7、InputStream的源码、FilterInputStream源码、BufferedInputStream的源码(windows操作系统,JDK8)
阅读本文时,请先看我的另一篇博客:6、(InputStream的源码、FilterInputStream源码、BufferedInputStream的源码解读前言)AtomicReferenceFieldUpdater.class和System.arraycopy()函数的用法
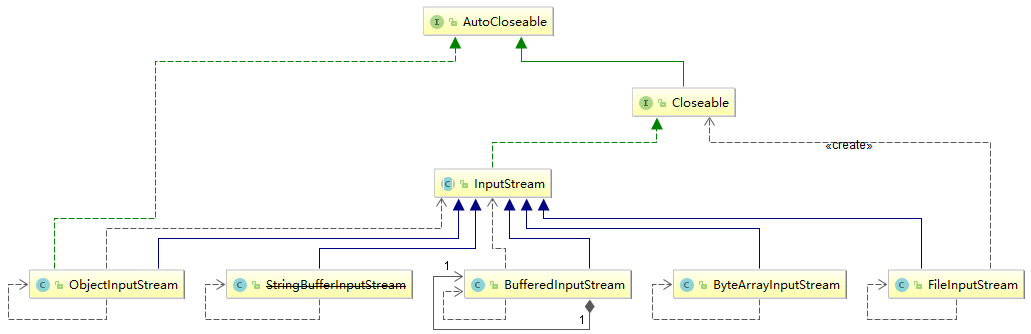
Java IO 库采用了装饰器模式(Decorator Pattern)和适配器模式(Adapter Pattern)的组合设计模式,其中InputStream是装饰器模式中顶层的抽象类,FilterInputStream是装饰器基类,BufferedInputStream是带有缓冲区的装饰器类,ObjectInputStream是可以读取对象的装饰器类,FileInputStream、ByteArrayInputStream则是被装饰的类。装饰器模式(Decorator Pattern)的详情,请查看我的另一篇blog四、装饰者模式
一、InputStream 源码
InputStream 是所有表示字节输入流类的父类。windows操作系统的JDK8版本中,所有的InputStream的子类如下(此处只展示部分):
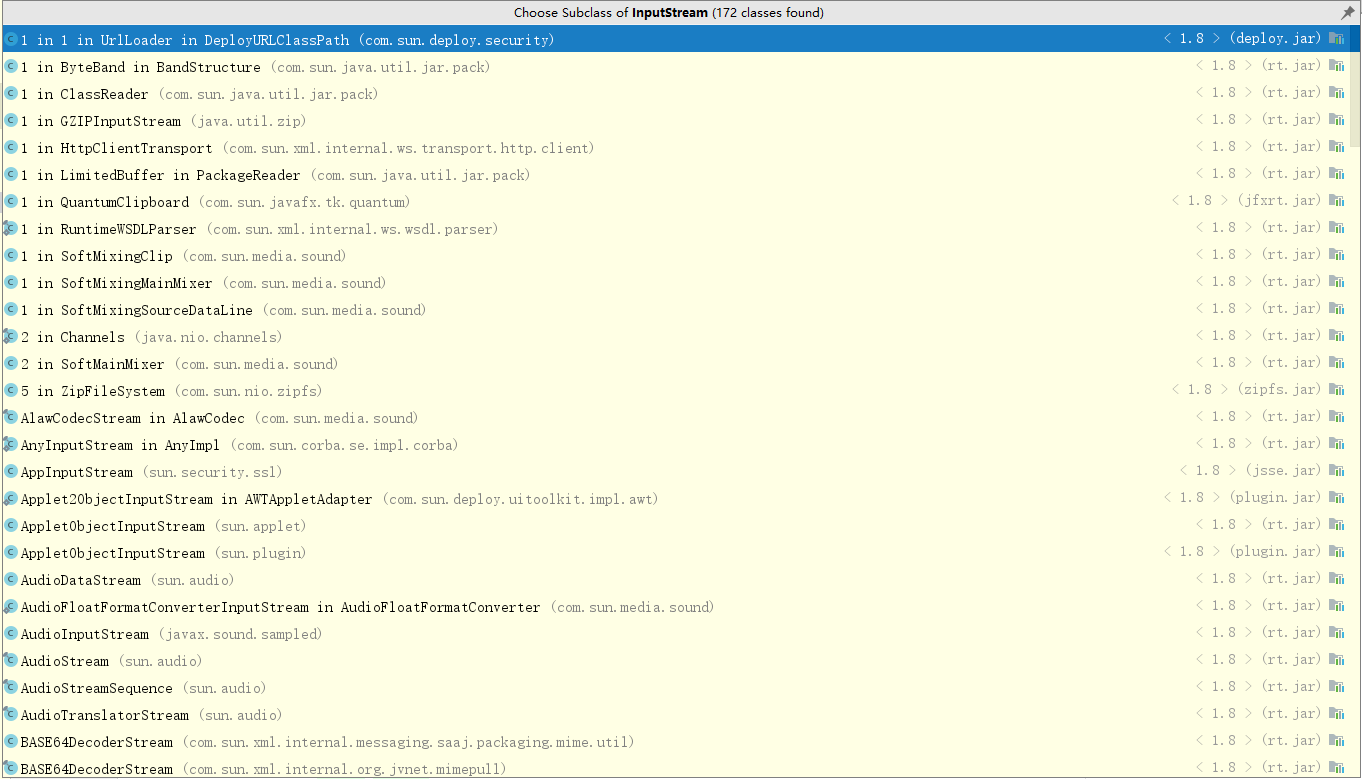
常用的InputStream子类有以下5个:
①、FileInputStream:处理文件的输入流。
②、ByteArrayInputStream :处理内存中byte[]数组的流式转换。
③、BufferedInputStream :带缓冲区的字节数组输入流,一般配合FileInputStream一起使用(缓冲区可以减少IO次数)。
④、ObjectInputStream:从流中读入一个自定义的对象。需要与ObjectOutputStream与配合使用,且按同样的顺序(写入的对象的顺序决定了读取对象的顺序)。
⑤、StringBufferInputStream:处理内存中String对象的流式转换。
以上5个子类的使用方式请参照:我的另一篇博客1、Java的IO概览(一)
InputStream.class的源码如下:
package java.io;
public abstract class InputStream implements Closeable {
// skip()函数中可以使用的最大缓冲区大小
private static final int MAX_SKIP_BUFFER_SIZE = 2048;
//留给子类实现,子类必须遵守以下规则:
//1、从输入的Stream中读取输入数据的下一个字节(ASCII码值),在读取到数据或者抛出异常前,这个函数是阻塞的。
//2、返回一个0 ~ 255 的 ASCII码值 。如果因为已经读到了Stream末尾而没有可用的字节,则返回值 -1。
public abstract int read() throws IOException;
//将从输入的Stream中读取的ASCII码值放入到byte[]数组中,0表示从byte[]数组的第0个索引开始,b.length表示一次性向byte[]数组中放入的ASCII码值的数量
//在读取到数据或者抛出异常前,这个函数是阻塞的。
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
//将从输入的Stream中读取的字节(ASCII码值)放入到byte[]数组中,off表示从byte[]数组的第off个索引开始,len表示一次性向byte[]数组中放入的字节(ASCII码值)的数量
//在读取到数据或者抛出异常前,这个函数是阻塞的。
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {//byte[]数组不能为空
throw new NullPointerException();
//范围检测,off和len必须是非负数,b.length - off是byte[]数组还可以放的字节(ASCII码值)的数量
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();//范围检查失败,抛出一个IndexOutOfBoundsException异常
} else if (len == 0) {//len=0,则直接返回0,该Stream可能有可读的字节(ASCII码值),也可能没有可读的字节(ASCII码值),但是本次不读任何数据。
return 0;
}
int c = read();//最终还是调用子类实现的read()函数
if (c == -1) {//read()函数规定了,返回值-1表示已经读到了Stream末尾而没有可用的字节(ASCII码值)
return -1;//如果一开始就读到了Stream末尾而没有可用的字节(ASCII码值),则直接返回-1
}
b[off] = (byte)c;//如果一开始从Stream中可以读到字节(ASCII码值),则将读到的第1个字节(ASCII码值)值放入byte[]数组的第off个索引位置
//如果从Stream中读到了第1个字节(ASCII码值),则接着从Stream中读后面的字节(ASCII码值)
int i = 1;
try {
for (; i < len ; i++) {
c = read();//最终还是调用子类实现的read()函数
if (c == -1) {
break;//读不到,结束循环
}
b[off + i] = (byte)c;//每次从Stream中读到的字节(ASCII码值)都放到byte[]数组的第off个索引位置之后
}
} catch (IOException ee) {
}
return i;//返回从Stream中读到的字节数量
}
//将从输入的Stream中跳过n个字节
public long skip(long n) throws IOException {
//还没(或者还需要)跳过的字节(ASCII码值)的总数量
long remaining = n;
int nr;
//校验,如果n<=0,则返回0
if (n <= 0) {
return 0;
}
//每次跳过的字节(ASCII码值)最多为2048个
int size = (int)Math.min(MAX_SKIP_BUFFER_SIZE, remaining);
//用于每次跳过指定数量字节(每次最多为2048个)的数组
byte[] skipBuffer = new byte[size];
while (remaining > 0) {//还需要跳过的字节(ASCII码值)数量<=0时,跳出循环
//调用read(byte b[], int off, int len)函数,该函数在上面已经分析过,该函数的返回值有3种,含义如下:
//①、返回值=-1,表示该Stream没有可读的字节
//②、返回值=0,表示该Stream可能有可读的字节(ASCII码值),也可能没有可读的字节(ASCII码值),但是本次传入的Math.min(size, remaining)为0,不从Stream中读任何数据,此处的Math.min(size, remaining)不可能为0
//③、返回值>0,表示从该Stream中读到的字节(ASCII码值)的数量
nr = read(skipBuffer, 0, (int)Math.min(size, remaining));
if (nr < 0) {
break;//该Stream中没有可读的字节时,nr=-1,跳出循环
}
remaining -= nr;//表示还需要跳过的字节(ASCII码值)数量
}
return n - remaining;//返回已经跳过的字节(ASCII码值)的总数量
}
//返回这个Stream中还可以读取的字节的总数量,JDK不建议将这个函数的返回值作为缓冲区的长度来从Stream中读取数据(子类一般会覆盖这个函数)
public int available() throws IOException {
return 0;
}
//留给子类实现,子类必须遵守以下规则:
//关闭Stream,并释放与该流相关的系统资源
public void close() throws IOException {}
//标记此Stream中的当前位置。随后调用reset()函数会将此流重新定位到上次标记的位置,从而使得后续的读取操作能够再次读取相同的字节。
//带有回退功能的InputStream的子类会重写这个函数,但是FileInputStream不会重写这个函数,也就意味着,FileInputStream不支持回退功能
public synchronized void mark(int readlimit) {}
//reset()函数会将此流重新定位到上次标记的位置,从而使得后续的读取操作能够再次读取相同的字节。
//带有回退功能的InputStream的子类会重写这个函数,但是FileInputStream不会重写这个函数,也就意味着,FileInputStream不支持回退功能
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
//如果InputStream的子类支持mark()函数和 reset()函数,则返回true,否则,返回false(InputStream的子类不支持mark()函数和 reset()函数)。
public boolean markSupported() {
return false;
}
}
1.1、InputStream的skip()函数
public long skip(long n) throws IOException {
//还没(或者还需要)跳过的字节(ASCII码值)的总数量
long remaining = n;
int nr;
//校验,如果n<=0,则返回0
if (n <= 0) {
return 0;
}
//每次跳过的字节(ASCII码值)最多为2048个
int size = (int)Math.min(MAX_SKIP_BUFFER_SIZE, remaining);
//用于每次跳过指定数量字节(每次最多为2048个)的数组
byte[] skipBuffer = new byte[size];
while (remaining > 0) {//还需要跳过的字节(ASCII码值)数量<=0时,跳出循环
//调用read(byte b[], int off, int len)函数,该函数在上面已经分析过,该函数的返回值有3种,含义如下:
//①、返回值=-1,表示该Stream没有可读的字节
//②、返回值=0,表示该Stream可能有可读的字节(ASCII码值),也可能没有可读的字节(ASCII码值),但是本次传入的Math.min(size, remaining)为0,不从Stream中读任何数据,此处的Math.min(size, remaining)不可能为0
//③、返回值>0,表示从该Stream中读到的字节(ASCII码值)的数量
nr = read(skipBuffer, 0, (int)Math.min(size, remaining));
if (nr < 0) {
break;//该Stream中没有可读的字节时,nr=-1,跳出循环
}
remaining -= nr;//表示还需要跳过的字节(ASCII码值)数量
}
return n - remaining;//返回已经跳过的字节(ASCII码值)的总数量
}
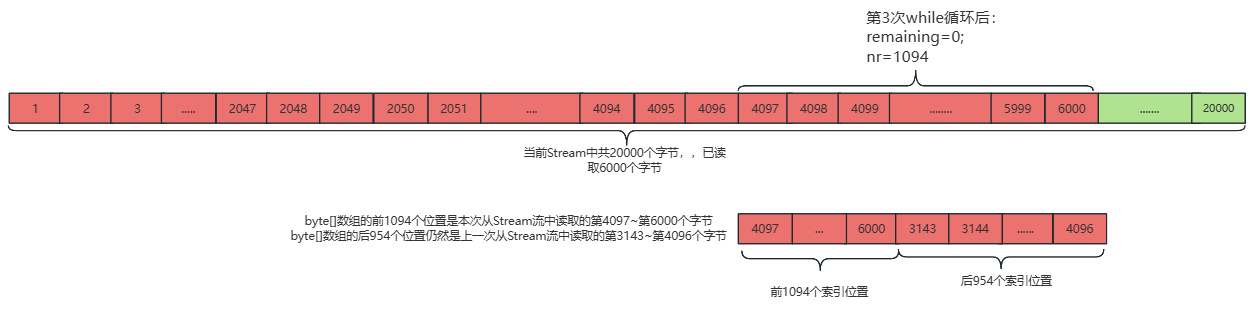
如果要从一个20000个字节的Stream中跳过6000个字节,只需要调用skip(6000)即可,该函数的执行过程分为以下4步:
①、while循环之前进行初始化byte[]数组和零时变量的操作

②、第1次while循环之后,已经从前Stream中读取了2048个字节

③、第2次while循环之后,已经从前Stream中读取了4096个字节

④、第3次while循环之后,已经从前Stream中读取了6000个字节,读取完毕,byte[]数组的前1094个位置是本次从Stream流中读取的第4097第6000个字节,byte[]数组的后954个位置仍然是上一次从Stream流中读取的第3143第4096个字节
二、FilterInputStream 源码——装饰器基类
FilterInputStream 的UML关系图,如下所示:
FilterInputStream.class的源码,如下所示:
package java.io;
public
class FilterInputStream extends InputStream {
//用来组合了一个 被装饰者的变量,被修饰为volatile 有以下3个原因:
// 1. 确保多线程环境下修改的可见性
// 2. 有些装饰器允许运行时替换底层流
// 3. 防止指令重排序导致的初始化问题
protected volatile InputStream in;
//创建时传入一个 被装饰者
protected FilterInputStream(InputStream in) {
this.in = in;
}
//调用被装饰者的read()函数
public int read() throws IOException {
return in.read();
}
//调用被装饰者的read(byte b[]) 函数
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
//调用被装饰者的read(byte b[], int off, int len)函数
public int read(byte b[], int off, int len) throws IOException {
return in.read(b, off, len);
}
//调用被装饰者的skip()函数
public long skip(long n) throws IOException {
return in.skip(n);
}
//调用被装饰者的available()函数
public int available() throws IOException {
return in.available();
}
//调用被装饰者的close()函数
public void close() throws IOException {
in.close();
}
//调用被装饰者的mark()函数
public synchronized void mark(int readlimit) {
in.mark(readlimit);
}
//调用被装饰者的reset()函数
public synchronized void reset() throws IOException {
in.reset();
}
//调用被装饰者的markSupported()函数
public boolean markSupported() {
return in.markSupported();
}
}
三、BufferedInputStream 源码——带有缓冲区的装饰器类
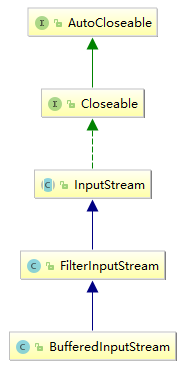
BufferedInputStream.class 的UML关系图,如下所示:
BufferedInputStream.class的源码,如下所示:
package java.io;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;
public
class BufferedInputStream extends FilterInputStream {
// 默认缓冲区(byte[]数组)大小为8192 字节(8KB)
private static int DEFAULT_BUFFER_SIZE = 8192;
// 最大缓冲区(byte[]数组)大小为2147483639byte,大约2GB左右
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
//缓冲区数组,用volatile修饰是为了通过AtomicReferenceFieldUpdater进行CAS更新时保证内存的可见性
protected volatile byte buf[];
//底层是通过反射找到目标字段的内存偏移量,然后利用Unsafe.class提供的CAS(Compare-And-Swap)操作来原子地更新某个类中指定变量的值
private static final
AtomicReferenceFieldUpdater bufUpdater =
AtomicReferenceFieldUpdater.newUpdater
(BufferedInputStream.class, byte[].class, "buf");
//缓冲区(byte[]数组)中有效字的节数数量
protected int count;
//准备从缓冲区中(byte[]数组)读取的字节索引位置,取值范围为0<=pos<=count
protected int pos;
//在缓冲区(byte[]数组)中标记的某个索引位置,-1<=markpos<=pos
//该变量只会在 fill()函数和mark()函数中赋值
protected int markpos = -1;
// 标记后最多可读取字节数量,该变量只会在 mark()函数中赋值
//每当pos-markpos>marklimit时,就会设置markpos=-1 来删除标记
protected int marklimit;
//如果被装饰的输入流不为空,则返回被装饰的输入Stream(该变量在FilterInputStream中定义)
private InputStream getInIfOpen() throws IOException {
InputStream input = in;
if (input == null)
throw new IOException("Stream closed");
return input;
}
//如果缓冲区(byte[]数组)不为空,则返回该缓冲区(byte[]数组),否则抛出异常
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
}
//构造函数,需要传入一个被装饰的输入Stream, 缓冲区(byte[]数组)的长度是8192 (默认值,8KB)
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
//构造函数,需要传入一个被装饰的输入Stream和缓冲区(byte[]数组)的长度
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {//校验,缓冲区(byte[]数组)的长度必须>0
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();//获取缓冲区(byte[]数组)
if (markpos < 0)//如果还没有调用过mark()函数,那么markpos=-1
pos = 0;//pos=0,可以从缓冲区(byte[]数组)的索引0的位置开始读字节了
else if (pos >= buffer.length)
if (markpos > 0) { //场景一:pos>=缓冲区(byte[]数组)的长度并且markpos >0
int sz = pos - markpos;
//只把缓冲区(byte[]数组)中[markpos,pos) 索引区间的元素复制到缓冲区(byte[]数组)[0,pos-markpos)索引区间
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;//设置pos=pos-markpos
markpos = 0;//设置markpos=0
} else if (buffer.length >= marklimit) {//场景二:pos>=缓冲区(byte[]数组)的长度并且缓冲区(byte[]数组)的长度>= marklimit
markpos = -1; //设置markpos = -1
pos = 0; //设置pos = 0
} else if (buffer.length >= MAX_BUFFER_SIZE) {//场景三:pos>=缓冲区(byte[]数组)的长度并且缓冲区(byte[]数组)的长度 >= 2147483639
throw new OutOfMemoryError("Required array size too large");
} else {//场景四:pos>=缓冲区(byte[]数组)的长度并且不满足场景一、二、三时,将缓冲区(byte[]数组)扩容
//如果pos<2147483639/2,则新缓冲区(byte[]数组)的长度nsz=pos*2,否则新缓冲区(byte[]数组)的长度nsz=2147483639
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;//当新缓冲区(byte[]数组)的长度nsz>marklimit,新缓冲区(byte[]数组)的长度nsz=marklimit
byte nbuf[] = new byte[nsz];//新建一个新缓冲区(byte[]数组)
System.arraycopy(buffer, 0, nbuf, 0, pos);//将老缓冲区(byte[]数组)中[0,pos)索引区间的元素复制到新缓冲区(byte[]数组)[0,pos)索引区间
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {//通过CAS(Compare-And-Swap)操作来原子地更新buf变量
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;//新缓冲区(byte[]数组)创建完毕
}
count = pos;
//将被装饰的输入Stream中的字节读取到缓冲区(byte[]数组)的[pos,buffer.length - pos)索引位置,并返回读取的字节数量
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;//count=从被装饰的输入Stream中读取的字节数量+pos
}
//线程同步的函数:从缓冲区(byte[]数组)中读取1个字节
public synchronized int read() throws IOException {
//pos=count有2种情况(pos不可能>count):
//场景一:pos=count=0,缓冲区(byte[]数组)还没有填充任何数据。
//场景二:pos=count≠0,缓冲区(byte[]数组)中的数据已经通过pos读取完了。
if (pos >= count) {
fill();//符合场景一或场景二都会调用fill()函数
if (pos >= count)
return -1;//如果调用了fill()函数后,仍然符合场景一或场景二,表示被装饰的输入Stream已经读完了,返回-1
}
//执行到这里时,表明pos < count,返回缓冲区(byte[]数组)pos索引位置的字节;
return getBufIfOpen()[pos++] & 0xff;
}
//从缓冲区(byte[]数组)或被装饰的输入Stream中读取len个字节到指定的byte[]数组b中,这len个字节被放到byte[]数组b的[off,off+len)索引位置。
//该函数只被read()函数调用
private int read1(byte[] b, int off, int len) throws IOException {
//只在fill()函数中修改count变量的值,count变量的值只有以下2种可能
//①、count==pos;②、count=从被装饰的输入Stream中读取的字节数量+pos
//因此avail表示缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量
int avail = count - pos;
if (avail <= 0) {//缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量<=0(其实不可能<0,只可能=0)
//要读取的len个字节>=缓冲区(byte[]数组)的长度,同时markpos = -1
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);//从被装饰的输入Stream中读取len个字节到指定的byte[]数组b中,这len个字节被放到byte[]数组b的[off,off+len)索引位置。
}
fill();//调用fill()函数
avail = count - pos;//重新计算avail
if (avail <= 0) return -1;//如果avail仍然=0,返回-1
}
int cnt = (avail < len) ? avail : len;//此时avail>0,取avail和len中较小的值作为本次从缓冲区(byte[]数组)中读取的字节数量
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);//从缓冲区(byte[]数组)的pos索引开始,读取avail或len(2者取其小)个字节到指定的byte[]数组b的[off,off+cnt)索引位置(cnt就是avail或len中2者取其小的值)
pos += cnt;//pos向前移动avail或len(2者取其小)个索引位置
return cnt;//返回avail或len(2者取其小)
}
//线程同步的函数:从缓冲区(byte[]数组)中读取len个字节到指定的byte[]数组b中,这len个字节被放到byte[]数组b的[off,off+len)索引位置。
public synchronized int read(byte b[], int off, int len)
throws IOException
{
getBufIfOpen(); //检测被装饰的输入Stream是否关闭
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {//相当于off + len > b.length(这样写代码的好处我没看出来)
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;//要从缓冲区(byte[]数组)中读取的len个字节==0时,返回0
}
int n = 0;//累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量
for (;;) {//循环调用read1()函数完成从缓冲区(byte[]数组)或被装饰的输入Stream中读取len个字节到指定的byte[]数组b中,这len个字节被放到byte[]数组b的[off,off+len)索引位置。
int nread = read1(b, off + n, len - n);//nread用来统计每次从read1()函数中读取一定的字节数量,并放到byte[]数组b的[off,off+len)索引位置。
if (nread <= 0)
return (n == 0) ? nread : n;//当read1()函数返回0或者-1时,表示缓冲区(byte[]数组)中和被装饰的输入Stream中已经没有可以读取的字节了
n += nread;//累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量
if (n >= len)//累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量总和>=len时(其实不可能>len,只可能=len)
return n;//返回n
// 被装饰的输入Stream中已经没有字节可以用了,返回累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量总和
InputStream input = in;
if (input != null && input.available() <= 0)
return n;
}
}
//线程同步的函数:从缓冲区(byte[]数组)中跳过了n个字节
public synchronized long skip(long n) throws IOException {
getBufIfOpen(); //检测被装饰的输入Stream是否关闭
if (n <= 0) {
return 0;
}
//只在fill()函数中修改count变量的值,count变量的值只有以下2种可能
//①、count==pos;②、count=从被装饰的输入Stream中读取的字节数量+pos
//因此avail表示缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量
long avail = count - pos;
if (avail <= 0) {//缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量<=0(其实不可能<0,只可能=0)
// If no mark position set then don't keep in buffer
if (markpos <0)//同时markpos<0
return getInIfOpen().skip(n);//调用被装饰的输入Stream的skip()函数
// Fill in buffer to save bytes for reset
fill();//调用fill()函数(跟read1()函数中的操作一样)
avail = count - pos;//重新计算avail(跟read1()函数中的操作一样)
if (avail <= 0)
return 0;//如果avail仍然=0,返回-1
}
long skipped = (avail < n) ? avail : n;//此时avail>0,取avail和n中较小的值作为本次从缓冲区(byte[]数组)中跳过的字节数量
pos += skipped;//pos向前移动avail或n(2者取其小)个索引位置(与read1()函数异曲同工),表示本次从缓冲区(byte[]数组)中跳过了skipped个字节
return skipped;//返回本次从缓冲区(byte[]数组)中跳过的skipped个字节
}
//线程同步的函数:计算缓冲区(byte[]数组)的最大长度(或者叫容量)
public synchronized int available() throws IOException {
//只在fill()函数中修改count变量的值,count变量的值只有以下2种可能
//①、count==pos;②、count=从被装饰的输入Stream中读取的字节数量+pos
//因此count - pos表示缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量
int n = count - pos;
int avail = getInIfOpen().available();//调用被装饰的输入Stream的available()函数,返回被装饰的输入Stream中仍然可以读取的字节数量
return n > (Integer.MAX_VALUE - avail)//(缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量 + 被装饰的输入Stream中仍然可以读取的字节数量) > 2147483647时,返回2147483647,表示缓冲区(byte[]数组)的最大容量为2147483647
? Integer.MAX_VALUE
: n + avail;//返回(缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量 + 被装饰的输入Stream中仍然可以读取的字节数量),表示缓冲区(byte[]数组)的最大容量为该数量
}
//线程同步的函数:给marklimit和 markpos赋值(或者叫标记 marklimit和 markpos)
public synchronized void mark(int readlimit) {
marklimit = readlimit;
markpos = pos;
}
//线程同步的函数:pos = markpos(或者叫对齐pos索引位置 到markpos索引位置)
public synchronized void reset() throws IOException {
getBufIfOpen(); //检测被装饰的输入Stream是否关闭
if (markpos < 0)
throw new IOException("Resetting to invalid mark");
pos = markpos;
}
//返回当前这个class是否支持mark()函数和 reset()函数
public boolean markSupported() {
return true;
}
//关闭被装饰的输入Stream,释放缓冲区(byte[]数组),让gc回收。
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) {
InputStream input = in;
in = null;
if (input != null)
input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}
}
3.1、BufferedInputStream的read()函数和fill()函数
public
class BufferedInputStream extends FilterInputStream {
...省略部分代码...
// 默认缓冲区(byte[]数组)大小为8192 字节(8KB)
private static int DEFAULT_BUFFER_SIZE = 8192;
// 最大缓冲区(byte[]数组)大小为2147483639byte,大约2GB左右
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
//缓冲区数组,用volatile修饰是为了通过AtomicReferenceFieldUpdater进行CAS更新时保证内存的可见性
protected volatile byte buf[];
//底层是通过反射找到目标字段的内存偏移量,然后利用Unsafe.class提供的CAS(Compare-And-Swap)操作来原子地更新某个类中指定变量的值
private static final
AtomicReferenceFieldUpdater bufUpdater =
AtomicReferenceFieldUpdater.newUpdater
(BufferedInputStream.class, byte[].class, "buf");
//缓冲区(byte[]数组)中有效字的节数数量
protected int count;
//准备从缓冲区中(byte[]数组)读取的字节索引位置,取值范围为0<=pos<=count
protected int pos;
//在缓冲区(byte[]数组)中标记的某个索引位置,-1<=markpos<=pos
//该变量只会在 fill()函数和mark()函数中赋值
protected int markpos = -1;
// 标记后最多可读取字节数量,该变量只会在 mark()函数中赋值
//每当pos-markpos>marklimit时,就会设置markpos=-1 来删除标记
protected int marklimit;
//如果缓冲区(byte[]数组)不为空,则返回该缓冲区(byte[]数组),否则抛出异常
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
}
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();//获取缓冲区(byte[]数组)
if (markpos < 0)//如果还没有调用过mark()函数,那么markpos=-1
pos = 0;//pos=0,可以从缓冲区(byte[]数组)的索引0的位置开始读字节了
else if (pos >= buffer.length)
if (markpos > 0) { //场景一:pos>=缓冲区(byte[]数组)的长度并且markpos >0
int sz = pos - markpos;
//只把缓冲区(byte[]数组)中[markpos,pos) 索引区间的元素复制到缓冲区(byte[]数组)[0,pos-markpos)索引区间
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;//设置pos=pos-markpos
markpos = 0;//设置markpos=0
} else if (buffer.length >= marklimit) {//场景二:pos>=缓冲区(byte[]数组)的长度并且缓冲区(byte[]数组)的长度>= marklimit
markpos = -1; //设置markpos = -1
pos = 0; //设置pos = 0
} else if (buffer.length >= MAX_BUFFER_SIZE) {//场景三:pos>=缓冲区(byte[]数组)的长度并且缓冲区(byte[]数组)的长度 >= 2147483639
throw new OutOfMemoryError("Required array size too large");
} else {//场景四:pos>=缓冲区(byte[]数组)的长度并且不满足场景一、二、三时,将缓冲区(byte[]数组)扩容
//如果pos<2147483639/2,则新缓冲区(byte[]数组)的长度nsz=pos*2,否则新缓冲区(byte[]数组)的长度nsz=2147483639
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;//当新缓冲区(byte[]数组)的长度nsz>marklimit,新缓冲区(byte[]数组)的长度nsz=marklimit
byte nbuf[] = new byte[nsz];//新建一个新缓冲区(byte[]数组)
System.arraycopy(buffer, 0, nbuf, 0, pos);//将老缓冲区(byte[]数组)中[0,pos)索引区间的元素复制到新缓冲区(byte[]数组)[0,pos)索引区间
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {//通过CAS(Compare-And-Swap)操作来原子地更新buf变量
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;//新缓冲区(byte[]数组)创建完毕
}
count = pos;
//将被装饰的输入Stream中的字节读取到缓冲区(byte[]数组)的[pos,buffer.length - pos)索引位置,并返回读取的字节数量
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;//count=从被装饰的输入Stream中读取的字节数量+pos
}
//线程同步的函数:从缓冲区(byte[]数组)中读取1个字节
public synchronized int read() throws IOException {
//pos=count有2种情况(pos不可能>count):
//场景一:pos=count=0,缓冲区(byte[]数组)还没有填充任何数据。
//场景二:pos=count≠0,缓冲区(byte[]数组)中的数据已经通过pos读取完了。
if (pos >= count) {
fill();//符合场景一或场景二都会调用fill()函数
if (pos >= count)
return -1;//如果调用了fill()函数后,仍然符合场景一或场景二,表示被装饰的输入Stream已经读完了,返回-1
}
//执行到这里时,表明pos < count,返回缓冲区(byte[]数组)pos索引位置的字节;
return getBufIfOpen()[pos++] & 0xff;
}
...省略部分代码...
}
如果使用者用的是默认的构造函数创建了BufferedInputStream的对象,如下所示(伪代码):
InputStream is = new FileInputStream("D:\\nio-data.txt");
BufferedInputStream bis = new BufferedInputStream(is);
那么,BufferedInputStream对象中的缓冲区(byte[]数组)的长度为8192(缓存8KB字节),如果此时执行BufferedInputStream.class::read()函数,
bis.read();
过程如下(假设被装饰的输入Stream(FileInputStream)中有10000个字节):
①、pos=count=0,缓冲区(byte[]数组)中还没有填充任何数据,执行fill()函数,然后将被装饰的输入Stream(FileInputStream)中的字节读取到缓冲区(byte[]数组)的[0,8192)索引位置(左闭右开,不包括byte[]数组的第8192个索引位置),并返回读取的字节数量。如下所示:
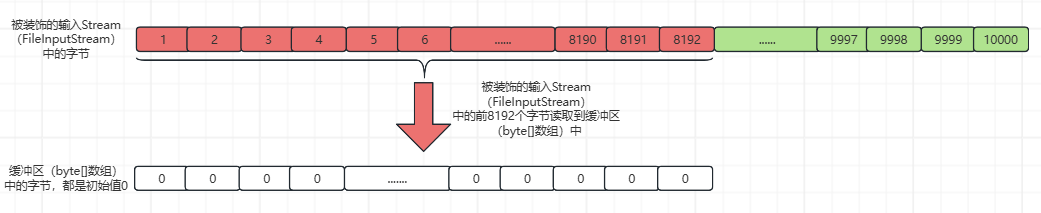
此时,被装饰的输入Stream(FileInputStream)中的字节和缓冲区(byte[]数组)中的字节,如下所示:
②、更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为8192,count=8192+pos=8192;
③、执行getBufIfOpen()[pos++] & 0xff,从缓冲区(byte[]数组)中获取第pos(此时pos=0)个索引位置的字节,返回给BufferedInputStream.class::read()函数的调用方,并更新pos的值为pos+=1;
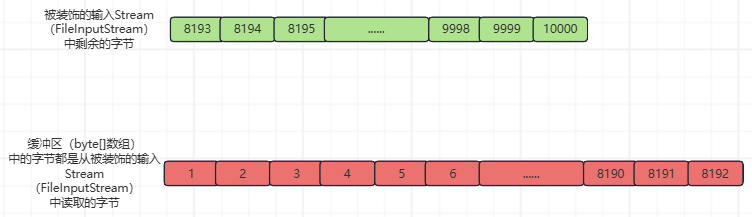
之后,每次调用BufferedInputStream.class::read()函数时,都不会再执行fill()函数了,直到pos=8192时,执行BufferedInputStream.class::read()函数才会再次执行fill()函数,新的填充缓冲区(byte[]数组)的过程如下:
①、更新pos=0,count=0,缓冲区(byte[]数组)中是上一次执行fill()函数填充的从被装饰的输入Stream(FileInputStream)读取的第18192个字节,本次,需要将被装饰的输入Stream(FileInputStream)中的第819310000个字节读取到缓冲区(byte[]数组)的[0,1808)索引位置(左闭右开,不包括byte[]数组的第1808个索引位置),并返回读取的字节数量。如下所示:
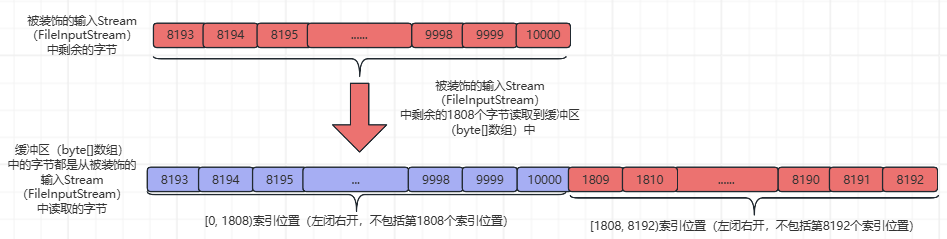
此时,被装饰的输入Stream(FileInputStream)中的字节被全部读取完毕,被装饰的输入Stream(FileInputStream)为空。
②、更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为1808,count=1808+pos=1808;
③、执行getBufIfOpen()[pos++] & 0xff,从缓冲区(byte[]数组)中获取第pos(此时pos=0)个索引位置的字节,返回给BufferedInputStream.class::read()函数的调用方,并更新pos的值为pos+=1;
之后,每次调用BufferedInputStream.class::read()函数时,都不会再执行fill()函数了,直到pos=1808时,执行BufferedInputStream.class::read()函数才会再次执行fill()函数,过程如下:
①、更新pos=0,count=0,缓冲区(byte[]数组)中的数据如下:

此时,由于被装饰的输入Stream(FileInputStream)中的字节被全部读取完毕,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为0,无法更新count,结束fill()函数的调用
②、执行return -1,返回给BufferedInputStream.class::read()函数的调用方;
3.1.1、如果在多次执行BufferedInputStream.class::read()函数之前执行过mark()函数
标题3.1分析了很多次只调用read()函数之后,最后缓冲区(byte[]数组)中的字节内容,并没有分析很多次调用read()函数之前,很多次调用read()函数之中,很多次调用read()函数之后分别调用了mark()函数和reset()函数的场景。
如果在很多次调用read()函数之前调用了mark(8192)函数,如下(伪代码):
InputStream is = new FileInputStream("D:\\nio-data.txt");
BufferedInputStream bis = new BufferedInputStream(is);
bis.mark(8192);//设置marklimit=8192,markpos=pos=0
int bytesRead;
while ((bytesRead = bis.read()) != -1) {
//处理读取到的字节bytesRead
}
那么,BufferedInputStream对象中的缓冲区(byte[]数组)的长度为8192(缓存8KB字节),如果此时,如上述代码一样在,while循环中执行BufferedInputStream.class::read()函数,过程如下(假设被装饰的输入Stream(FileInputStream)中有10000个字节):
①、pos=count=0,缓冲区(byte[]数组)中还没有填充任何数据,执行fill()函数,然后将被装饰的输入Stream(FileInputStream)中的字节读取到缓冲区(byte[]数组)的[0,8192)索引位置(左闭右开,不包括byte[]数组的第8192个索引位置),并返回读取的字节数量。如下所示:
此时,被装饰的输入Stream(FileInputStream)中的字节和缓冲区(byte[]数组)中的字节,如下所示:
②、更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为8192,count=8192+pos=8192;
③、执行getBufIfOpen()[pos++] & 0xff,从缓冲区(byte[]数组)中获取第pos(此时pos=0)个索引位置的字节,返回给BufferedInputStream.class::read()函数的调用方,并更新pos的值为pos+=1;
之后,每次调用BufferedInputStream.class::read()函数时,都不会再执行fill()函数了,直到pos=8192时,执行BufferedInputStream.class::read()函数才会再次执行fill()函数,新的填充缓冲区(byte[]数组)的过程如下:
①、此时,因为buffer.length >= marklimit,所以,更新markpos=-1,pos=0;
后续的步骤与标题3.1相同。最终缓冲区(byte[]数组)中的数据如下:
最终,pos=0,count=0,markpos=-1
3.1.2、如果在多次执行BufferedInputStream.class::read()函数之中执行过mark()函数
如果在很多次调用read()函数之中调用了mark(8192)函数,如下(伪代码):
InputStream is = new FileInputStream("D:\\nio-data.txt");
BufferedInputStream bis = new BufferedInputStream(is);
int bytesRead;
int i = 0;
while ((bytesRead = bis.read()) != -1) {
if(++i==4096){
bis.mark(8192);//设置marklimit=8192,markpos=pos=4096
}
//处理读取到的字节bytesRead
}
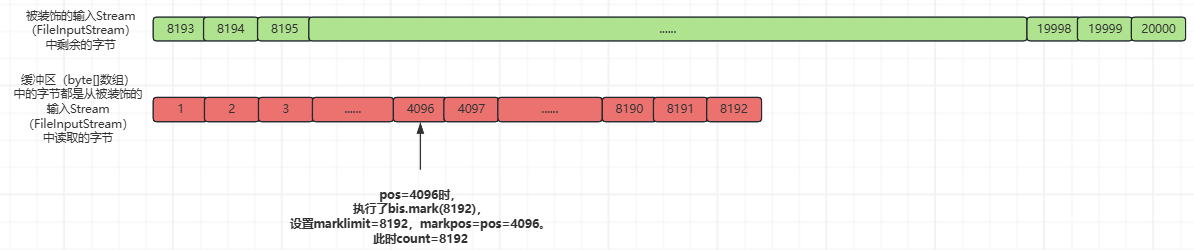
那么,BufferedInputStream对象中的缓冲区(byte[]数组)的长度为8192(缓存8KB字节),上述代码的执行过程如下(假设被装饰的输入Stream(FileInputStream)中有20000个字节):
①、pos=count=0,缓冲区(byte[]数组)中还没有填充任何数据,执行fill()函数,然后将被装饰的输入Stream(FileInputStream)中的字节读取到缓冲区(byte[]数组)的[0,8192)索引位置(左闭右开,不包括byte[]数组的第8192个索引位置),并返回读取的字节数量。如下所示:

此时,被装饰的输入Stream(FileInputStream)中的字节和缓冲区(byte[]数组)中的字节,如下所示:

②、更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为8192,count=8192+pos=8192;
③、执行getBufIfOpen()[pos++] & 0xff,从缓冲区(byte[]数组)中获取第pos(此时pos=0)个索引位置的字节,返回给BufferedInputStream.class::read()函数的调用方,并更新pos的值为pos+=1;
之后,每次调用BufferedInputStream.class::read()函数时,都不会再执行fill()函数了,并且当pos=4096时,执行了bis.mark(8192),设置marklimit=8192,markpos=pos=4096。
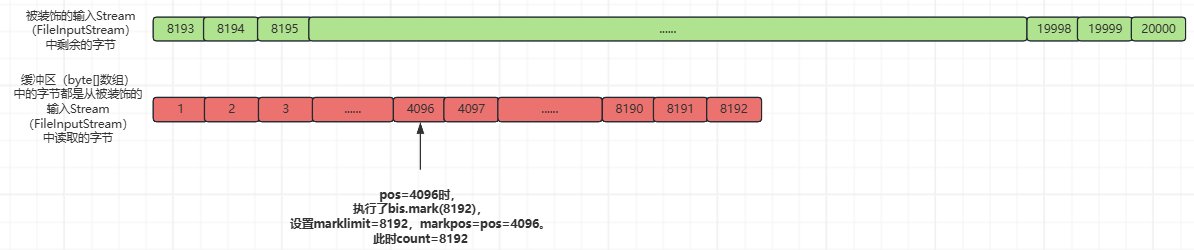
直到pos=8192时,执行BufferedInputStream.class::read()函数才会再次执行fill()函数,本次填充缓冲区(byte[]数组)的过程如下:
①、执行fill()函数的如下代码片段(标题3.1.4也会复用之后的逻辑)
...省略部分代码...
else if (pos >= buffer.length)
if (markpos > 0) { //场景一:pos>=缓冲区(byte[]数组)的长度并且markpos >0
int sz = pos - markpos;
//只把缓冲区(byte[]数组)中[markpos,pos) 索引区间的元素复制到缓冲区(byte[]数组)[0,pos-markpos)索引区间
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;//设置pos=pos-markpos
markpos = 0;//设置markpos=0
}
...省略部分代码...
先把缓冲区(byte[]数组)中[4096,8192) 索引区间的元素复制到缓冲区(byte[]数组)[0,4096)索引区间,如下所示:

再更新pos=4096,markpos = 0;
②、然后从被装饰的输入Stream(FileInputStream)读取第8193~12286个字节到缓冲区(byte[]数组)的[4096,8192)索引位置(左闭右开,不包括byte[]数组的第8192个索引位置),并返回读取的字节数量。如下所示:
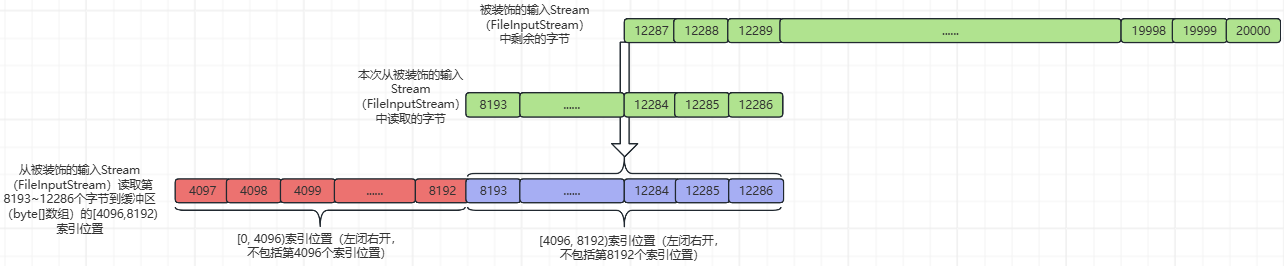
然后更新count,此时count = n + pos=4096+4096=8192,pos=4096,markpos = 0
③、执行getBufIfOpen()[pos++] & 0xff,从缓冲区(byte[]数组)中获取第pos(此时pos=4096)个索引位置的字节,返回给BufferedInputStream.class::read()函数的调用方,并更新pos的值为pos+=1;
之后,每次调用BufferedInputStream.class::read()函数时,都不会再执行fill()函数了,直到pos=8192时(此时,count = 8192,markpos=0),执行BufferedInputStream.class::read()函数才会再次执行fill()函数,后续过程分为以下2种情景:
- 情景一,如上伪代码bis.mark(8192),设置marklimit=8192<=缓冲区(byte[]数组)的长度
①、执行fill()函数的如下代码片段:
...省略部分代码...
} else if (buffer.length >= marklimit) {//场景二:pos>=缓冲区(byte[]数组)的长度并且缓冲区(byte[]数组)的长度>= marklimit
markpos = -1; //设置markpos = -1
pos = 0; //设置pos = 0
}
...省略部分代码...
先更新pos = 0,markpos = -1;然后从被装饰的输入Stream(FileInputStream)读取第12287~20000个字节到缓冲区(byte[]数组)的[0,7914)索引位置(左闭右开,不包括byte[]数组的第7914个索引位置),并返回读取的字节数量。如下所示:
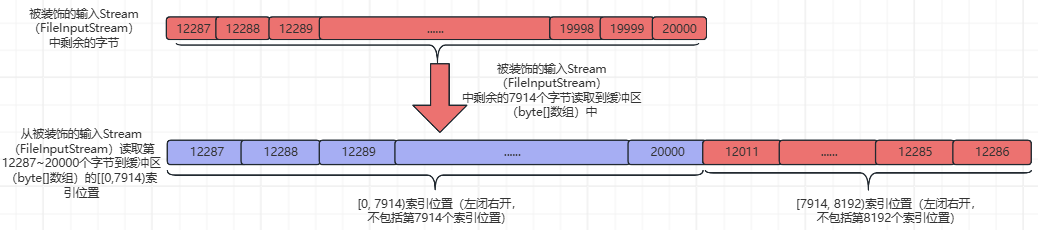
此时,被装饰的输入Stream(FileInputStream)中的字节被全部读取完毕,被装饰的输入Stream(FileInputStream)为空。
②、更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为7914,count=7914+0=7914;
③、执行getBufIfOpen()[pos++] & 0xff,从缓冲区(byte[]数组)中获取第pos(此时pos=0)个索引位置的字节,返回给BufferedInputStream.class::read()函数的调用方,并更新pos的值为pos+=1;
之后,每次调用BufferedInputStream.class::read()函数时,都不会再执行fill()函数了,直到pos=7914时,执行BufferedInputStream.class::read()函数才会再次执行fill()函数,过程如下:
①、因为markpos = -1,所以更新pos=0,count=0,缓冲区(byte[]数组)中的数据如下:

此时,由于被装饰的输入Stream(FileInputStream)中的字节被全部读取完毕,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为0,无法更新count,结束fill()函数的调用
②、执行return -1,返回给BufferedInputStream.class::read()函数的调用方;
- 情景二,改变上面的伪代码bis.mark(8192),而是设置marklimit>缓冲区(byte[]数组)的长度(只要是大于8192的任何值都可以),比如bis.mark(16384)
①、执行fill()函数的如下代码片段,
...省略部分代码...
} else {//场景四:pos>=缓冲区(byte[]数组)的长度并且不满足场景一、二、三时,将缓冲区(byte[]数组)扩容
//如果pos<2147483639/2,则新缓冲区(byte[]数组)的长度nsz=pos*2,否则新缓冲区(byte[]数组)的长度nsz=2147483639
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;//当新缓冲区(byte[]数组)的长度nsz>marklimit,新缓冲区(byte[]数组)的长度nsz=marklimit
byte nbuf[] = new byte[nsz];//新建一个新缓冲区(byte[]数组)
System.arraycopy(buffer, 0, nbuf, 0, pos);//将老缓冲区(byte[]数组)中[0,pos)索引区间的元素复制到新缓冲区(byte[]数组)[0,pos)索引区间
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {//通过CAS(Compare-And-Swap)操作来原子地更新buf变量
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;//新缓冲区(byte[]数组)创建完毕
}
...省略部分代码...
先扩大缓冲区(byte[]数组)的长度到16384(扩大前缓冲区长度为8192),然后将旧缓冲区(byte[]数组)中的内容移动到新缓冲区(byte[]数组)对应的索引位置上,如下所示:
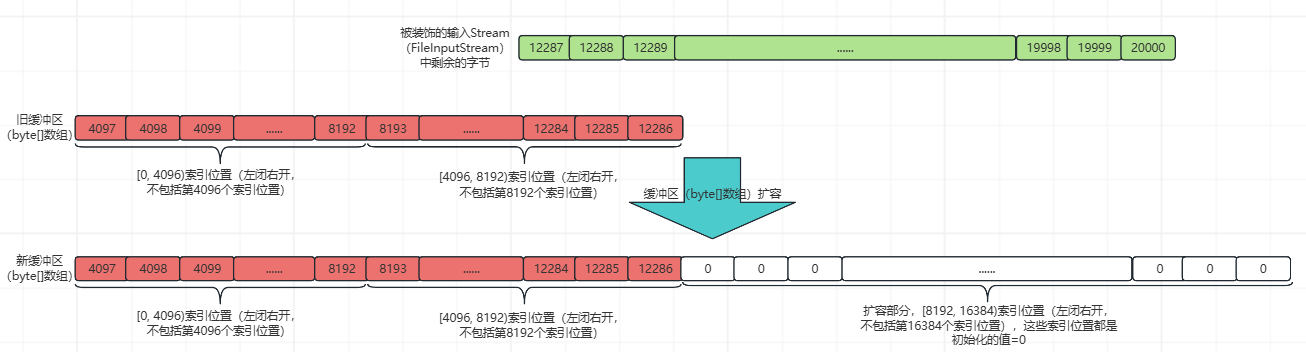
然后通过CAS(Compare-And-Swap)操作来原子地更新buf变量的引用。
②、然后从被装饰的输入Stream(FileInputStream)读取第12287~20000个字节到新缓冲区(byte[]数组)的[8192,16106)索引位置(左闭右开,不包括新byte[]数组的第16106个索引位置),并返回读取的字节数量。如下所示:
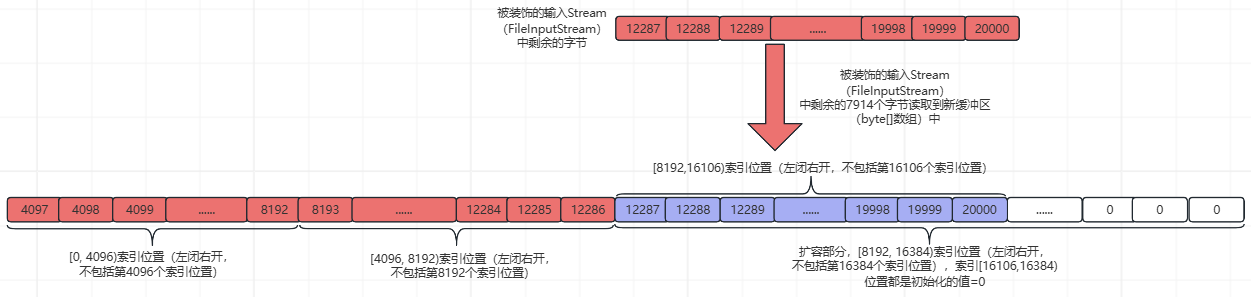
此时,被装饰的输入Stream(FileInputStream)中的字节被全部读取完毕,被装饰的输入Stream(FileInputStream)为空。
③、更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为7914,count=7914+pos=16106;
④、执行getBufIfOpen()[pos++] & 0xff,从缓冲区(byte[]数组)中获取第pos(此时pos=8192)个索引位置的字节,返回给BufferedInputStream.class::read()函数的调用方,并更新pos的值为pos+=1;
之后,每次调用BufferedInputStream.class::read()函数时,都不会再执行fill()函数了,直到pos=16106时,执行BufferedInputStream.class::read()函数才会再次执行fill()函数,过程如下:
①、因为markpos = 0,不会设置pos=0,也不会再执行场景一、场景二、场景三、场景四(标题三源码中的注释)、新缓冲区(byte[]数组)中的数据如下:

此时,由于被装饰的输入Stream(FileInputStream)中的字节被全部读取完毕,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为0,无法更新count变量,结束fill()函数的调用
②、执行return -1,返回给BufferedInputStream.class::read()函数的调用方;
3.1.3、如果在多次执行BufferedInputStream.class::read()函数之后执行过mark()函数
如果在很多次调用read()函数之中调用了mark(8192)函数,如下(伪代码):
InputStream is = new FileInputStream("D:\\nio-data.txt");
BufferedInputStream bis = new BufferedInputStream(is);
int bytesRead;
while ((bytesRead = bis.read()) != -1) {
//处理读取到的字节bytesRead
}
bis.mark(8192);//设置marklimit=8192,markpos=pos=0
那么,BufferedInputStream对象中的缓冲区(byte[]数组)的长度为8192(缓存8KB字节),上述代码的执行过程如下(假设被装饰的输入Stream(FileInputStream)中有10000个字节):
参考标题3.1,与标题3.1不同的是,最后执行bis.mark(8192);,设置marklimit=8192,markpos=pos=0。
3.1.4、如果在多次执行BufferedInputStream.class::read()函数之中执行过mark()函数和reset()函数
如果在很多次调用read()函数之中调用了mark(8192)函数,然后又调用了reset()函数,如下(伪代码):
InputStream is = new FileInputStream("D:\\nio-data.txt");//假设该被装饰的输入Stream(FileInputStream)中有20000个字节
BufferedInputStream bis = new BufferedInputStream(is);
int bytesRead;
int i = 0;
while ((bytesRead = bis.read()) != -1) {
if(++i==4096){
bis.mark(8192);//设置marklimit=8192,markpos=pos=4096
}
//处理读取到的字节bytesRead
if(i==8196){
bis.reset();//当pos=8196时,执行reset()函数,设置pos=markpos=0
}
}
那么,BufferedInputStream对象中的缓冲区(byte[]数组)的长度为8192(缓存8KB字节),上述代码的执行过程如下(假设被装饰的输入Stream(FileInputStream)中有20000个字节):
①、pos=count=0,缓冲区(byte[]数组)中还没有填充任何数据,执行fill()函数,然后将被装饰的输入Stream(FileInputStream)中的字节读取到缓冲区(byte[]数组)的[0,8192)索引位置(左闭右开,不包括byte[]数组的第8192个索引位置),并返回读取的字节数量。如下所示:

此时,被装饰的输入Stream(FileInputStream)中的字节和缓冲区(byte[]数组)中的字节,如下所示:

②、更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为8192,count=8192+pos=8192;
③、执行getBufIfOpen()[pos++] & 0xff,从缓冲区(byte[]数组)中获取第pos(此时pos=0)个索引位置的字节,返回给BufferedInputStream.class::read()函数的调用方,并更新pos的值为pos+=1;
之后,while循环中每次调用BufferedInputStream.class::read()函数时,都不会再执行fill()函数了,并且当pos=4096时,执行了bis.mark(8192),设置marklimit=8192,markpos=pos=4096。
直到pos=8192时,先执行伪代码中的BufferedInputStream.class::reset()函数,如下所示:
package java.io;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;
public
class BufferedInputStream extends FilterInputStream {
...省略部分代码...
//线程同步的函数:pos = markpos(或者叫对齐pos索引位置 到markpos索引位置)
public synchronized void reset() throws IOException {
getBufIfOpen(); //检测被装饰的输入Stream是否关闭
if (markpos < 0)
throw new IOException("Resetting to invalid mark");
pos = markpos;
}
...省略部分代码...
}
reset()函数会设置pos=markpos=4096,之后,伪代码的while循环中每次调用BufferedInputStream.class::read()函数时,会将缓冲区(byte[]数组)中第[4096,8192)索引区间的元素再返回一次,并更新pos的值为pos+=1。直到pos=8192时,执行BufferedInputStream.class::read()函数才会再次执行fill()函数,本次填充缓冲区(byte[]数组)的过程如下:
参考标题3.1.2中的第2个序号①和之后的内容;
3.1.5、BufferedInputStream使用时的注意事项
BufferedInputStream中的缓冲区(byte[]数组)如果太小的话(比如长度为12),在执行read()函数时,会被从被装饰的输入Stream(假设总共有26个字节)中读取的新字节覆盖掉,即使在读取过程中执行过mark()函数(比如,执行该函数时,pos=6,那么markpos=6),也只会把本次(第1次填充缓冲区)[markpos,buf.length)索引之间的(左闭右开,实际是[6,12))字节复制到第2次填充的缓冲区(byte[]数组)的[0,6)(左闭右开)索引之间,等到第3次填充缓冲区时,第1次缓冲区中[6,12)索引之间的数据然后被复制到第2次缓冲区(byte[]数组)的[0,6)(左闭右开)索引之间的的数据,仍然会被第3次填充缓冲区时覆盖掉。因此,使用BufferedInputStream需要注意以下2点:
①、设置的缓冲区(byte[]数组)大小(默认为8192 ,8KB)尽量大于被装饰的输入Stream中的数据总量;
②、不建议在多线程中使用BufferedInputStream;
下面这个例子就恰当的使用BufferedInputStream的read()函数、mark()函数、reset()函数:
-
我的windows操作系统的D盘根目录下有nio-data.txt文件,该文件中总共有31个字节,如下所示:
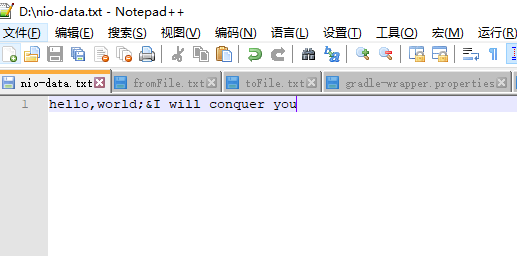
-
当第一次读取完这个文件中的内容后,该文件中“&”这个字节之后的内容,需要重新读取一次,如下代码所示:
package com.chelong.StreamAndReader;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class BufferedInputStreamTest {
public static void main(String[] args) {
InputStream is = null;
BufferedInputStream bis = null;
try {
is = new FileInputStream("D:\\nio-data.txt");//被装饰的输入Stream,总共有31个字节(byte)数据
bis = new BufferedInputStream(is, 64);//缓冲区(byte[]数组)的长度为64
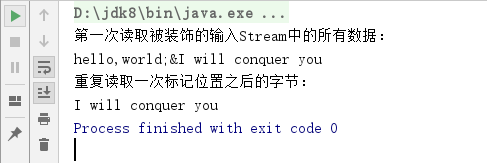
System.out.println("第一次读取被装饰的输入Stream中的所有数据:");
int bytesRead;
while ((bytesRead = bis.read()) != -1) {
if (bytesRead == '&') {
bis.mark(64);//当读取到“&”这个字节后,使用mark()函数做一个标记
}
System.out.print((char) bytesRead);
}
System.out.println();
System.out.println("重复读取一次标记位置之后的字节:");
bis.reset();//第一次读取完被装饰的输入Stream中的所有数据后,执行reset()函数
while ((bytesRead = bis.read()) != -1) {//从被标记的位置再读取一次
System.out.print((char) bytesRead);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (is != null) is.close();
if (bis != null) bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
程序运行结果,如下所示:
3.2、BufferedInputStream的read(byte b[], int off, int len)函数和fill()函数
public
class BufferedInputStream extends FilterInputStream {
...省略部分代码...
// 默认缓冲区(byte[]数组)大小为8192 字节(8KB)
private static int DEFAULT_BUFFER_SIZE = 8192;
// 最大缓冲区(byte[]数组)大小为2147483639byte,大约2GB左右
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
//缓冲区数组,用volatile修饰是为了通过AtomicReferenceFieldUpdater进行CAS更新时保证内存的可见性
protected volatile byte buf[];
//底层是通过反射找到目标字段的内存偏移量,然后利用Unsafe.class提供的CAS(Compare-And-Swap)操作来原子地更新某个类中指定变量的值
private static final
AtomicReferenceFieldUpdater bufUpdater =
AtomicReferenceFieldUpdater.newUpdater
(BufferedInputStream.class, byte[].class, "buf");
//缓冲区(byte[]数组)中有效字的节数数量
protected int count;
//准备从缓冲区中(byte[]数组)读取的字节索引位置,取值范围为0<=pos<=count
protected int pos;
//在缓冲区(byte[]数组)中标记的某个索引位置,-1<=markpos<=pos
//该变量只会在 fill()函数和mark()函数中赋值
protected int markpos = -1;
// 标记后最多可读取字节数量,该变量只会在 mark()函数中赋值
//每当pos-markpos>marklimit时,就会设置markpos=-1 来删除标记
protected int marklimit;
//如果被装饰的输入流不为空,则返回被装饰的输入Stream(该变量在FilterInputStream中定义)
private InputStream getInIfOpen() throws IOException {
InputStream input = in;
if (input == null)
throw new IOException("Stream closed");
return input;
}
//如果缓冲区(byte[]数组)不为空,则返回该缓冲区(byte[]数组),否则抛出异常
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
}
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();//获取缓冲区(byte[]数组)
if (markpos < 0)//如果还没有调用过mark()函数,那么markpos=-1
pos = 0;//pos=0,可以从缓冲区(byte[]数组)的索引0的位置开始读字节了
else if (pos >= buffer.length)
if (markpos > 0) { //场景一:pos>=缓冲区(byte[]数组)的长度并且markpos >0
int sz = pos - markpos;
//只把缓冲区(byte[]数组)中[markpos,pos) 索引区间的元素复制到缓冲区(byte[]数组)[0,pos-markpos)索引区间
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;//设置pos=pos-markpos
markpos = 0;//设置markpos=0
} else if (buffer.length >= marklimit) {//场景二:pos>=缓冲区(byte[]数组)的长度并且缓冲区(byte[]数组)的长度>= marklimit
markpos = -1; //设置markpos = -1
pos = 0; //设置pos = 0
} else if (buffer.length >= MAX_BUFFER_SIZE) {//场景三:pos>=缓冲区(byte[]数组)的长度并且缓冲区(byte[]数组)的长度 >= 2147483639
throw new OutOfMemoryError("Required array size too large");
} else {//场景四:pos>=缓冲区(byte[]数组)的长度并且不满足场景一、二、三时,将缓冲区(byte[]数组)扩容
//如果pos<2147483639/2,则新缓冲区(byte[]数组)的长度nsz=pos*2,否则新缓冲区(byte[]数组)的长度nsz=2147483639
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;//当新缓冲区(byte[]数组)的长度nsz>marklimit,新缓冲区(byte[]数组)的长度nsz=marklimit
byte nbuf[] = new byte[nsz];//新建一个新缓冲区(byte[]数组)
System.arraycopy(buffer, 0, nbuf, 0, pos);//将老缓冲区(byte[]数组)中[0,pos)索引区间的元素复制到新缓冲区(byte[]数组)[0,pos)索引区间
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {//通过CAS(Compare-And-Swap)操作来原子地更新buf变量
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;//新缓冲区(byte[]数组)创建完毕
}
count = pos;
//将被装饰的输入Stream中的字节读取到缓冲区(byte[]数组)的[pos,buffer.length - pos)索引位置,并返回读取的字节数量
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;//count=从被装饰的输入Stream中读取的字节数量+pos
}
//从缓冲区(byte[]数组)或被装饰的输入Stream中读取len个字节到指定的byte[]数组b中,这len个字节被放到byte[]数组b的[off,off+len)索引位置。
//该函数只被read()函数调用
private int read1(byte[] b, int off, int len) throws IOException {
//只在fill()函数中修改count变量的值,count变量的值只有以下2种可能
//①、count==pos;②、count=从被装饰的输入Stream中读取的字节数量+pos
//因此avail表示缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量
int avail = count - pos;
if (avail <= 0) {//缓冲区(byte[]数组)中[pos,pos+count)索引位置的字节数量<=0(其实不可能<0,只可能=0)
//要读取的len个字节>=缓冲区(byte[]数组)的长度,同时markpos = -1
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);//从被装饰的输入Stream中读取len个字节到指定的byte[]数组b中,这len个字节被放到byte[]数组b的[off,off+len)索引位置。
}
fill();//调用fill()函数
avail = count - pos;//重新计算avail
if (avail <= 0) return -1;//如果avail仍然=0,返回-1
}
int cnt = (avail < len) ? avail : len;//此时avail>0,取avail和len中较小的值作为本次从缓冲区(byte[]数组)中读取的字节数量
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);//从缓冲区(byte[]数组)的pos索引开始,读取avail或len(2者取其小)个字节到指定的byte[]数组b的[off,off+cnt)索引位置(cnt就是avail或len中2者取其小的值)
pos += cnt;//pos向前移动avail或len(2者取其小)个索引位置
return cnt;//返回avail或len(2者取其小)
}
//线程同步的函数:从缓冲区(byte[]数组)中读取len个字节到指定的byte[]数组b中,这len个字节被放到byte[]数组b的[off,off+len)索引位置。
public synchronized int read(byte b[], int off, int len)
throws IOException
{
getBufIfOpen(); //检测被装饰的输入Stream是否关闭
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {//相当于off + len > b.length(源码中这样写代码的好处我没看出来)
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;//要从缓冲区(byte[]数组)中读取的len个字节==0时,返回0
}
int n = 0;//累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量
for (;;) {//循环调用read1()函数完成从缓冲区(byte[]数组)或被装饰的输入Stream中读取len个字节到指定的byte[]数组b中,这len个字节被放到byte[]数组b的[off,off+len)索引位置。
int nread = read1(b, off + n, len - n);//nread用来统计每次从read1()函数中读取一定的字节数量,并放到byte[]数组b的[off,off+len)索引位置。
if (nread <= 0)//当read1()函数返回0或者-1时,表示缓冲区(byte[]数组)中和被装饰的输入Stream中已经没有可以读取的字节了
return (n == 0) ? nread : n;//返回累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量或者-1
n += nread;//累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量
if (n >= len)//累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量总和>=len时(其实不可能>len,只可能=len)
return n;//返回n
// 被装饰的输入Stream中已经没有字节可以用了,返回累计从缓冲区(byte[]数组)或被装饰的输入Stream中读取的字节数量总和
InputStream input = in;
if (input != null && input.available() <= 0)
return n;
}
}
...省略部分代码...
}
如果使用者用的是默认的构造函数创建了BufferedInputStream的对象,如下所示(伪代码):
InputStream is = new FileInputStream("D:\\nio-data.txt");
BufferedInputStream bis = new BufferedInputStream(is);
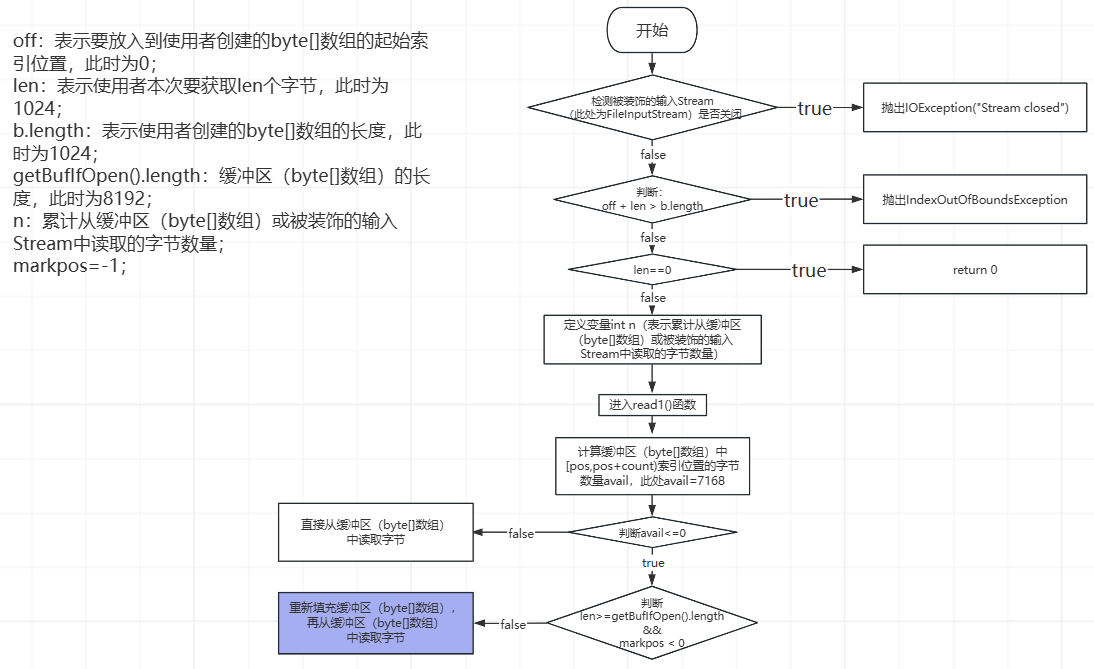
那么,BufferedInputStream对象中的缓冲区(byte[]数组)的长度为8192(缓存8KB字节),接下来使用BufferedInputStream对象读取字节数据到使用者创建的byte[]数组中的过程,分为以下3种情景:
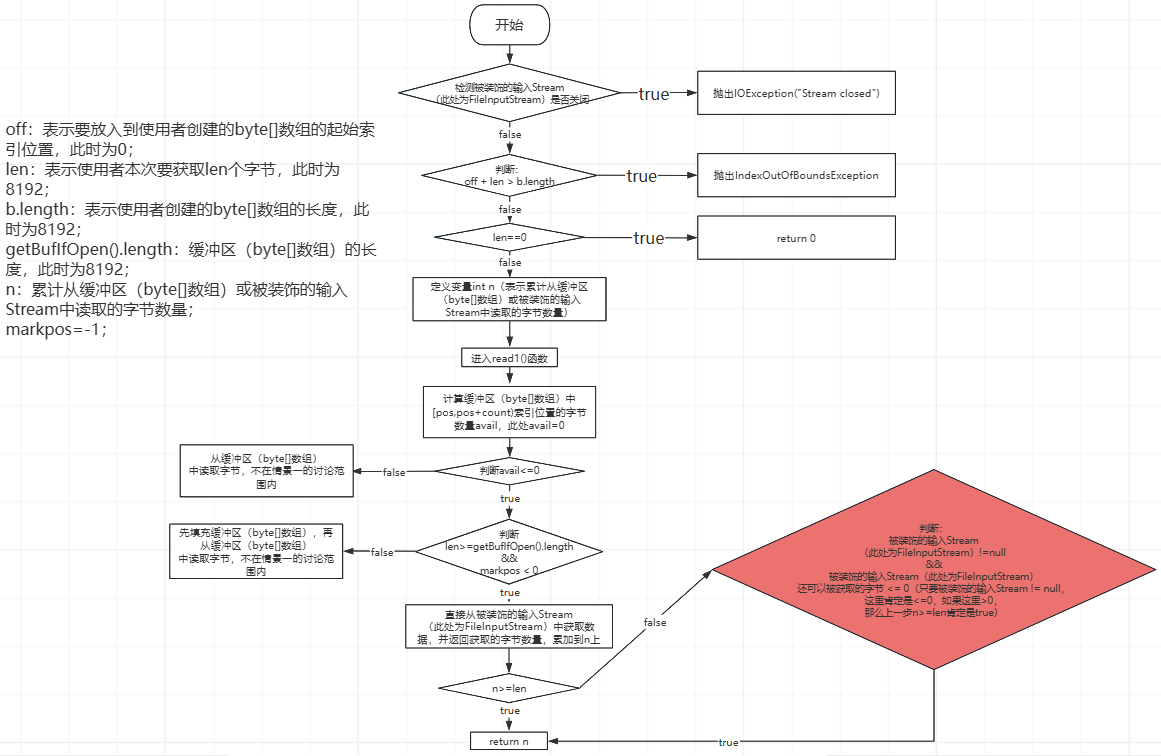
- 情景一,使用者创建的byte[]数组的长度>=缓冲区(byte[]数组)的长度,比如,此处使用者创建的byte[]数组的长度为8192,如下所示(伪代码):
byte[] buffer = new byte[8192];
bis.read(buffer,0,buffer.length);
整个执行过程如下(直接从被装饰的输入Stream中获取字节,不会使用缓冲区):
- 情景二,使用者创建的byte[]数组的长度<缓冲区(byte[]数组)的长度,比如,此处使用者创建的byte[]数组的长度为1024,如下所示(伪代码):
byte[] buffer = new byte[1024];
bis.read(buffer,0,buffer.length);
过程如下(假设被装饰的输入Stream(FileInputStream)中有10000个字节):
①、先执行到下图中的紫色部分,如下所示:
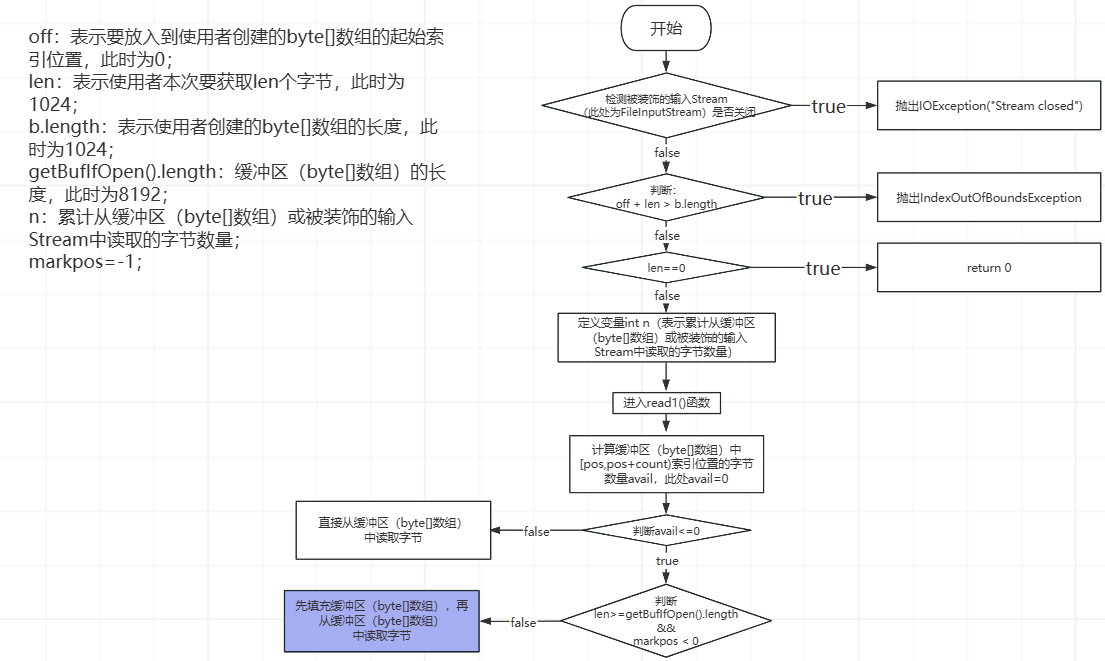
②、pos=count=0,缓冲区(byte[]数组)中还没有填充任何数据,执行fill()函数,然后将被装饰的输入Stream(FileInputStream)中的字节读取到缓冲区(byte[]数组)的[0,8192)索引位置(左闭右开,不包括byte[]数组的第8192个索引位置),并返回读取的字节数量。如下所示:
此时,被装饰的输入Stream(FileInputStream)中的字节和缓冲区(byte[]数组)中的字节,如下所示:
③、更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为8192,count=8192+pos=8192;
④、从缓冲区(byte[]数组)的pos索引(此时,pos=0)开始,读取1024个字节到使用者创建的byte[]数组的[0,1024)索引位置(左闭右开,不包括第1024个索引位置),并更新pos=1024,read1()函数返回1024,如下所示:
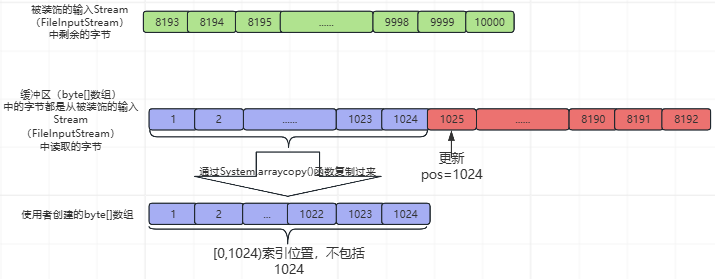
⑤、再执行下图中的紫色部分之后的流程,如下所示:

- 情景三,使用者创建的byte[]数组的长度<缓冲区(byte[]数组)的长度,比如,此处使用者创建的byte[]数组的长度为1024,但是使用者是在while循环中使用read(byte b[], int off, int len)函数,直到read(byte b[], int off, int len)函数返回-1,如下所示(伪代码):
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = bis.read(buffer,0,buffer.length)) != -1) {
for (int i = 0; i < bytesRead; i++) {
//处理读取到的字节buffer[i]
}
}
过程如下(假设被装饰的输入Stream(FileInputStream)中有10000个字节):
①、第1次while循环,先执行到下图中的紫色部分,如下所示:
此时,pos=count=0,缓冲区(byte[]数组)中还没有填充任何数据,执行fill()函数,然后将被装饰的输入Stream(FileInputStream)中的字节读取到缓冲区(byte[]数组)的[0,8192)索引位置(左闭右开,不包括byte[]数组的第8192个索引位置),并返回读取的字节数量。如下所示:
此时,被装饰的输入Stream(FileInputStream)中的字节和缓冲区(byte[]数组)中的字节,如下所示:
接着更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为8192,count=8192+pos=8192;
然后,从缓冲区(byte[]数组)的pos索引(此时,pos=0)开始,读取1024个字节到使用者创建的byte[]数组的[0,1024)索引位置(左闭右开,不包括第1024个索引位置),并更新pos=1024,read1()函数返回1024,如下所示:
最后,再执行下图中的紫色部分之后的流程,如下所示:
②、第2次while循环,先执行到下图中的黄色部分,如下所示:
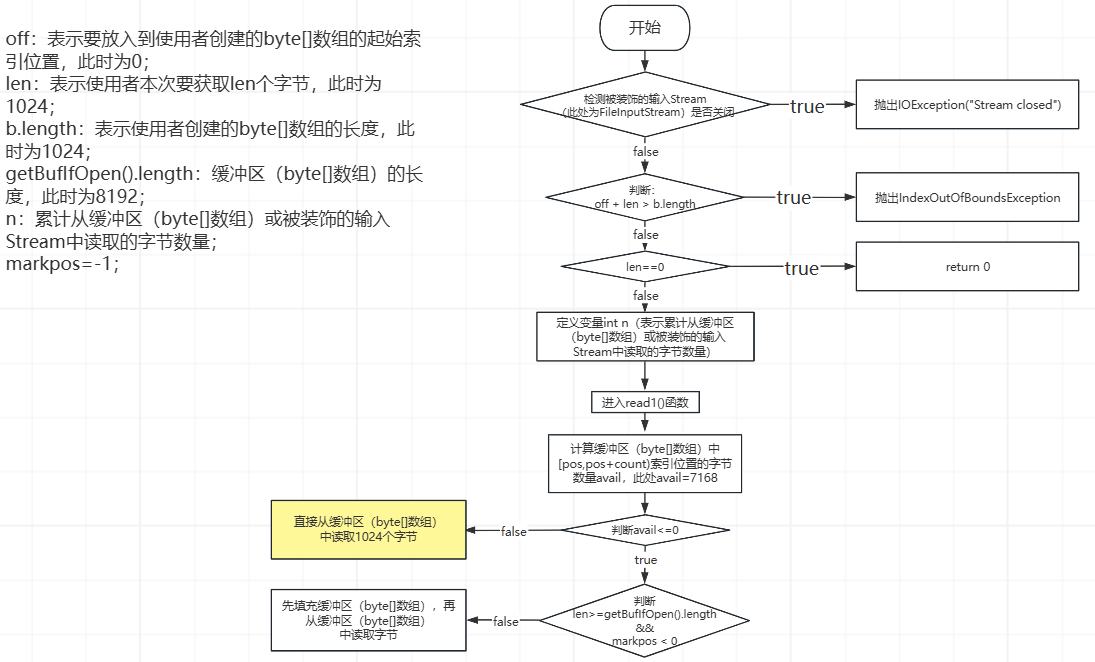
此时,pos=1024,count=8192,从缓冲区(byte[]数组)中读取1024个字节之后,此时,被装饰的输入Stream(FileInputStream)中的字节、缓冲区(byte[]数组)中的字节、和使用者创建的byte[]数组中的数据,如下所示:
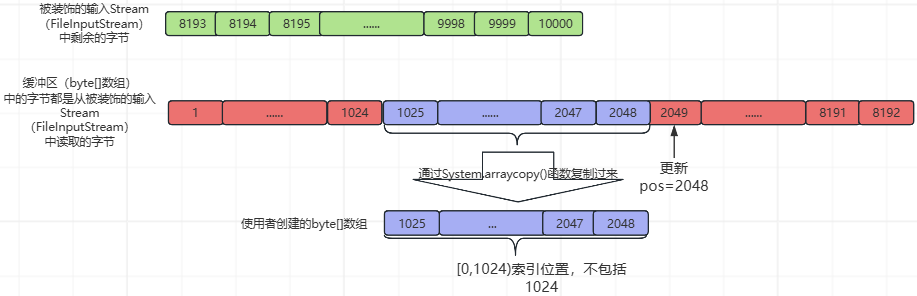
然后更新pos=2048,read1()函数返回1024,最后,再执行下图中的黄色部分之后的流程,如下所示:

③、第3次while循环,先执行到下图中的黄色部分,如下所示:
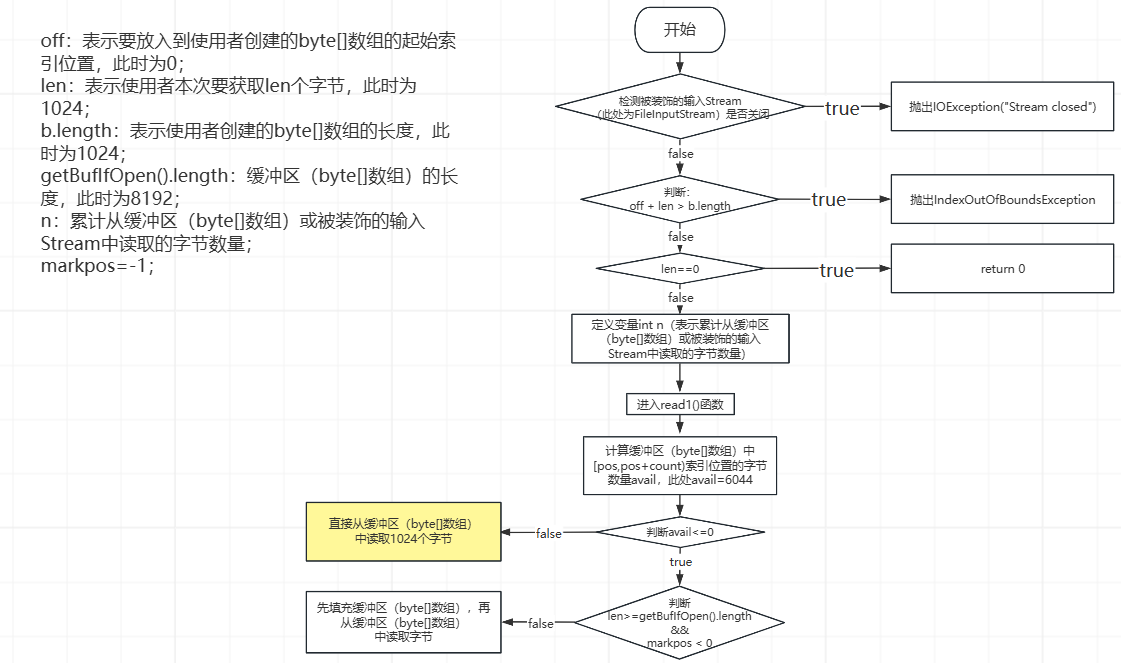
此时,pos=2048,count=8192,从缓冲区(byte[]数组)中读取1024个字节之后,此时,被装饰的输入Stream(FileInputStream)中的字节、缓冲区(byte[]数组)中的字节、和使用者创建的byte[]数组中的数据,如下所示:
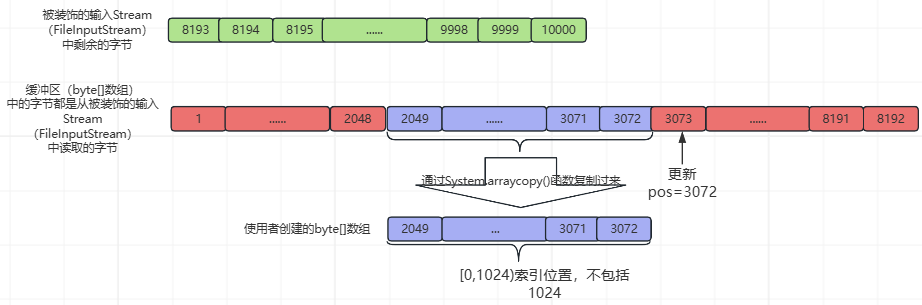
然后更新pos=3072,read1()函数返回1024,最后,再执行下图中的黄色部分之后的流程,如下所示:
④、第4次while循环,基本流程与②、③相同,不同处如下所示(pos=40969和使用者创建的byte[]数组中的数据):
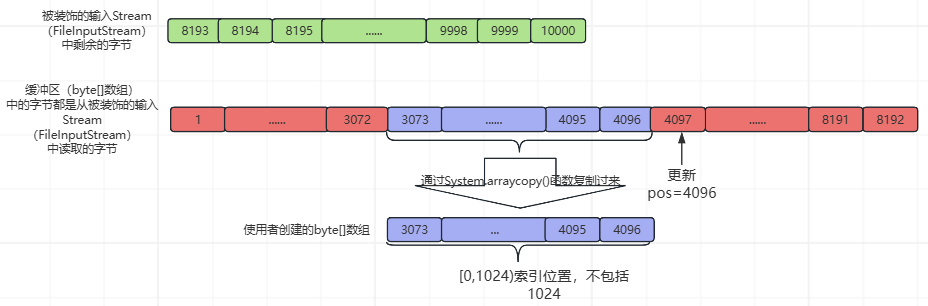
⑤、第5次while循环,基本流程与②、③、④相同,不同处如下所示(pos=5120和使用者创建的byte[]数组中的数据):
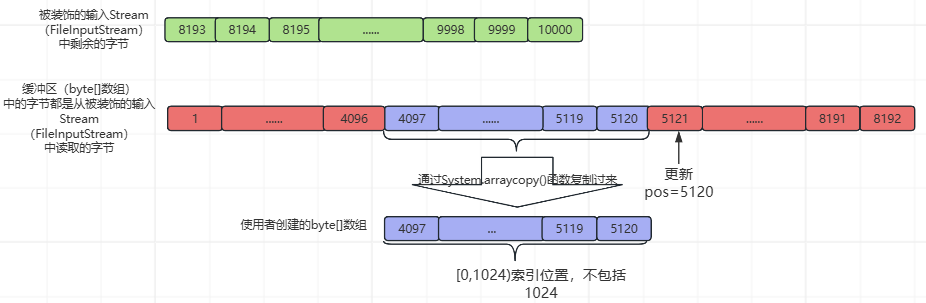
⑥、第6次while循环,基本流程与②、③、④、⑤相同,不同处如下所示(pos=6144和使用者创建的byte[]数组中的数据):
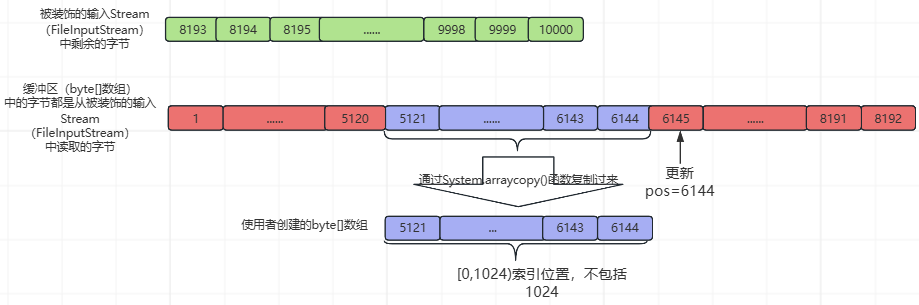
⑦、第7次while循环,基本流程与②、③、④、⑤、⑥相同,不同处如下所示(pos=7168和使用者创建的byte[]数组中的数据):
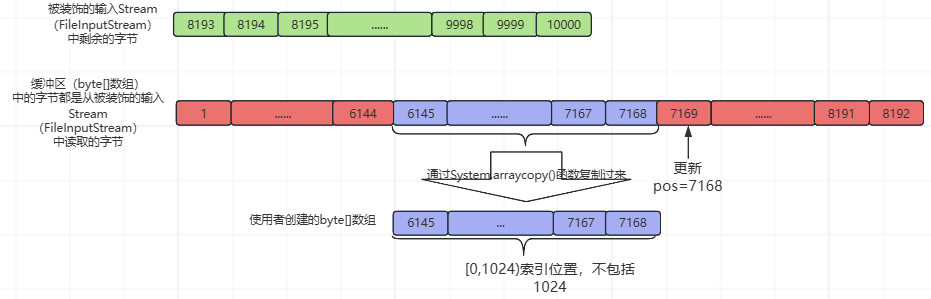
⑧、第8次while循环,基本流程与②、③、④、⑤、⑥、⑦相同,不同处如下所示(pos=8192和使用者创建的byte[]数组中的数据):
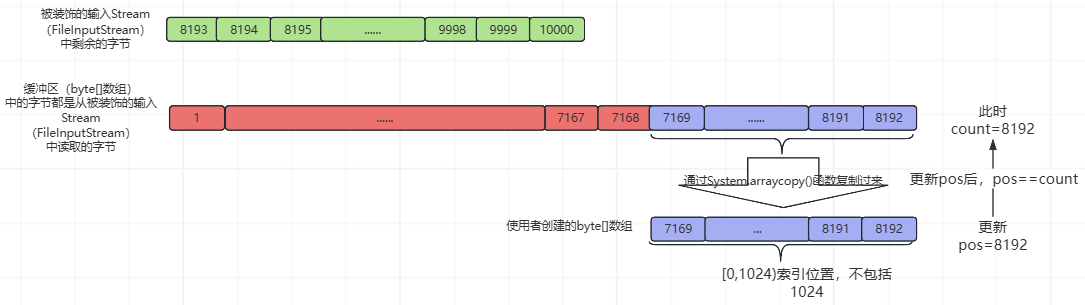
⑨、第9次while循环,先执行到下图中的紫色部分,如下所示:
此时,先在fill()函数中更新pos=0,缓冲区(byte[]数组)中是上一次执行fill()函数填充的从被装饰的输入Stream(FileInputStream)读取的第18192个字节,本次,需要将被装饰的输入Stream(FileInputStream)中的第819310000个字节读取到缓冲区(byte[]数组)的[0,1808)索引位置(左闭右开,不包括byte[]数组的第1808个索引位置),并返回读取的字节数量。如下所示
此时,被装饰的输入Stream(FileInputStream)中的字节被全部读取完毕,被装饰的输入Stream(FileInputStream)为空。
然后,更新int count变量,fill()函数中getInIfOpen().read(buffer, pos, buffer.length - pos)这行代码的返回值为1808,count=1808+pos=1808;
然后,从缓冲区(byte[]数组)的pos索引(此时,pos=0)开始,读取1024个字节到使用者创建的byte[]数组的[0,1024)索引位置(左闭右开,不包括第1024个索引位置),并更新pos=1024,read1()函数返回1024,如下所示:
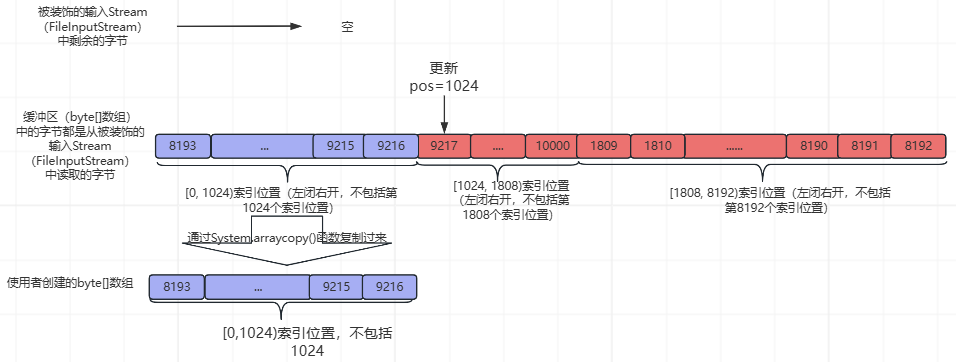
最后,再执行下图中的紫色部分之后的流程,如下所示:
⑩、第10次while循环,先执行到下图中的黄色部分,如下所示:
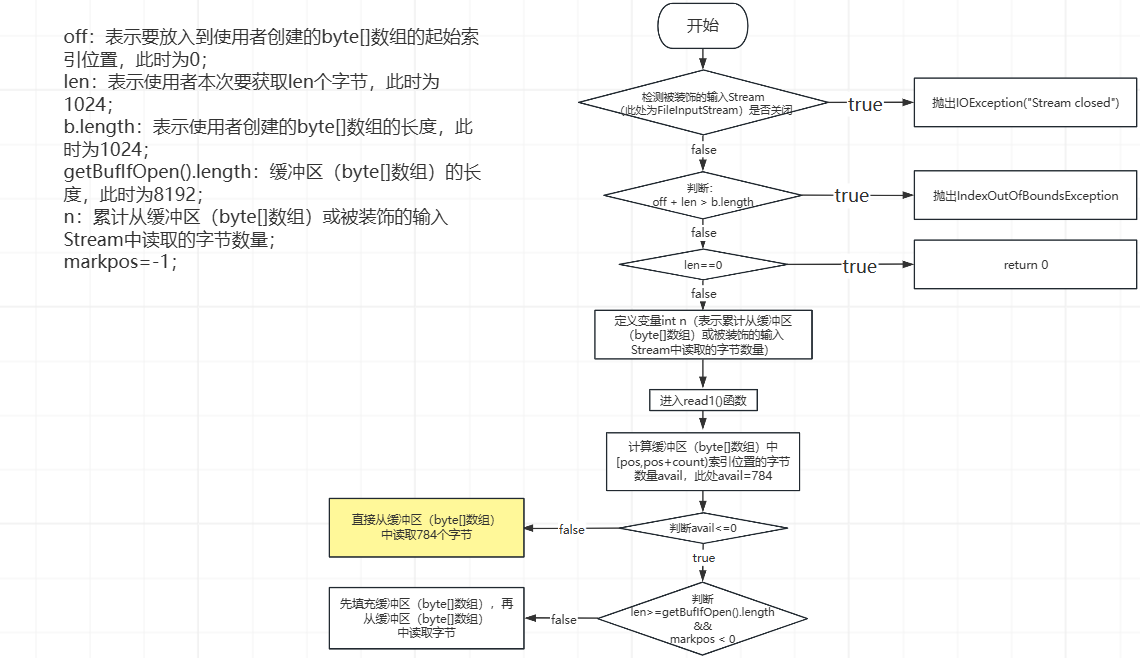
此时,pos=1024,count=1808,从缓冲区(byte[]数组)中读取784个字节之后,此时,被装饰的输入Stream(FileInputStream)中的字节、缓冲区(byte[]数组)中的字节、和使用者创建的byte[]数组中的数据,如下所示:
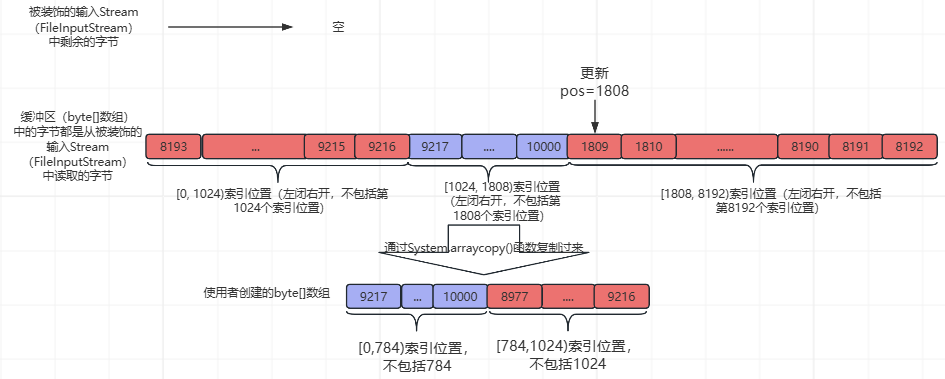
然后更新pos=1808,read1()函数返回784,最后,再执行下图中的黄色部分之后的流程,如下所示:

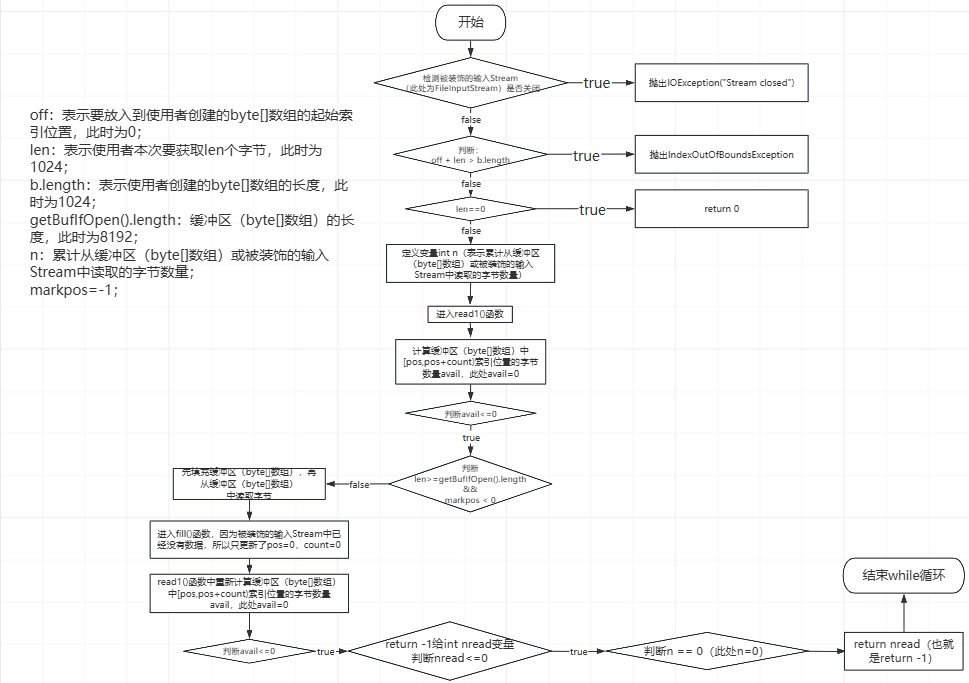
⑪、第11次while循环,流程如下所示(最终bis.read(buffer,0,buffer.length)由于的返回值为-1,所以结束了循环):
原文地址: https://www.cveoy.top/t/topic/qFXO 著作权归作者所有。请勿转载和采集!