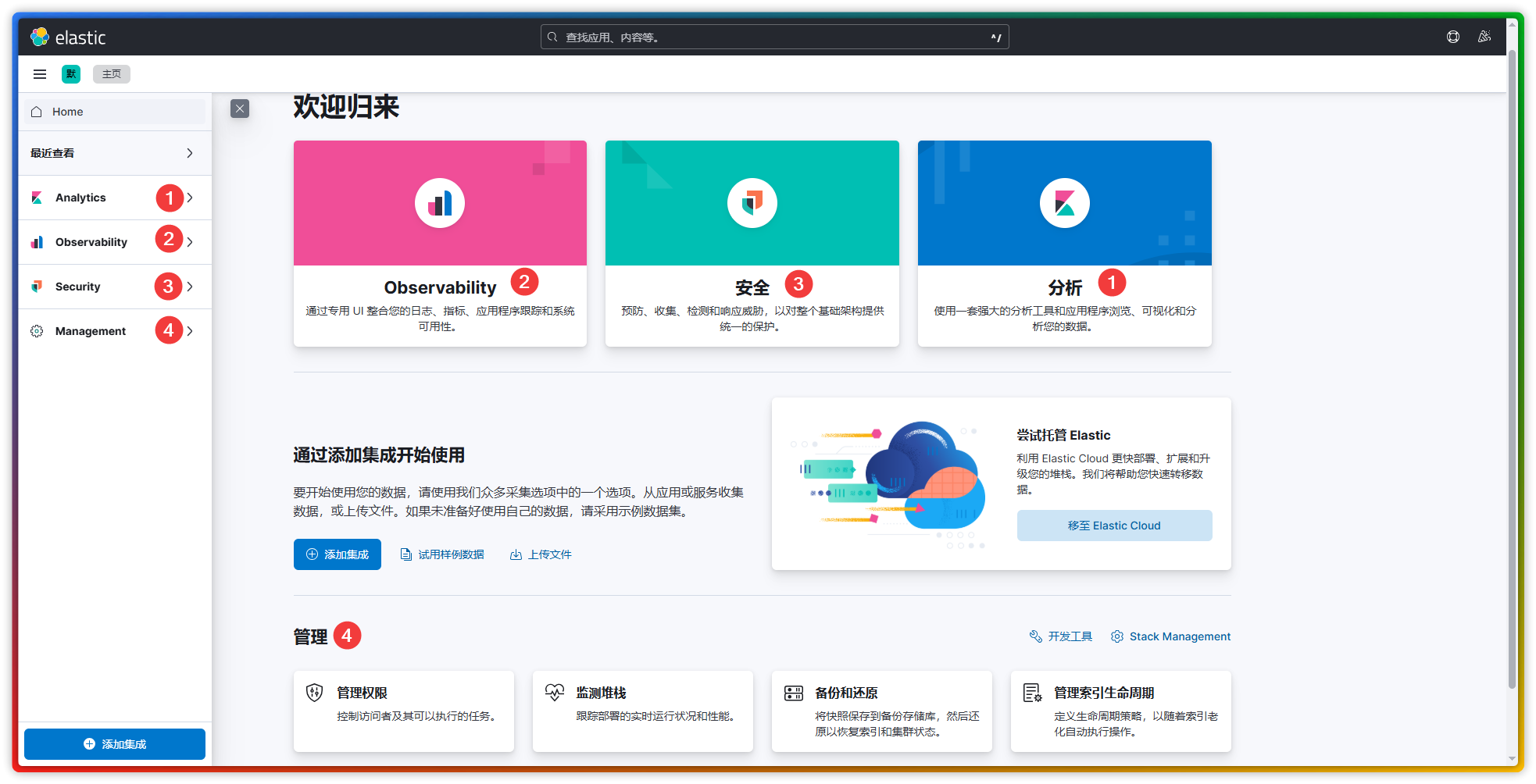
1.1、分析 - Analytics
分析菜单中的主要页面有: Discover、Dashboards、Maps、Visualize 库
【1】Discover 页面功能介绍
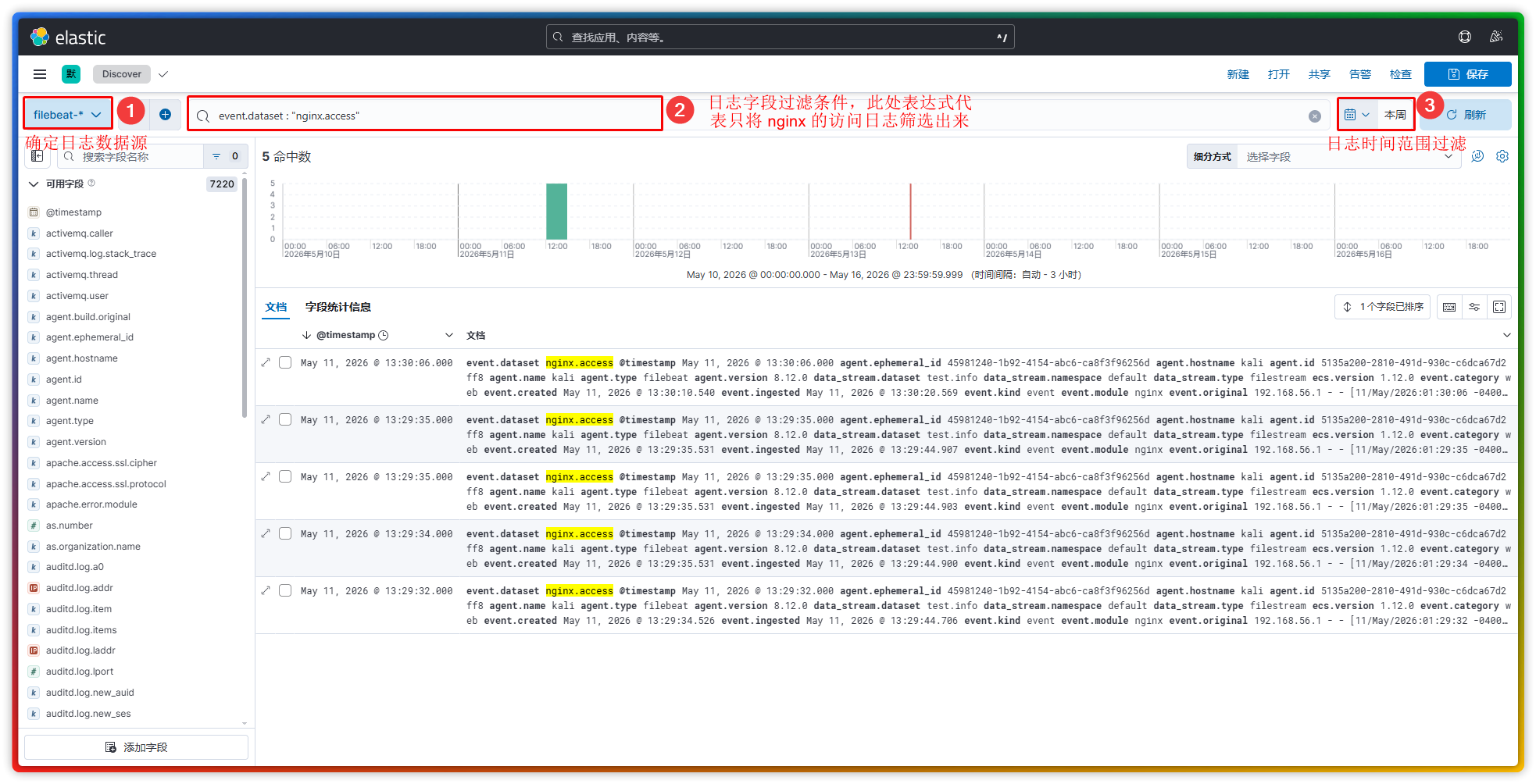
注:(1)上图保存的作用是可以将这个搜索过滤条件作为一个可视化组件保存起来,以供在自定义面板的时候可以去调用使用。(2)日志数据源又叫做数据视图,它代表着我们可以从哪些索引存储中去读取日志数据。【① 处的子选项“管理数据视图”和 “Stack 管理-数据视图”是一个意思。】
【2】Dashboards 常用预置面板【注:与集成中的应用是一一对应的关系】
- 系统日志: [Filebeat System] Syslog dashboard ECS
- Apache HTTP 服务器日志: [Filebeat Apache] Access and error logs ECS
- Nginx 日志:[Filebeat Nginx] Overview ECS
- MySQL 日志: [Filebeat MySQL] Overview ECS
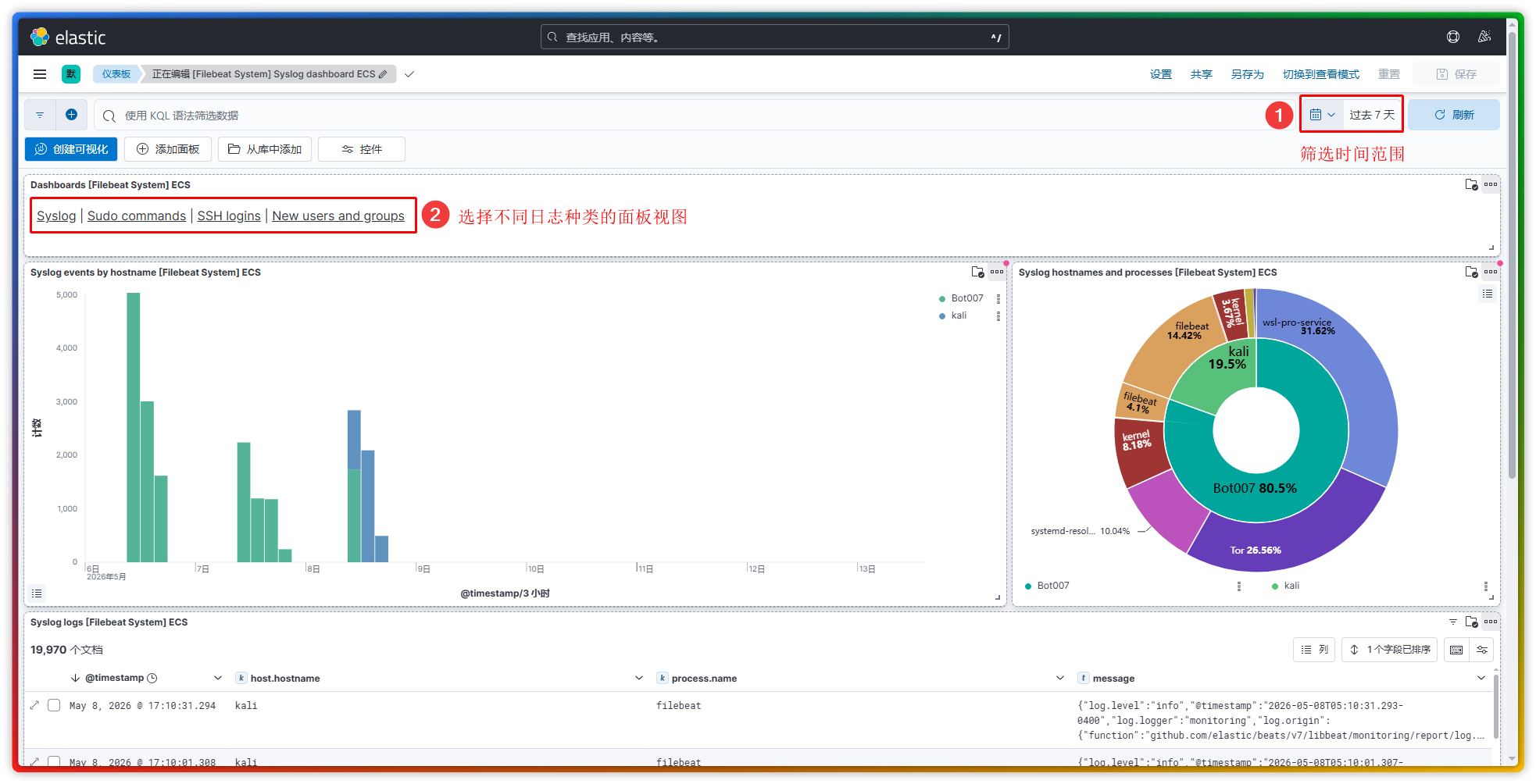
【3】Visualize 库组件(可视化组件)
- Lens:可拖拽式的图表工具,系统可根据字段类型自动选择合适的聚合方式,使用起来很智能、很省力。
- 基于聚合:传统的图表工具,用户需要手动完成聚合的配置。
- 文本:主要用于仪表盘描述说明,支持 Markdown 语法,以及可调用的系统变量。
- Maps:地理位置可视化图表,只有当日志数据的字段中携带地理坐标字段时,才适合使用此组件,否则一片空白。【注:filebeat 的 nginx 模块可以将访客 ip 直接转换成地理坐标字段,因此该组件对于分析 nginx 日志来说很好用。切记,内网 ip(如 192.168.1.1)这类的地址不会被转换为地理坐标字段。】
(1)为了弄清 Lens 图表 和 基于聚合的图表 之间有什么区别,我特地制作了一组关于统计年龄段及年龄段内工资范围的统计图,用以观察二者之间的区别:

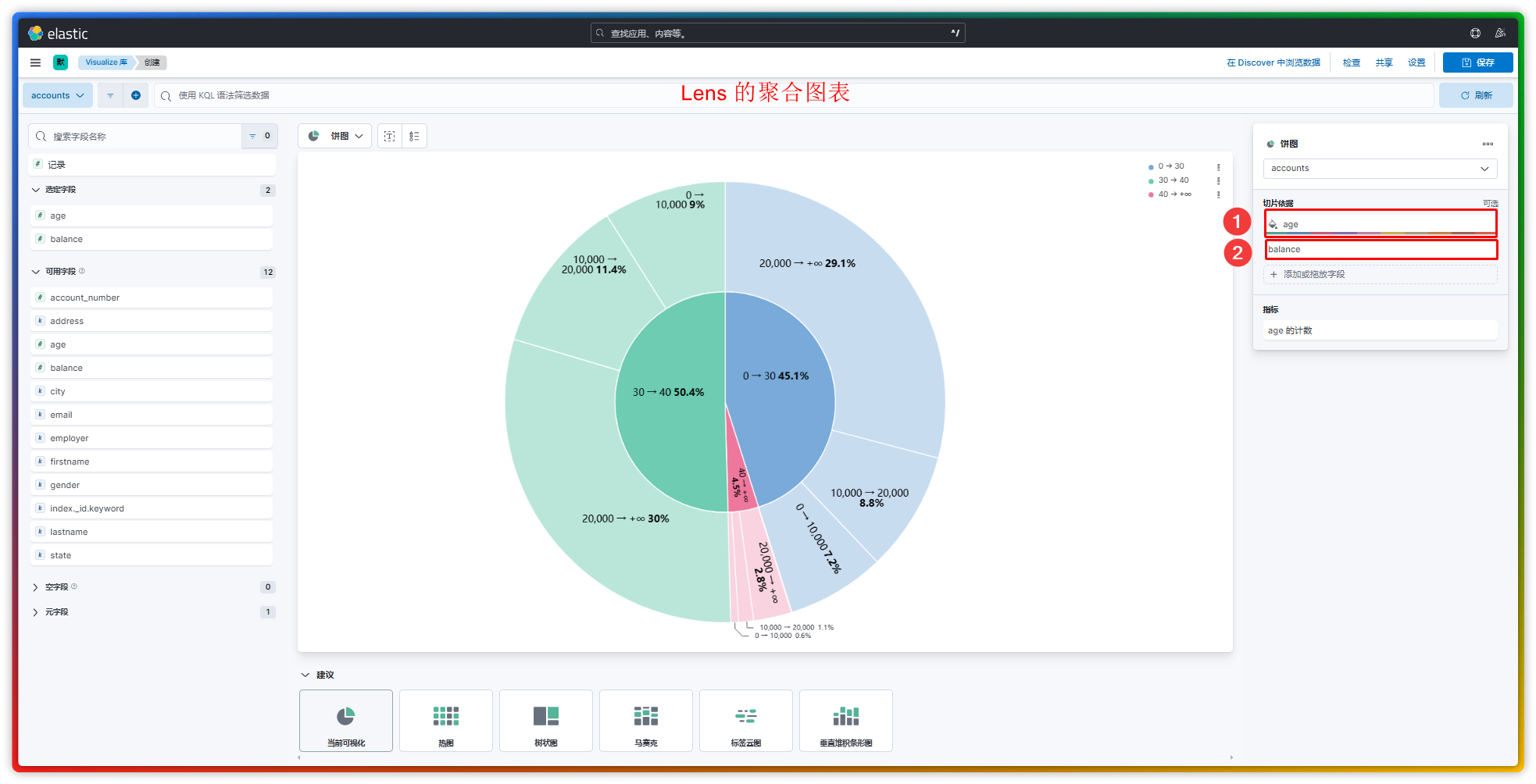
对比来看,二者似乎也就是设置方式上的不同而已,其它并无差别。
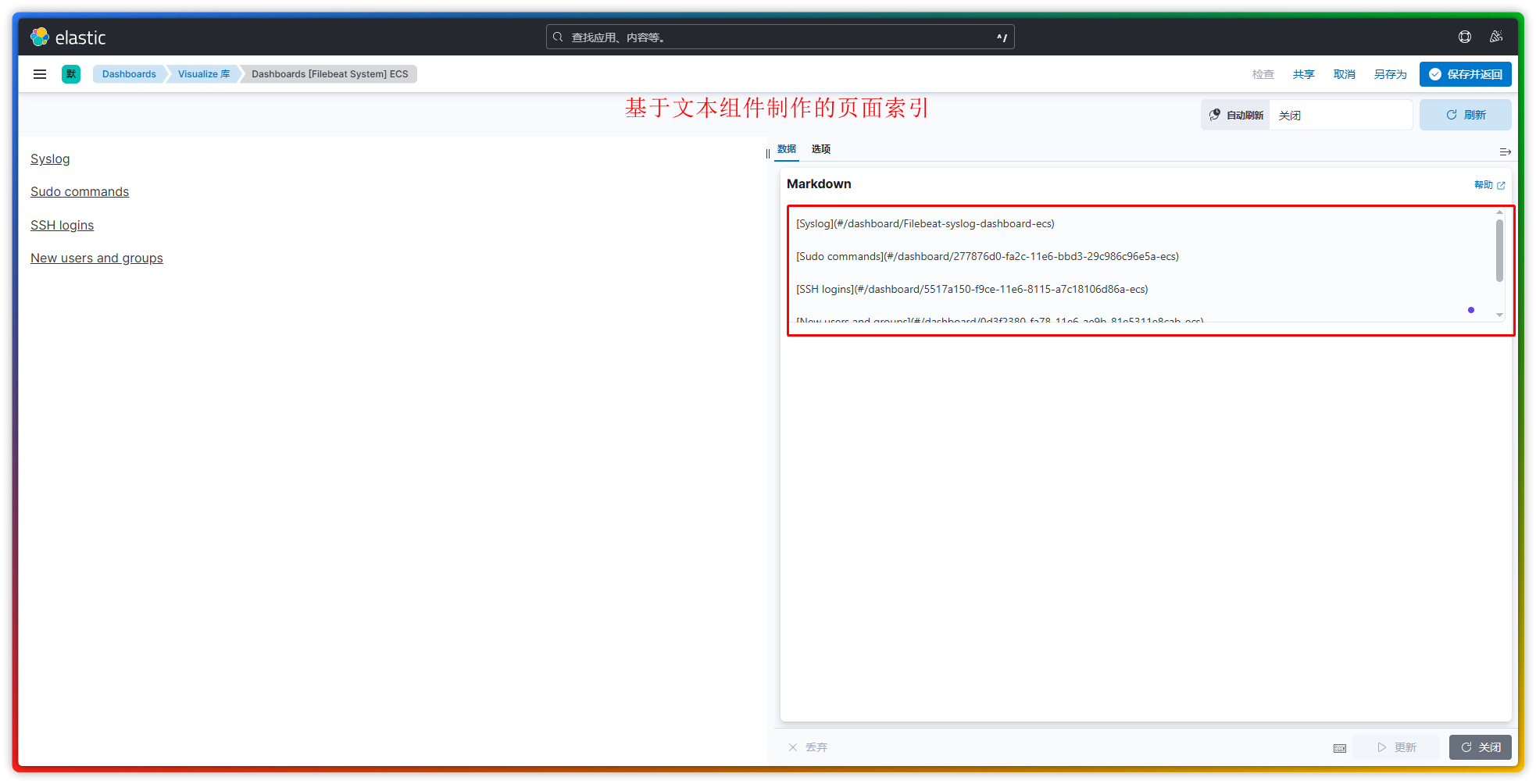
(2)下面是关于 文本组件 的设置界面,可以看到它的使用界面非常的简单,而它的作用也无非就是:描述说明、超链接跳转页面。
(3)Maps 组件 的设置相对来说还是比较麻烦的,而且使用它还有一个前提条件,那就是:日志数据的字段中一定要包含 地理位置坐标的字段 才行,否则该 Maps 组件将无法正常显示。
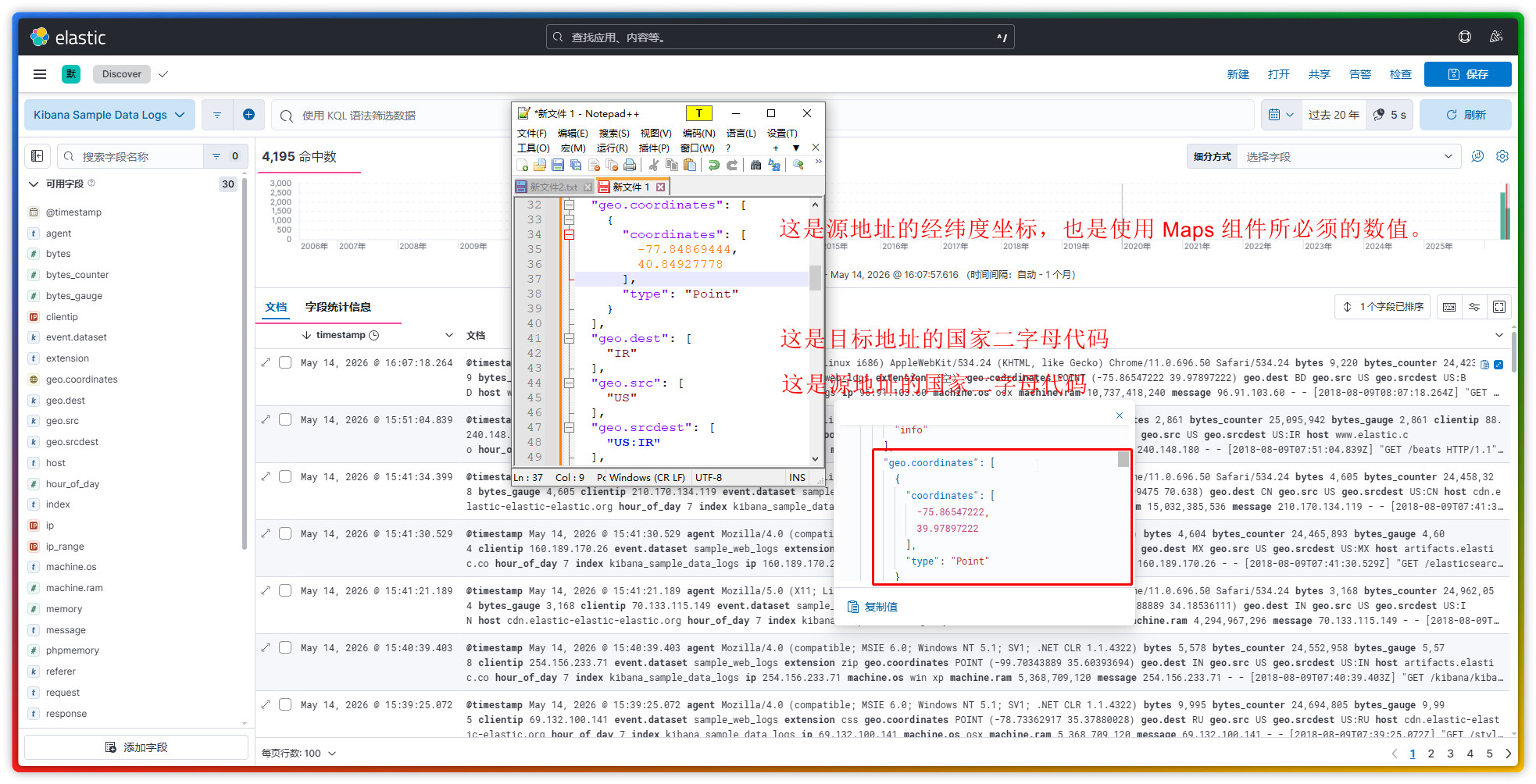
此处只列举 3 个我已了解的图层作为示例:
- EMS 边界:以国家、省份、城市为单位,去统计各区域的访问事件。【注:联接中的左字段指的是地图上的国家代码,右字段指的是日志数据中指定的带国家代码的字段,如
geo.src或geo.dst。】 - 热力图:通过颜色强度展示数据密度或数值大小,让热点区域一目了然。【注:以日志数据中的
geo.coordinates为主要的参考字段,不可指定其它字段。】 - 集群:把地理坐标密集的点聚合显示,避免地图上出现“点过多,看不清”的情况。【注:以日志数据中的
geo.coordinates为主要的参考字段,指标中可指定其它字段作为计数统计。】
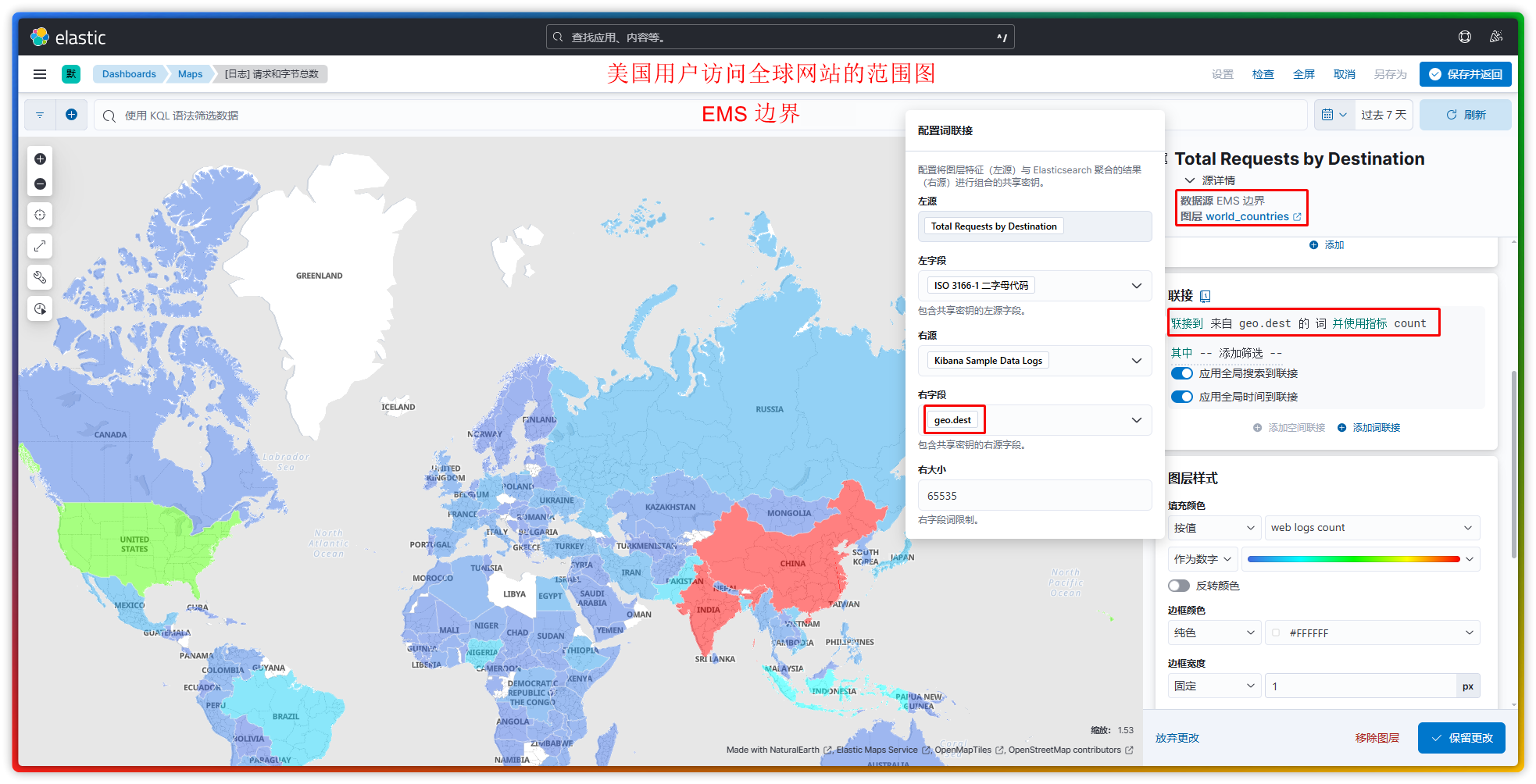
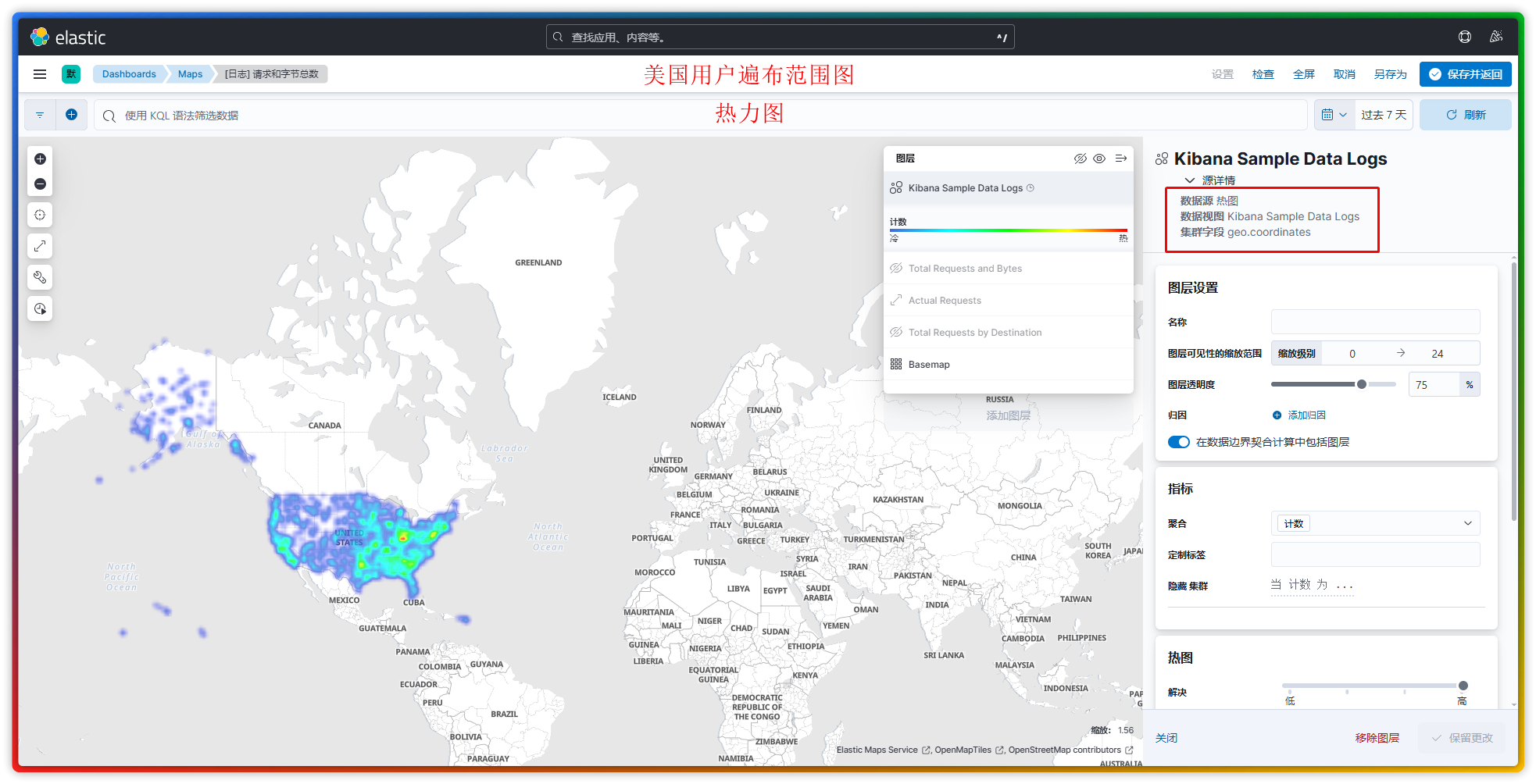
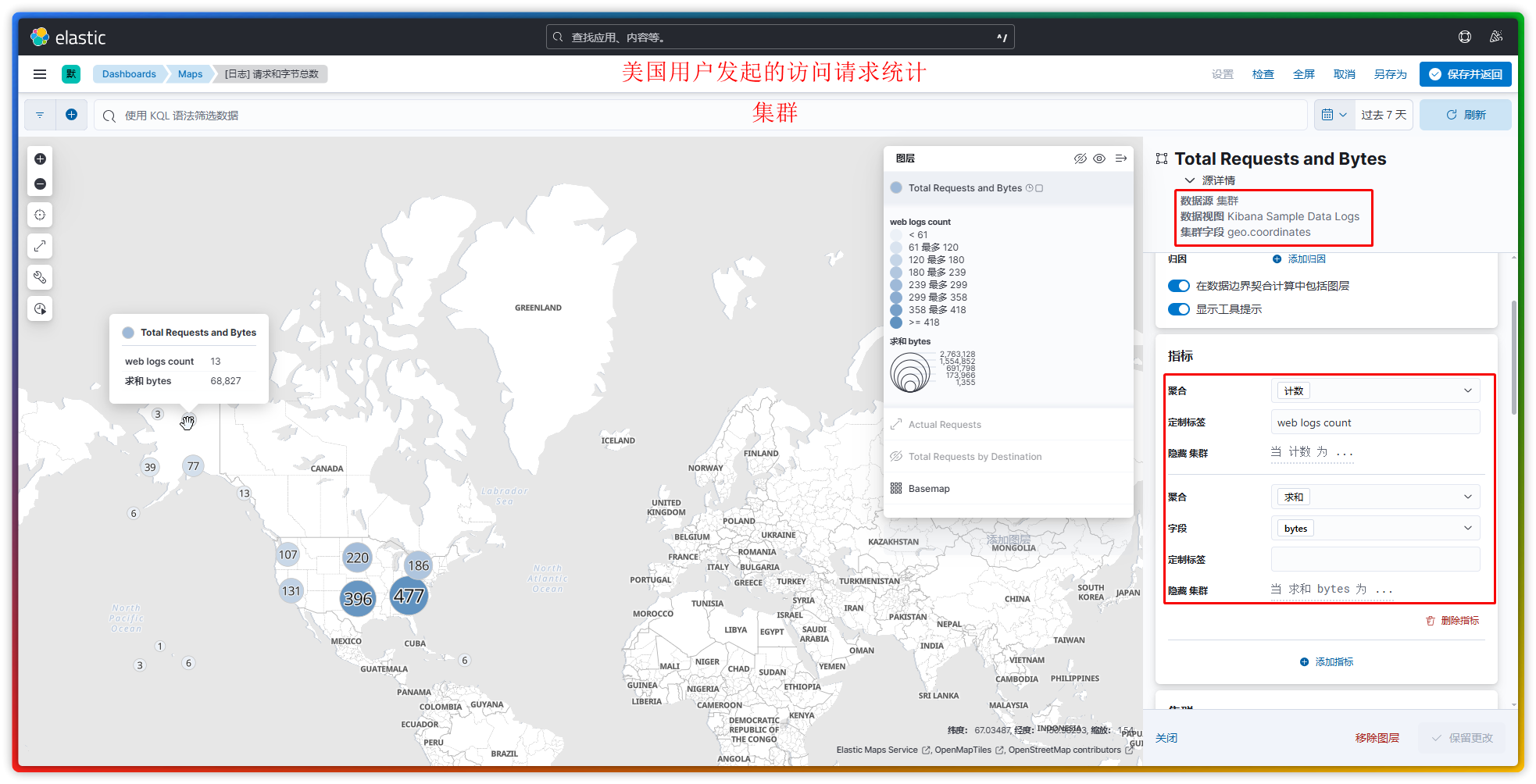
注:Maps 也属于可视化库中的组件,只不过由于这个组件较为复杂和特殊,故 Kibana 将其从可视化组件中拉了出来并单独为其设立了一个叫做 Maps 的菜单。
1.2、观测 - Observability
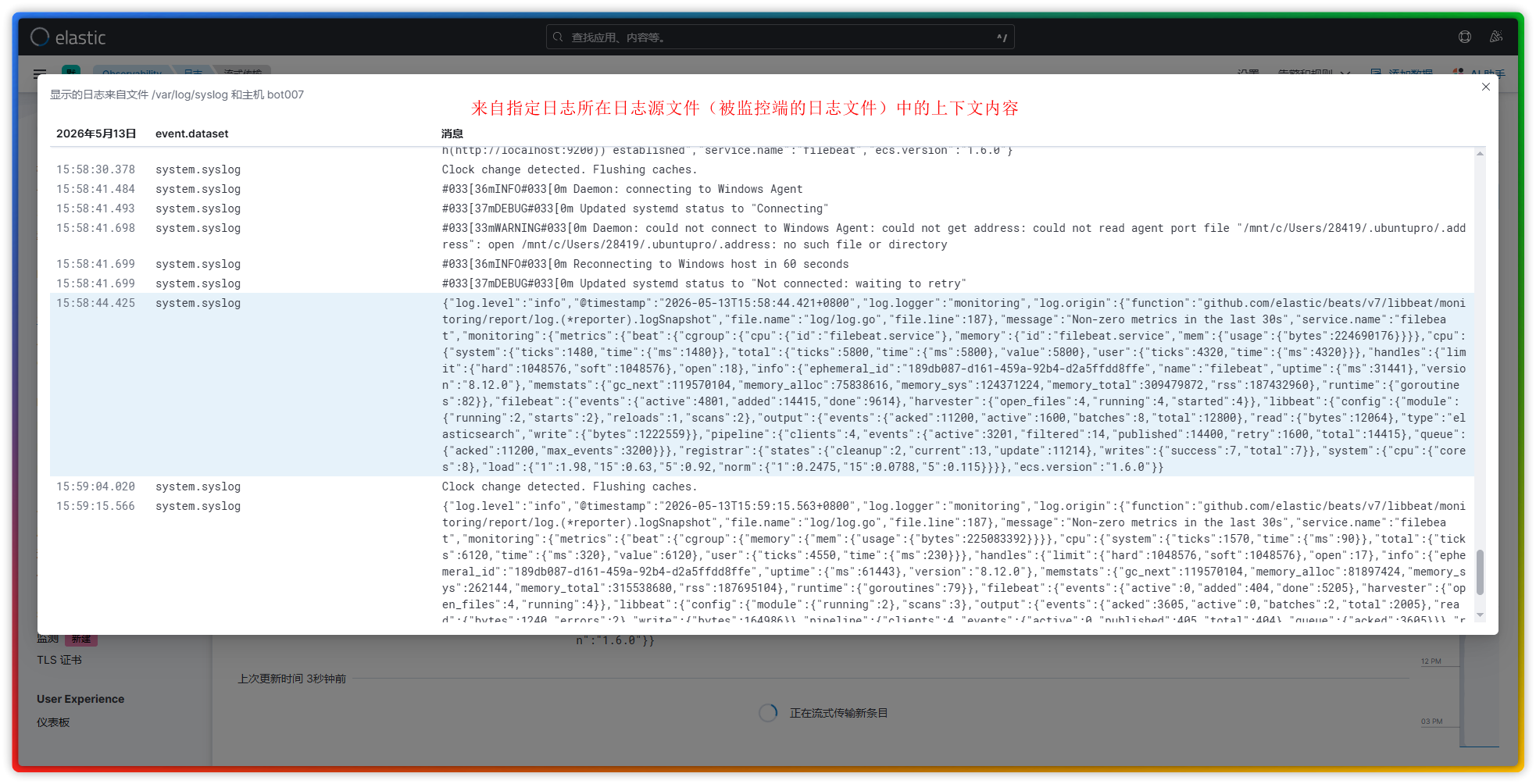
观测菜单中的页面功能多偏向于系统指标检测,如同 grafana 那样。但在日志监控这个范畴里,这个菜单中实际常用到的也就是实时日志流这个功能了,它可以实时查看被监控端传输过来的日志信息,以及该日志对应的日志上下文内容。
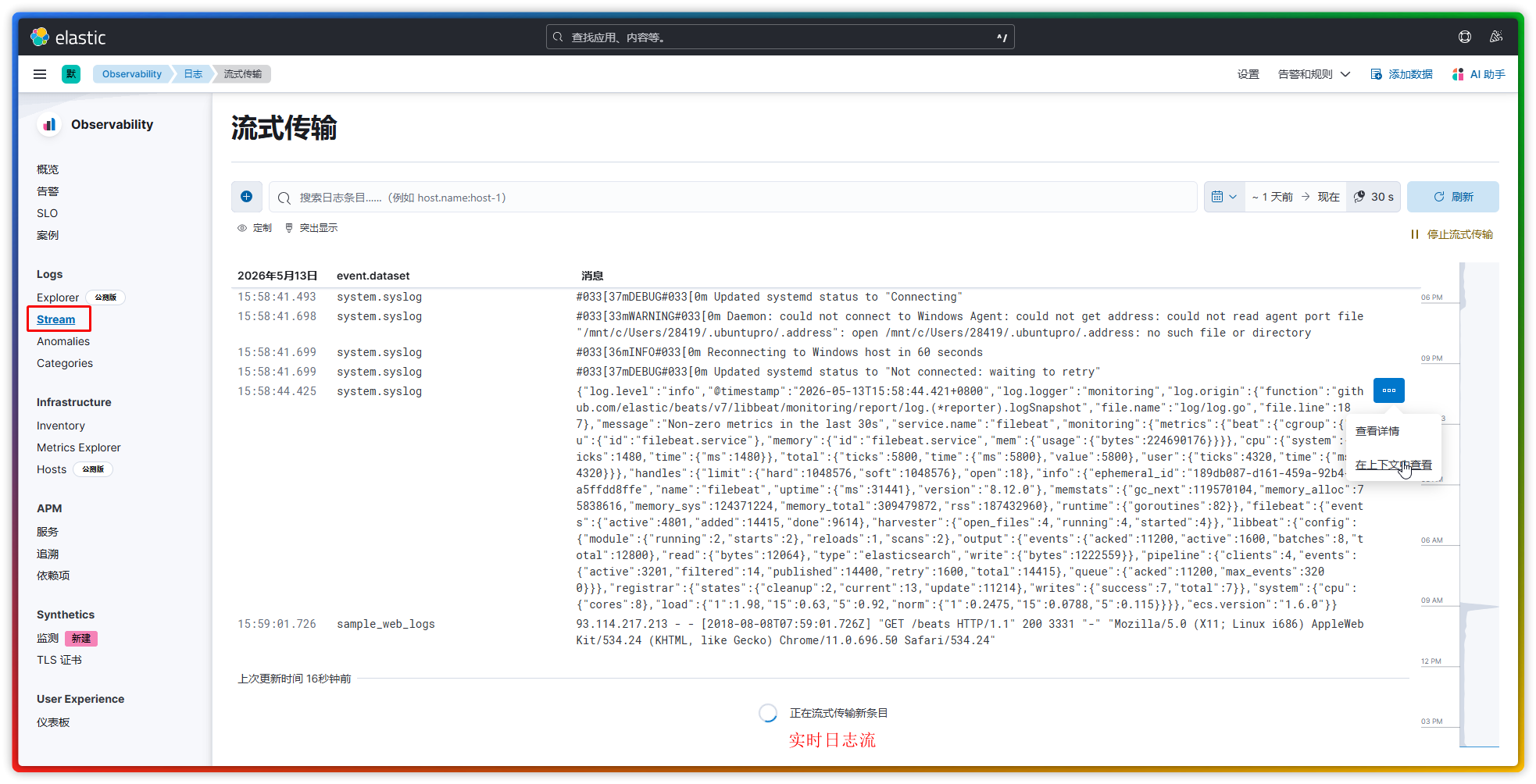
1.3、管理 - Management
管理菜单中的主要页面有:集成、Stack 管理。
【1】集成页面提供了 ELK 原生支持的众多常见应用,这使得我们只需进行几个简单的步骤,便能够将选中应用的日志监控添加到 ELK 系统中。例如下图这个针对 Linux 系统日志的监控:
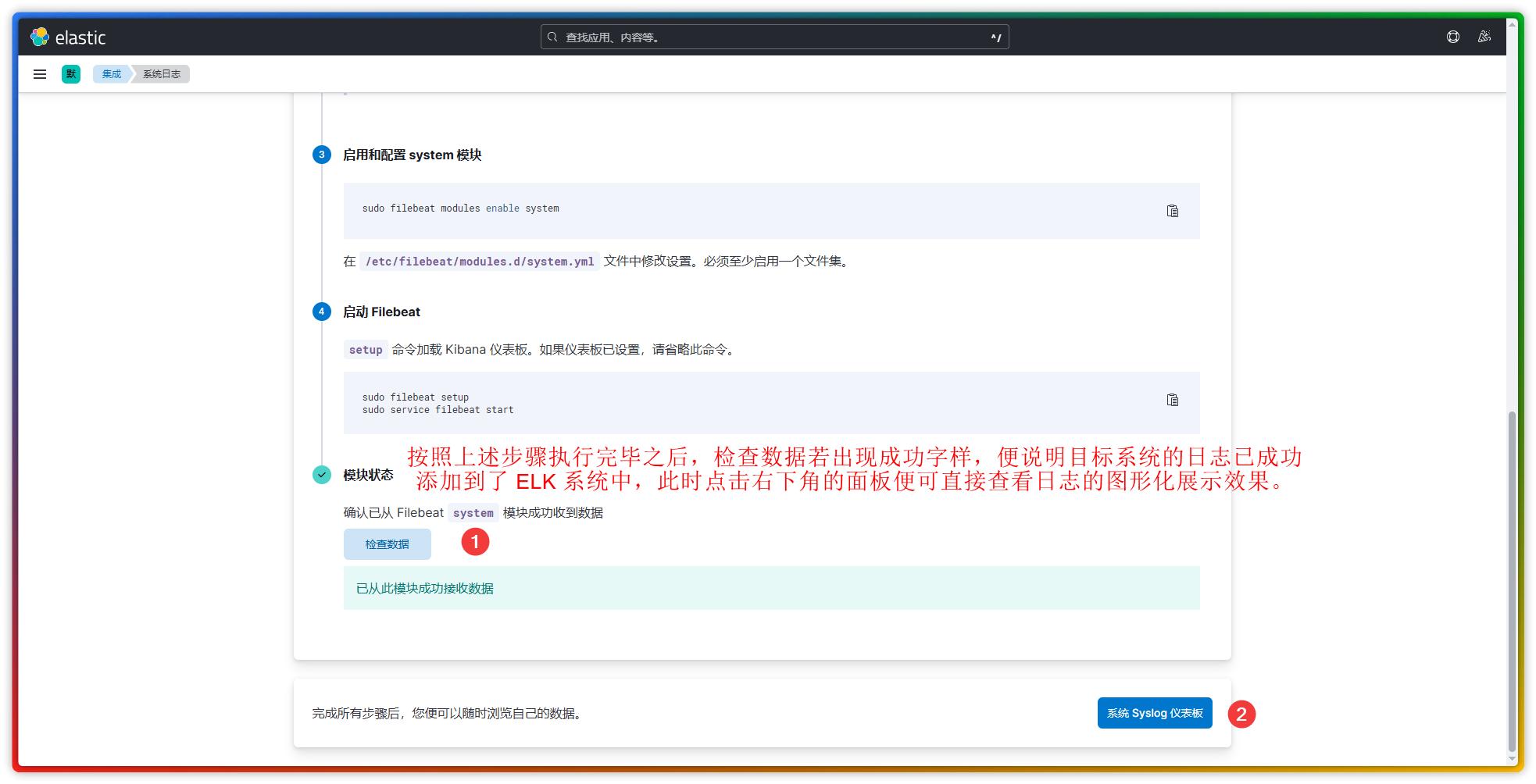
注:若你要监控的应用不再 ELK 支持的集成范围之内,那么便需要你自行(1)制定 filebeat 配置文件,(2)制作可视化组件,(3)将组件统一整合到面板。
注:集成中的这两个功能在测试/学习的过程中可能会很有用:上传文件、样例数据。
【2】Stack 管理页面中的这几个功能(采集管道、索引管理)一般并不需要我们去配置它们,但却需要知道它们,以便能够加深对 ELK 的理解。
- 索引模板:类似 模板或规则,定义索引的 结构、映射、设置、别名。当创建索引或数据流时,可自动应用模板数据,免去为创建索引重复指定相同的设置项。
- 索引:Elasticsearch 中存储数据的基本单位,相当于数据库里的 表,专门用来存储文档数据。【注:对索引模板的要求是 可选 状态】
- 数据流:数据流是 索引的集合,相当于是把多个索引归置到同一个文件夹中,然后统一管理。【注:对索引模板的要求是 必选 状态】
- 处理器(Filebeat):在 filebeat 将数据发送到 Elasticsearch 之前,对日志字段进行 简单的流转过滤处理。
- 采集管道(Elasticsearch):在 Elasticsearch 接收到 filebeat 发来的数据并准备将其写入到索引之前,对日志字段进行 复杂的流转过滤处理。
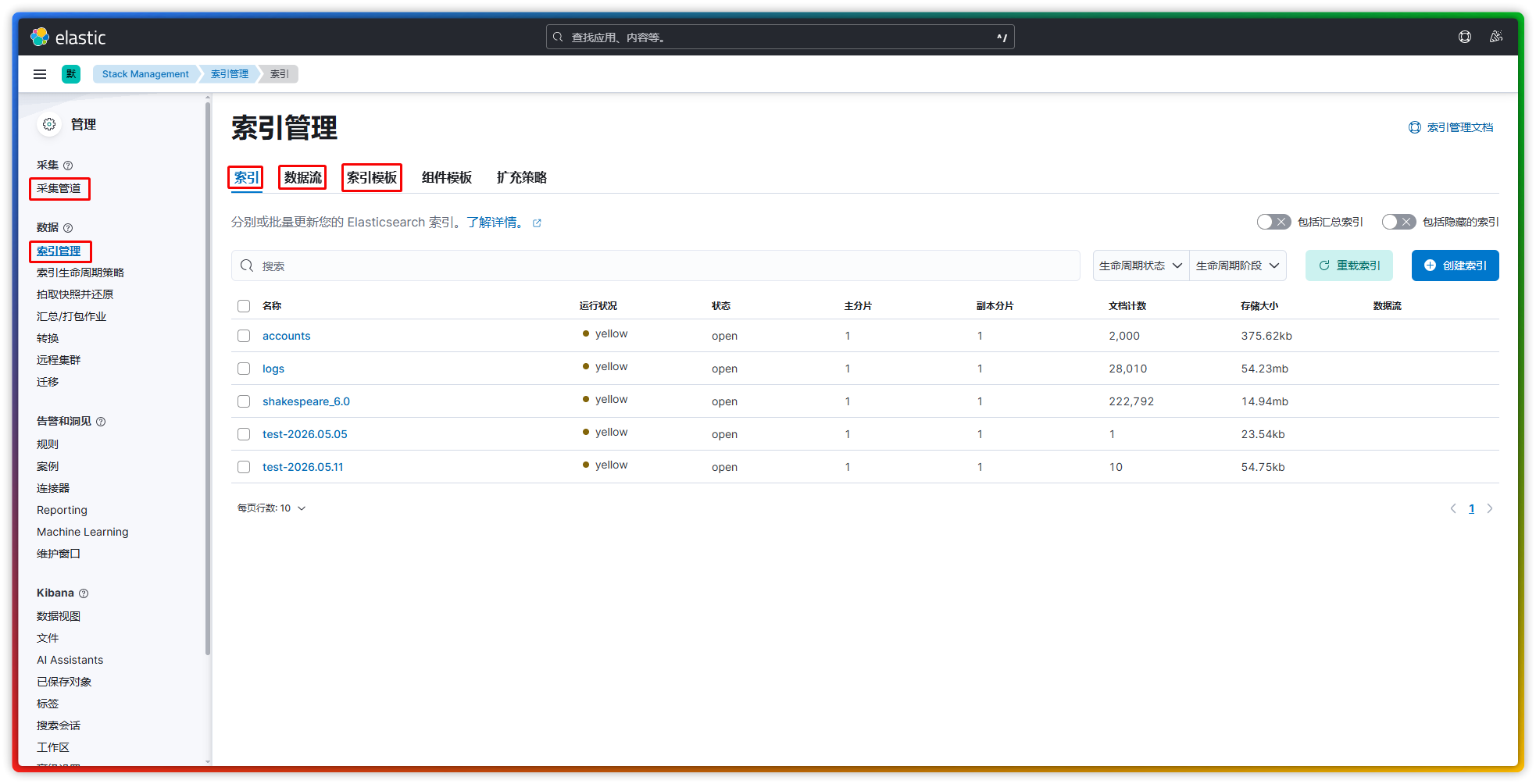
日志数据被读取、上传、存储到索引的整个流程:(1)filebeat 先从日志文件中取到最原始的日志数据,然后在本地按照某种规则对其进行格式化字段处理,不同的模块对日志的格式化处理的方式也是有所不同的,这一点可在本地通过 output.console 去调试查看;(2)根据本地配置文件中的处理器设置对日志字段进行再处理,然后发往 Elasticsearch,发送的时候会指定一个需要远端再处理的 pipline 管道名(模块 input 日志一般都会携带 pipline,自定义 input 日志可能没有。)以及隐式指定对应的索引或数据流名称(可在 Discover 中查看日志的 _index 字段);(3)Elasticsearch 在收到日志数据之后,会根据 pipline 管道的设置对日志字段进行再处理;(4)最终才将这条日志数据存储在指定的索引中。
2、存储器 - Elasticsearch
注:该服务启动起来即可,基本没有什么需要频繁配置的地方。
- 索引:存储数据的 逻辑容器,类似关系型数据库的 表(Table)。
- 分片:将索引划分成 多个分片(Shard) 来分布存储和并行搜索。
- 主分片:实际存储数据的基本单元。
- 副本分片:主分片的拷贝,用于高可用和负载均衡。每个索引可以设置主分片数和副本数。
注:(1)一个索引一般对应一个主分片,若索引数据量很大的话,则一个索引可能会被分成多个主分片;(2)副本分片相当于是对主分片的几次备份,如果集群节点是 3 个,那么副本分片可以设置成 2 个,这样主节点保存一份主分片,其它节点各保存一份副本分片,这样当主节点损坏的时候,索引数据不丢是。
3、采集器 - Filebeat
ELK 的专属采集器是 beats 工具套件,filebeat 只是该套件中一个专门负责日志文件采集的工具,其它还有:
- Filebeat:负责 日志采集。例如 系统日志 syslog 等、应用日志 nginx 等。
- Metricbeat:负责 指标监控数据采集。例如 CPU、内存等指标。
- Heartbeat:负责 存活检测/可用性监控。例如 网站是否在线、TCP 端口是否可访问等
- Winlogbeat:负责采集 Windows 事件日志。例如 系统事件、安全日志等
- Packetbeat:负责 网络流量分析。类似于轻量级的 Wireshark。
- Auditbeat:负责 Linux 安全审计。例如 用户行为、登录行为等
由于本文仅关注日志的采集任务,因此只介绍 Filebeat 相关的配置及用法,至于其它工具的配置用法可参考 官方手册。
3.1、配置文件
Filebeat 配置文件中的内容主要分为四个部分:全局参数、输入、输出、处理器,其中 输入、输出、处理器 较为重要一些,故以下会专门介绍它们各自的配置用法。
【1】输入配置
输入配置中的这些类型需要注意下:filestream、syslog、input。
#(1)两个文件流类型的输入配置 [/etc/filebeat/filebeat.yml]
filebeat.inputs:
- type: filestream
id: my-filestream-id1
enabled: true
paths: [/var/log/nginx/*.log]
- type: filestream
id: my-filestream-id2
enabled: true
paths:
- /var/log/*.log
- /tmp/test.txt
output.elasticsearch:
hosts: ["http://1.1.1.1:9200"]
#(2)文件流类型+模块类型的输入配置 [/etc/filebeat/filebeat.yml]
filebeat.inputs:
- type: filestream
id: my-filestream-id1
enabled: true
paths:
- /var/log/*.log
- /tmp/test.txt
- module: nginx
access:
enabled: true
error:
enabled: true
output.elasticsearch:
hosts: ["http://1.1.1.1:9200"]
注:(1)输入配置官方 参考手册、模块配置官方 参考手册。(2)模块类型的配置可通过
filebeat modules enable nginx去直接启用,无需如上述这般全都写在 filebeat.yml 配置文件之中。切记:模块启用之后还需要手动将/etc/filebeat/modules.d/nginx.yml文件中的 enabled 处的 false 修改 为 true 才算是正式启用了该模块。
【2】输出配置
#(1)最基本的输出配置 [/etc/filebeat/filebeat.yml]
filebeat.inputs:
- type: filestream
id: my-filestream-id1
enabled: true
paths:
- /var/log/*.log
output.elasticsearch:
hosts: ["http://1.1.1.1:9200"]
#(2)多索引的输出配置 [/etc/filebeat/filebeat.yml]
filebeat.inputs:
- type: filestream
id: nginx-log
paths: [/var/log/nginx/*.log]
fields:
log_type: nginx
- type: filestream
id: app-log
paths: [/var/log/app/*.log]
fields:
log_type: app
output.elasticsearch:
hosts: ["http://1.1.1.1:9200"]
indices:
- index: "nginx-%{+yyyy.MM.dd}"
when.equals:
log_type: nginx
- index: "app-%{+yyyy.MM.dd}"
when.equals:
log_type: app
#(3)本地调试的输出配置 [/etc/filebeat/console.yml]
# 请注意:此时 filebeat 的启动方式需要以命令的方式去启动,而非后台服务的方式去启动 filebeat run -c console.yml
filebeat.inputs:
- type: filestream
id: my-filestream-id
paths:
- /tmp/test.txt
- module: nginx
access:
enabled: true
output.console:
pretty: true
注:输出配置官方 参考手册。
【3】处理器配置
# 删除日志中包含 DBG 的数据 [/etc/filebeat/console.yml]
filebeat.inputs:
- type: filestream
paths:
- /tmp/test.txt
processors:
- drop_event:
when:
regexp:
message: "^DBG:"
output.console.pretty: true
注:处理器配置官方 参考手册。
3.2、命令用法
# 面板、索引模板、pipline 初始化
filebeat setup
# 列出 ELK 支持集成的应用模块
filebeat modules list
# 开启/禁止 监控应用日志的模块
filebeat modules enable/disable nginx
# 测试指定配置文件的语法是否正确
filebeat test config -c filebeat.yml
# 测试 filebeat 中 output 处配置的 Elasticsearch 的连接是否可用
filebeat test output -c filebeat.yml
# 以指定配置文件的方式去启动 filebeat 程序
filebeat run -c testfile.yml
4、杂项
(1)参考文档:
(2)ELK 手动部署教程:kibana、elasticsearch
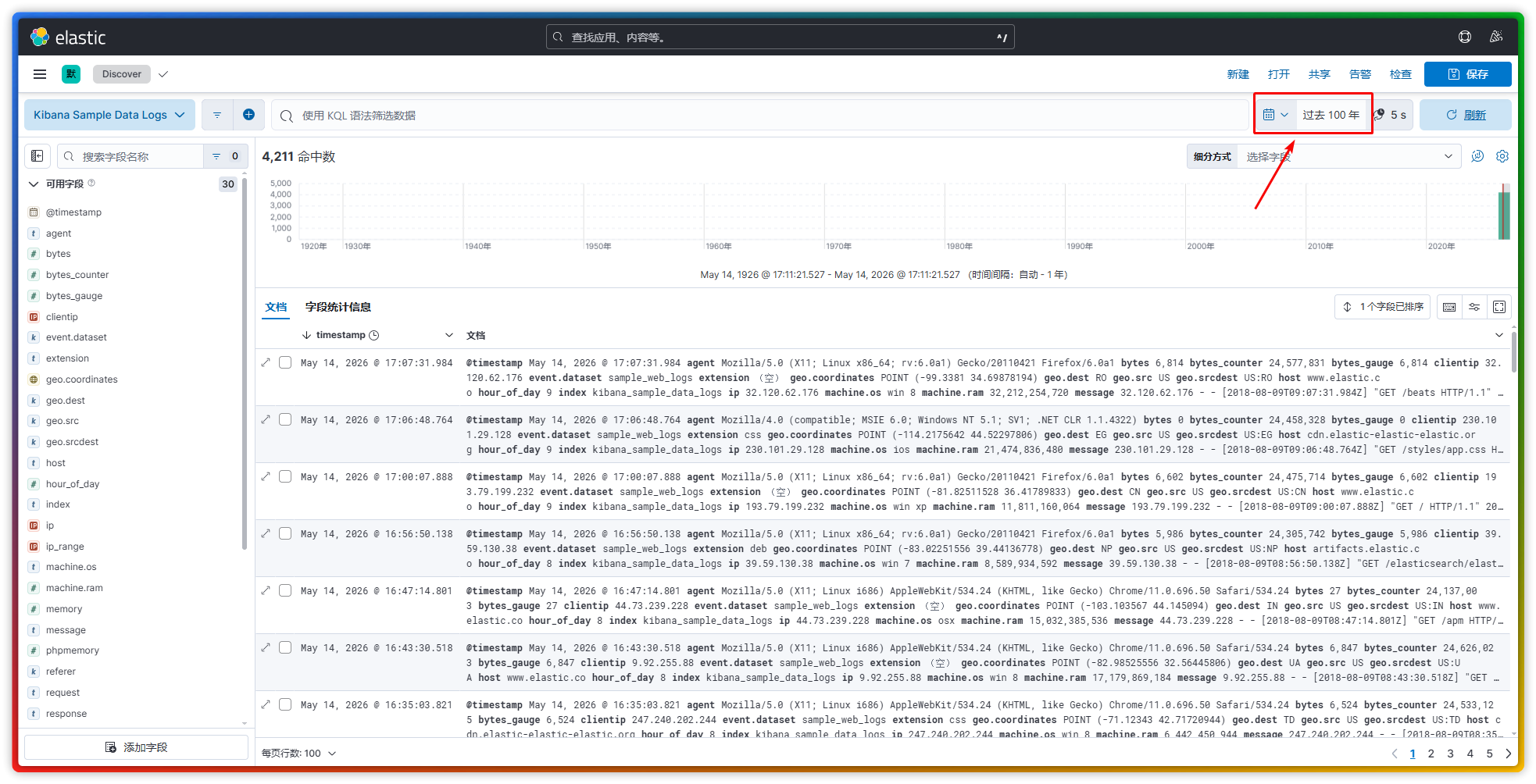
(3)Kibana 内置了几个样本数据,以供我们在无需配置 Filebeat 的情况下,也可以随时有数据供我们参考。不过这些数据发生时间可能有点久了,因此在浏览的时候若无数据显示的话建议将时间过滤的条件添加为 100 年之前。【位置 1:管理-集成-上传文件-样例数据-其他样例数据集】【位置 2:https://www.elastic.co/guide/cn/kibana/current/tutorial-load-dataset.html】
(4)Kibana 的登录功能完全依赖于 Elasticsearch,当 Elasticsearch 关闭了安全功能 xpack.security.enabled=false 时,Kibana 便也不再需要登录,直接便进入了“无认证模式”。
(5)Filebeat 的 system 模块依赖于 syslog、auth、这些系统日志,而这些日志是由 rsyslog 服务制作出来的,因此如果系统没有运行 rsyslog.service 服务的话,这些日志便不会存在,Filebeat 也将无日志数据可上传,此时 system 模块也就相当于无效状态。
(6)Filebeat 的 ngixn 模块可以自动将 nginx 访问日志中的 ip 信息转换为带 geoIP 格式的日志数据传输给 elasticsearch,以供 Kibana 的 Maps 组件去使用。
(7)Filebeat/Elasticsearch 会默认给事件添加 @timestamp 字段,而这个字段的值一般代表着这条日志数据被 Elasticsearch 接收时的时间。但如果 pipeline/module 从日志内容中解析出了事件的时间,那么 @timestamp 这个字段的值就不再是“接收时间”,而是以日志携带的时间为准。【注:这样做可以很好的防止日志积压滞留时,导致采集到的日志与日志实际发生时间不相符的问题。】
(8)自定义的 input 日志路径,和 system 模块里的默认路径,会不会冲突/重复?不会,各干各的。两者是“完全独立的两套采集机制”,但如果路径重叠,就会造成“重复采集”。【注意:(1)由于所有 input 和模块的输入数据全部都会被当作一个数据源去存储,因此在 web 端 discover 过滤的时候,需要关注 log.file.path 以区分不同的日志路径;(2)日志内容的格式无所谓,哪怕是 123 这样的数据依旧可以被传输过去;(3)不同模块的日志的区别,可通过 event.dataset : "system.syslog" 的方式去过滤;】
(9)Filebeat 设置 setup.template.name: "filebeat" 只是:“给 Filebeat 初始化出来的索引模板改了个名字”,它不会改变:模板内容、ECS 映射、pipeline、字段结构、数据流行为,这些东西。例如在默认情况下,Filebeat 可能创建 filebeat-8.15.0 这样的模板名。你改成 setup.template.name: "mylogs" 之后,Filebeat 便会创建 mylogs 或者 mylogs-8.15.0 这样的名称。当索引模板改了之后,这时候创建索引的时候索引模式就也要相应的改动了。
(10)存疑:filebeat setup 是初始化 Filebeat 环境用的命令,用来创建出适合当前系统环境的索引模板、解析规则和 Kibana 仪表盘数据。本命令一般只在 Filebeat 初次被安装时执行一次,后续一般来说便不需要再执行它了。此外,建议 filebeat 和 elasticsearch 的软件版本尽量保持一致,避免出现版本不同、数据混乱的问题。
(*)Docker 部署实例:
#(1)EK + filebeat 组合【注:filebeat 向 elastic 传输数据】
# 注意:第一次执行可能会失败,此时将当前目录下的 elasticsearch/* 赋予 777 权限后再次执行即可成功。
services:
elasticsearch:
image: elasticsearch:8.12.0
environment:
- discovery.type=single-node # 单节点部署
- xpack.security.enabled=false # 免认证登录
- ES_JAVA_OPTS=-Xms512m -Xmx512m
ports:
- 9200:9200
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
networks:
- default
kibana:
image: kibana:8.12.0
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200 # 指定 Kibana 连接 Elasticsearch 服务器
- I18N_LOCALE=zh-CN # 设置 Kibana 的界面为中文语言
ports:
- 5601:5601
depends_on:
- elasticsearch
networks:
- default
networks:
default:
driver: bridge
#(2)ELK + filebeat 组合【注:filebeat 向 logstash 传输数据】
services:
elasticsearch:
image: elasticsearch:8.12.0
ports:
- 9200:9200
environment:
discovery.type: single-node
xpack.security.enabled: "false"
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
networks:
- default
kibana:
image: kibana:8.12.0
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200 # 指定 Kibana 连接 Elasticsearch 服务器
- I18N_LOCALE=zh-CN # 设置 Kibana 的界面为中文语言
ports:
- 5601:5601
depends_on:
- elasticsearch
networks:
- default
logstash:
image: logstash:8.12.0
ports:
- 5044:5044
depends_on:
- elasticsearch
networks:
- default
networks:
default:
driver: bridge
#(3)集群 EK + filebeat 组合
# 参照官方配置的 docker-compose.yml 文件即可
# 用法说明:https://www.elastic.co/docs/deploy-manage/deploy/self-managed/install-elasticsearch-docker-compose
# 模板位置:https://github.com/elastic/elasticsearch/tree/main/docs/reference/setup/install/docker
# 注意事项:
#(1)需要修改环境变量文件 .env 中的 ELASTIC_PASSWORD、KIBANA_PASSWORD、STACK_VERSION 这三个变量的值,例如 STACK_VERSION=9.4.0
#(2)Kibana 界面语言默认是英文,可在 docker-compose.yml 服务 Kibana 的环境变量中添加 I18N_LOCALE=zh-CN 变量,以改为中文界面。
#(3)登录 kibana 页面的时候,登录账户应该使用 elastic:pass,而非 kibana_system:pass。账户 kibana_system 是一个系统账户,在启动 Kibana 时,会用这个账户连接 Elasticsearch,以管理/操作 Elasticsearch 后台。例如:读取系统索引、管理索引模式、保存可视化对象等。
#(4)由于开启了安全验证,Filebeat 在连接时需要在 output 部分配置账户密码以及证书,如下:【注:证书获取位置:docker volume inspect elk-cluster_certs 输出目录的 ca 目录之下。】
output.elasticsearch:
hosts: ["localhost:9200"]
protocol: "https"
username: "elastic"
password: "elastic"
ssl.certificate_authorities: ["/etc/filebeat/ca.crt"]
原文地址: https://www.cveoy.top/t/topic/qGE3 著作权归作者所有。请勿转载和采集!