OneTrans解读:统一序列建模与特征交互
OneTrans解读:统一序列建模与特征交互
一、问题背景:为什么要打破两段式 Pipeline
工业推荐系统的排序模型,长期以来沿用一种固定范式:先用序列模块(如 DIN、Transformer)对用户行为历史进行编码,得到压缩的用户兴趣表示;再将其与用户画像、物品特征、上下文特征拼接,送入特征交互模块(如 DCNv2、Wukong、RankMixer)完成高阶交叉。这一设计被称为 encode-then-interaction pipeline。
这种两段式范式存在两个根本性缺陷。其一是信息流的单向性:行为序列被压缩为固定向量之后,才与物品和上下文特征交互,这意味着物品特征无法在序列编码阶段对用户历史产生影响——candidate-aware 的信息无法逆向流入序列表示。其二是执行碎片化:两个模块独立计算,无法共享 KV Cache、FlashAttention 等 LLM 工程优化,导致在线延迟偏高、扩展困难。
OneTrans 提出了一个根本性的解决思路:将序列特征与非序列特征统一表示为 Token 序列,用同一个 Transformer Backbone 完成序列建模与特征交互的全部计算,从而打通双向信息流,并使整个模型能够直接复用 LLM 的训练与推理优化栈。
二、统一 Tokenization:将异构特征映射为 Token 序列
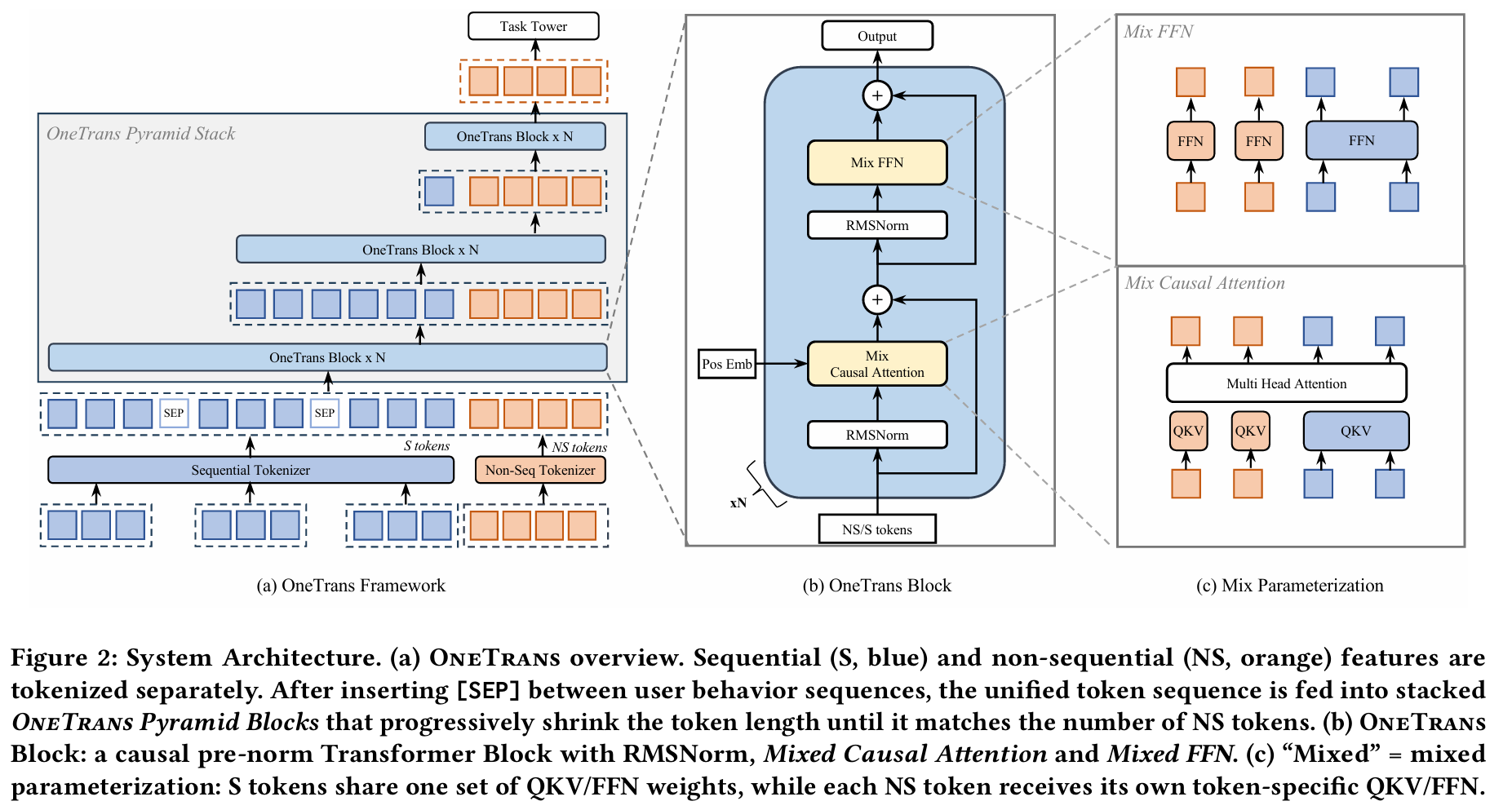
OneTrans 的第一步是通过 Tokenizer 将所有输入特征映射为统一维度 \(d\) 的 Token 序列。特征被分为两类:来自用户行为历史的序列特征(S-tokens),以及来自用户画像、物品属性、上下文信息的非序列特征(NS-tokens)。
序列特征的 Token 化
对于点击序列、购买序列等多路行为序列,每一个交互事件(event)由 item ID 与其 side information(如类目、价格)拼接后,通过共享 MLP 投影到统一维度 \(d\),得到对应的 S-token。多路行为序列的融合方式有两种:若时间戳可用,则按时间交织排列;若不可用,则按行为意图强度(purchase → add-to-cart → click)有序拼接,并在序列边界处插入可学习的 [SEP] token 以区分边界。消融实验表明,时间戳感知的融合方式优于意图排序方式,因此在特征可用时应优先选择。
最终得到的 S-tokens 表示为 \(\mathbf{X}_S \in \mathbb{R}^{L_S \times d}\),其中 \(L_S\) 为全部行为事件数量与 SEP token 数量之和。
非序列特征的 Token 化:两种方案的对比
非序列特征的 Token 化是 OneTrans 与前序工作(如 RankMixer)的重要区别之一。论文提出了两种方案:
Group-wise Tokenizer 按语义人工预先分组,例如将所有用户画像特征划为一组 \(g_1\),物品特征划为 \(g_2\),上下文特征划为 \(g_3\),统计特征划为 \(g_4\)。每组特征在组内拼接后通过各自独立的 MLP 投影为一个 \(d\) 维 Token:
这种方式语义清晰,但需要人工维护分组规则,且多个独立 MLP 会带来多次 GPU kernel 启动开销。
Auto-Split Tokenizer 则更加自动化:将所有非序列特征统一拼接为一个向量,通过一次 MLP 投影到 \(L_{NS} \times d\) 维空间,再按维度切分为 \(L_{NS}\) 个 Token:
以一个具体例子说明:假设所有非序列特征拼接后维度为 1000,预设 \(L_{NS} = 12\),每个 Token 维度 \(d = 80\),则 MLP 的输出维度为 \(12 \times 80 = 960\),随后按每 80 维切分为 12 个 Token。值得注意的是,\(L_{NS}\) 是一个人工设定的超参数,工业系统中通常取 8 至 32 之间。
Auto-Split 的优势在于只需一次稠密矩阵乘法,减少了 kernel 启动开销;更重要的是,MLP 的权重矩阵是 dense 的,每个输出维度可以感知全部输入特征,因此模型可以自动学习跨语义类别的特征组合,而不受人工分组的约束。消融实验证实,Auto-Split 在 CTR 和 CVR 指标上均优于 Group-wise 方案。
需要指出的是,Auto-Split 中一个特征的信息可能被分散到多个 Token 中——这并非设计缺陷,而是一种 distributed representation,类似于 NLP 中词向量的工作方式。后续 Transformer 层中的 token-level attention 能够重新整合这些分布式信息。
三、OneTrans Block:混合参数化的因果注意力
完成 Tokenization 后,所有 S-tokens 与 NS-tokens 拼接为统一序列 \(\mathbf{X}^{(0)} \in \mathbb{R}^{(L_S + L_{NS}) \times d}\),送入堆叠的 OneTrans Block 进行处理。每个 Block 遵循标准的 pre-norm Transformer 结构:
OneTrans Block 的核心创新称为混合参数化(Mixed Parameterization),其设计动机来自对推荐系统 Token 异构性的深刻认识。
混合参数化的 QKV 投影
对于第 \(i\) 个 Token,其 Q/K/V 的计算方式如下:
参数的分配遵循混合策略:
这一设计的理由非常直接。S-tokens 来自同质化的行为事件,其语义空间相似,共享参数不仅合理而且参数利用率更高;而 NS-tokens 分别来自用户画像、物品属性、上下文信息,语义空间差异显著,若强制共享参数,模型将无法区分这些 Token 的异质语义,导致表达能力下降。消融实验中,将所有 Token 强制共享参数会使模型参数量从 91M 降至 24M,同时带来明显的指标下滑。
以一个具体例子说明计算流程:假设 S-tokens 有 4 个,NS-tokens 有 5 个,embedding 维度为 \(d\)。S-tokens 共享参数计算得到 \(\mathbf{Q}_S \in \mathbb{R}^{4 \times d}\);5 个 NS-tokens 分别用各自的参数计算后,将结果拼接为 \(\mathbf{Q}_{NS} \in \mathbb{R}^{5 \times d}\)。两者沿序列维度拼接得到 \(\mathbf{Q} \in \mathbb{R}^{9 \times d}\),K 和 V 同理。随后计算 \(9 \times 9\) 的注意力矩阵,所有 Token 在同一个计算图中实现全局交互。反向传播时,各 NS-token 的参数矩阵 \(\mathbf{W}^Q_{NS,i}\) 独立更新,S-tokens 则共同更新共享参数 \(\mathbf{W}^Q_S\)。
因果掩码的信息流设计
OneTrans 采用统一的因果掩码,并将 NS-tokens 排列在序列尾部。这一排布使得信息流呈现出非对称结构:S-tokens 只能关注序列中位于其之前的 S-tokens,从而自然地实现时序序列建模;而 NS-tokens 则可以关注全部的 S-tokens 以及位于其之前的所有 NS-tokens,相当于在 Transformer 内部完成了一次完整的 Target Attention 聚合,将整个用户行为历史压缩进非序列特征表示中。
这一设计同时实现了四类交互:序列内部的时序建模、跨序列的行为关系学习、非序列特征之间的高阶交叉,以及序列与非序列特征之间的双向信息融合——这四类交互在传统 encode-then-interaction 范式中分属不同模块,而 OneTrans 在单一 Transformer 中一并完成。
四、Pyramid Stack:渐进式序列压缩
工业推荐场景中,用户行为序列长度可达数百乃至上千,标准 self-attention 的 \(O(L^2)\) 复杂度使得长序列计算成本极高。OneTrans 提出的 Pyramid Stack 策略利用因果注意力的内在信息流动规律,实现了在不丢失历史信息的前提下逐层压缩序列 Token 的目标。
其设计依据是:由于因果掩码使得第 \(i\) 个 Token 只能看到位置 \(j \leq i\) 的信息,序列越靠后的 Token 所携带的历史信息越丰富,尾部 Token 自然成为整个序列的"信息汇聚点"。
具体机制如下:在每一层 OneTrans Block 中,仅选取序列尾部的 \(L'\) 个 Token 参与 Query 计算,定义尾部索引集合 \(\mathcal{Q} = \{L - L' + 1, \ldots, L\}\),而 Key 和 Value 仍然在完整序列上计算:
注意力矩阵的维度因此从 \(L \times L\) 缩减为 \(L' \times L\),输出只保留 \(i \in \mathcal{Q}\) 的表示,序列长度压缩为 \(L'\),形成跨层的金字塔结构。
以 OneTransS 的实际配置为例:输入序列长度为 1190,经过 6 层 Block 后,序列 Query Token 数量线性递减,最终压缩至 12(与 NS-token 数量对齐),每层的 Token 数量约为 \(\{1190, 950, 710, 470, 230, 12\}\)(按 32 的倍数取整)。
这一设计带来两项核心收益。一方面,注意力复杂度由 \(O(L^2 d)\) 降为 \(O(L L' d)\),FFN 计算量也随 \(L'\) 线性下降。实验显示,Pyramid Stack 相比未压缩的全长序列方案,训练时间减少约 28.7%,显存占用减少约 42.6%,且在相同 FLOPs 预算下可支持约 1.75 倍的序列长度。另一方面,序列信息通过逐层 attention 聚合被渐进式地蒸馏至尾部 Token,最终在顶层自然地流入 NS-tokens,实现了长序列行为信息向非序列特征表示的信息迁移。
需要特别指出的是,Pyramid Stack 并非简单地丢弃历史 Token,而是在每一层的 attention 计算中保持完整的 Key/Value,确保尾部 Query Token 始终能够访问全部历史信息。因此,信息压缩是通过注意力加权聚合实现的,而非截断。
五、训练与部署优化
OneTrans 的统一 Backbone 设计使其能够直接复用 LLM 的工程优化栈。论文中报告了以下几项关键优化的效果:
Cross-Request KV Caching 利用工业推荐场景中同一次请求内所有候选物品共享相同 S-tokens 的结构特点,将 S-side 的 Key/Value 在请求级别缓存并复用,每位候选物品只需计算 NS-side 的增量。这将同一 session 中 \(C\) 个候选物品的 S-side 时间复杂度从 \(O(C)\) 降至 \(O(1)\),实验中可减少约 30% 的训练时间和 29.6% 的推理延迟。进一步地,由于用户行为序列为 append-only 结构,OneTrans 还支持跨请求的 KV Cache 复用,将每次请求的序列计算复杂度从 \(O(L)\) 降为 \(O(\Delta L)\)。
在系统层面,FlashAttention-2、BF16 混合精度训练以及 Activation Recomputation 的组合应用使得 OneTransL(330M 参数,8.62 TFLOPs)在线上的 p99 推理延迟(13.2ms)甚至略低于参数量仅为其 1/33 的 DCNv2+DIN 基线(13.6ms),证明了统一 Backbone 在工程优化方面的显著优势。
六、总结
OneTrans 的核心贡献在于从架构层面消除了序列建模与特征交互之间的模块壁垒。其技术路线可以归纳为三个层次的统一:第一是表示的统一,通过 Tokenization 将异构特征映射为同一空间的 Token 序列;第二是计算的统一,通过混合参数化的因果 Transformer 在单一计算图中完成所有类型的特征交互;第三是优化的统一,通过 Pyramid Stack 和 KV Cache 等机制使整个系统能够以 LLM 工程实践为基础进行训练和部署。
在大规模工业数据集上,OneTrans 展现出接近对数线性的 Scaling Law,并在线上 A/B 测试中相较强基线(RankMixer+Transformer)取得了 +5.68% per-user GMV 的显著提升。这一结果表明,推荐系统的扩展瓶颈不仅在于模型容量,更在于信息流动的架构设计——而打通序列与特征之间的双向信息通道,正是 OneTrans 为这一问题给出的核心答案。
原文地址: https://www.cveoy.top/t/topic/qF9R 著作权归作者所有。请勿转载和采集!