深度学习进阶(二十二)T5:NLP任务的首次大一统
上一篇我们完整展开了 Transformer-XL 的四项重构式 RPE,它通过把内容和位置分开建模,让位置信息真正参与到了注意力计算中。
但看完那个复杂的公式后,有这样一个问题:
为了位置信息,我们真的需要把自注意力拆成四项吗?
这并非无端质疑, 2020 年的论文: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 反其道而行之,提出了一种极简的偏置型 RPE ,成功让 RPE 进入了下一个阶段。
不过同样的是,论文并非专门提出这种 RPE,它的工作中心就是题目中的 T5,即 Text-to-Text Transfer Transformer,核心思想就是:
把分类、摘要、问答、翻译等一切 NLP 任务都塞进一个框架里:输入是文本,输出也是文本。
从地位和后续影响来说,T5 可以说是现代自然语言指令对话的起点,是对 NLP 任务形式的首次大一统,因此,本篇同样先展开 T5 本身的架构,再说明其 RPE 逻辑。
1. 如何训练统一模型?
如何统一训练统一模型?其实这部分内容就是整篇论文的核心思路,T5 将模型训练分为两部分:
- 使用 span corruption 的无监督预训练。
- 使用 task prefix 的监督多任务训练。
下面就来分点展开:
1.1 跨度破坏 Span Corruption
T5 本身的整体架构仍然是原始 Transformer 的编码-解码架构。
而这部分是模型的第一阶段训练,它使用 C4 数据集(一个包含数百亿个 token 的语料库)进行无监督预训练。
这里的关键词就是题目里的 Span Corruption,概括来说是这样的:
从输入序列中随机选取一些连续的 token 片段,替换为哨兵 token,以预测这些哨兵 token 为目标,训练整个模型的基础语言理解能力。
这部分其实和我们之前讲的 Word2Vec 的逻辑是类似的,只是前者训练的是词向量表,而现在我们训练的是整个模型的所有相关参数。
其实还有另外一个相关的概念是 BERT,它的想法是遮住单个 token 后判别恢复,而 T5 改为了遮住连续 token 生成恢复,等涉及到相关内容我们再展开。
拿一个英文句子举例:
"Thank you for inviting me to your party last week"
假设我们抹掉两个 span:
- "for inviting" →
- "last week" →
现在,模型的输入和标签其实在这样的:
输入:[替换 span 后的原句子] "Thank you me to your party "
目标输出:[<哨兵 token 序号>对应预测内容···<结束符>] " for inviting last week "
你会发现多了一个
按这种方式,使用海量数据进行训练后,模型便拥有了基础的语言理解能力。
但要注意,我们要的不是一个“填空模型”,这种做其实就是为了给模型的参数进行一个具备语言理解能力的初始化,所以才被称为“预训练”。
而下面这步,才是实现“统一”的逻辑。
1.2 任务前缀 task prefix
这部分其实是最好理解的部分,但也是实现 NLP 任务统一的最大前提:
给所有使用的数据加一个任务前缀,让 Transformer 架构按前缀生成对应类型的输出序列。
就像这样:
| 任务 | 传统做法 | T5 的做法 |
|---|---|---|
| 翻译 | Encoder-Decoder 架构,标准 Seq2Seq | 输入 translate English to German: ...,输出译文 |
| 摘要 | 专门的 Seq2Seq 模型 | 输入 summarize: ...,输出摘要 |
| 分类 | BERT + 分类头 | 输入 cola sentence: ...,输出 acceptable / unacceptable |
| 相似度 | 双塔 + 回归头 | 输入 stsb sentence1: ... sentence2: ...,输出 3.8 |
| 问答 | 专门的抽取式/生成式模型 | 输入 question: ... context: ...,输出答案 |
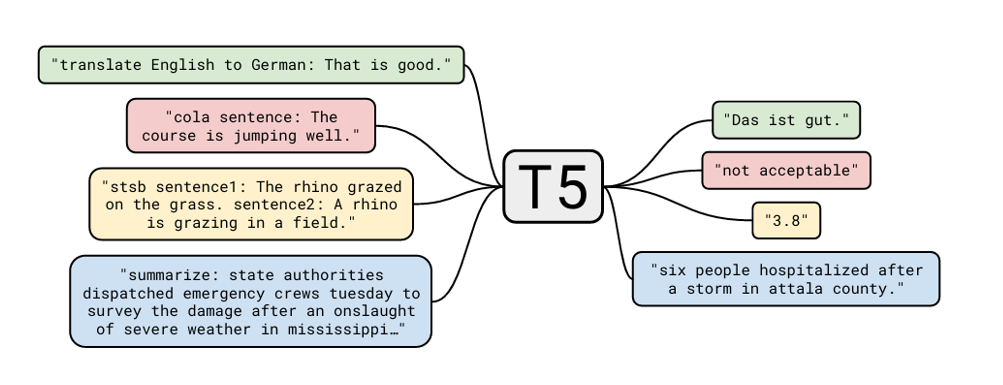
你会发现,这种设计就是把任务类型放到了输入序列中,通过大量数据让模型学习到相应的生成模式,实现把所有任务塞进 Seq2Seq 框架的逻辑。
这样,我们不再需要为每个任务单独写一个"输出头 → 损失函数"的代码了,整个训练流程只有一个入口,一个出口,使用统一的 Seq2Seq CrossEntropy 损失函数。
但显然,你也会发现相应的局限:
使用这样的数据格式训练,就一定要使用这样的格式推理,甚至真实应用。
所以,虽然可以通过预处理脚本完善相应的下游逻辑,但这种格式仍然有些僵硬,因此也指引了后续的改进方向。
从今天的视角看,Task Prefix 本质上已经是 Prompt Engineering 的早期雏形:任务本身被编码成自然语言输入,让模型通过上下文理解“现在应该做什么”。
2. Pre-LN 与去掉 LayerNorm 的偏置
看完了 T5 的核心框架和预训练,除去我们单独搁置的 RPE 逻辑外,T5 还有一处较小的改进度点,我们也简单展开一下:
2.1 Post-Norm 到 Pre-Norm 的回归
我们在 Transformer Block 那篇里中已经展开过 Post-Norm 和 Pre-Norm 了,T5 同样采用了 Pre-Norm,即 LayerNorm 放在残差之前:
这个选择并非 T5 首创,但它结合了另一个改动:
2.2 去掉 LayerNorm 的偏置 β
我们知道标准的 LayerNorm 公式是:
其中 γ 是可学习的缩放参数,β 是可学习的偏置参数。
现在,T5 把 β 砍掉了,只剩下 \(γ\):
T5 给的理由是这样的:
在 Pre-LN 的结构中,LayerNorm 后面的子层(Attention 或 FFN)本身已经带有偏置参数。LayerNorm 的 β 相当于提供了一个额外的、多余的平移,在深层网络中,这种额外平移未必带来收益,反而可能增加不必要的数值漂移。
其实这也是一种解耦的体现:LN 负责归一化,子层负责偏置,各干各的,不重叠。
这便是 T5 本身的核心逻辑。其实 T5 的研究团队之后又发表了新论文来改进 T5 ,除去一些工程优化外,其实重点在于对 MLP 子层的重构,这就是另一条较长的技术线了,我们之后再展开。
回到位置编码这条主线,下一篇我们就来展开 T5 在 RPE 上的极简方案:偏置型 RPE 和它的分桶策略。
原文地址: https://www.cveoy.top/t/topic/qGE1 著作权归作者所有。请勿转载和采集!